






一、数据库的创建、查看、删除
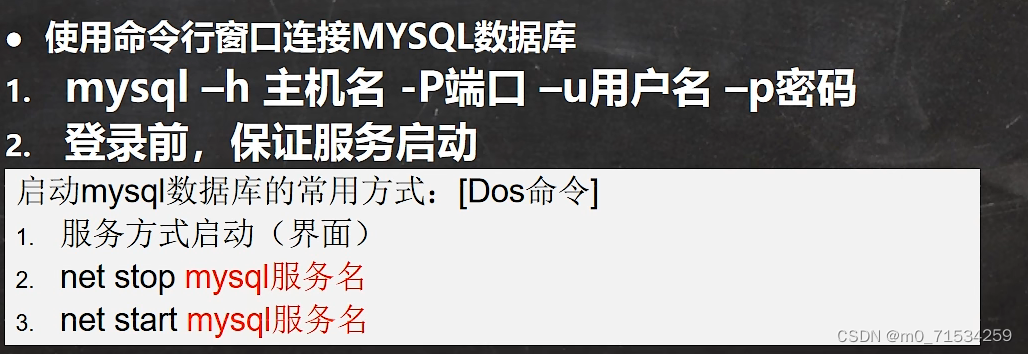
MySQL的服务名是mysql80
1、创建

#创建一个名称为db01的数据库。[图形化和指令演示]
#使用指令创建数据库
CREATE DATABASE db01;
#删除数据库指令
DROP DATABASE db01;
#创建一个使用utf8字符集的db02数据库
CREATE DATABASE db02 CHARACTER SET utf8;
#创建一个使用utf8字符集,并带校对规则的db03数据库
CREATE DATABASE db03 CHARACTER SET utf8 COLLATE utf8_bin;
#校对规则utf8 bin区分大小默认utf8_general_ci不区分天小写
2、查看、删除

#查看当前数据库服务器中的所有数据库
SHOW DATABASES;
#查看前面创建的db01数据库的定义信息
SHOW CREATE DATABASE `db02`;
#在创建数据库,表的时候,为了规避关键字,可以使用反引号解决
#删除前面创建的db01数据库
DROP DATABASE db02;二、数据库的备份和恢复

方法:
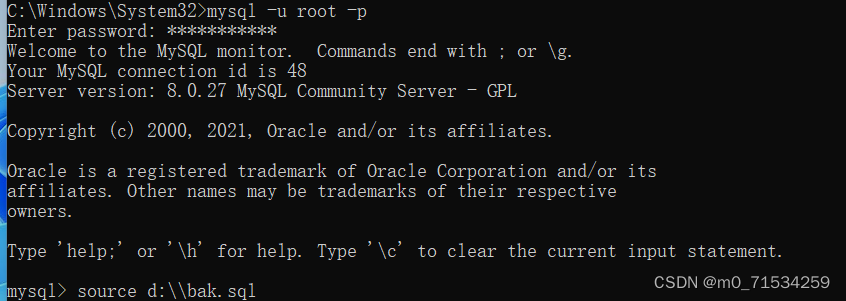
#备份,要在Dos下执行mysqldump指令其实在mysql安装目录\bin
#这个备份的文件,就是对应的sq1语句
mysqldump -u root -p -B db02 db03 > d:\\bak.sql
#恢复数据库(注意:进入Mysql命令行再执行
source d:\\bak.sql
#第二个恢复方法,直接将bak.sq1的内容放到查询编辑器中,执行
1、数据库备份

2、数据库恢复
3、备份表

三、表
1、创建表
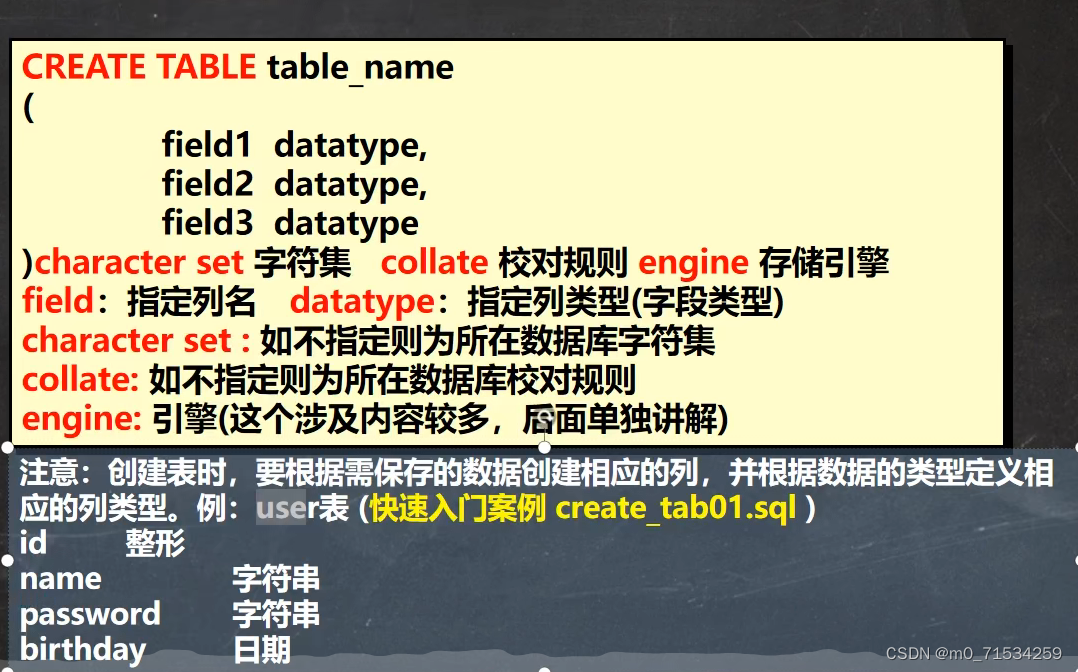
#指令创建表 user
#id 整形
#name 字符串
#password 字符串
#birthday 日期
CREATE TABLE `user`(
id INT,
`name` VARCHAR (255),
`password` VARCHAR (255),
`birthday` DATE)
#下面不写默认与数据库相同
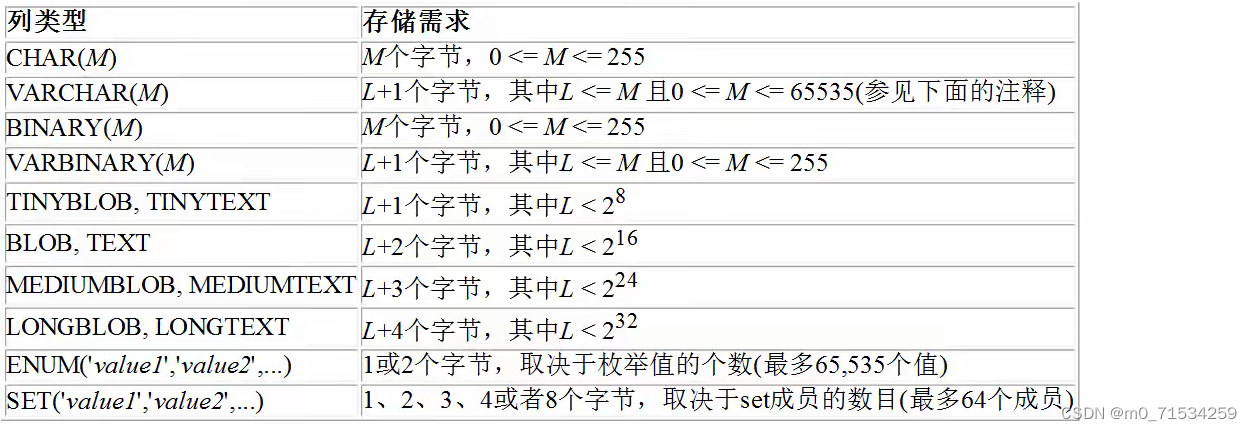
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;2、数据类型
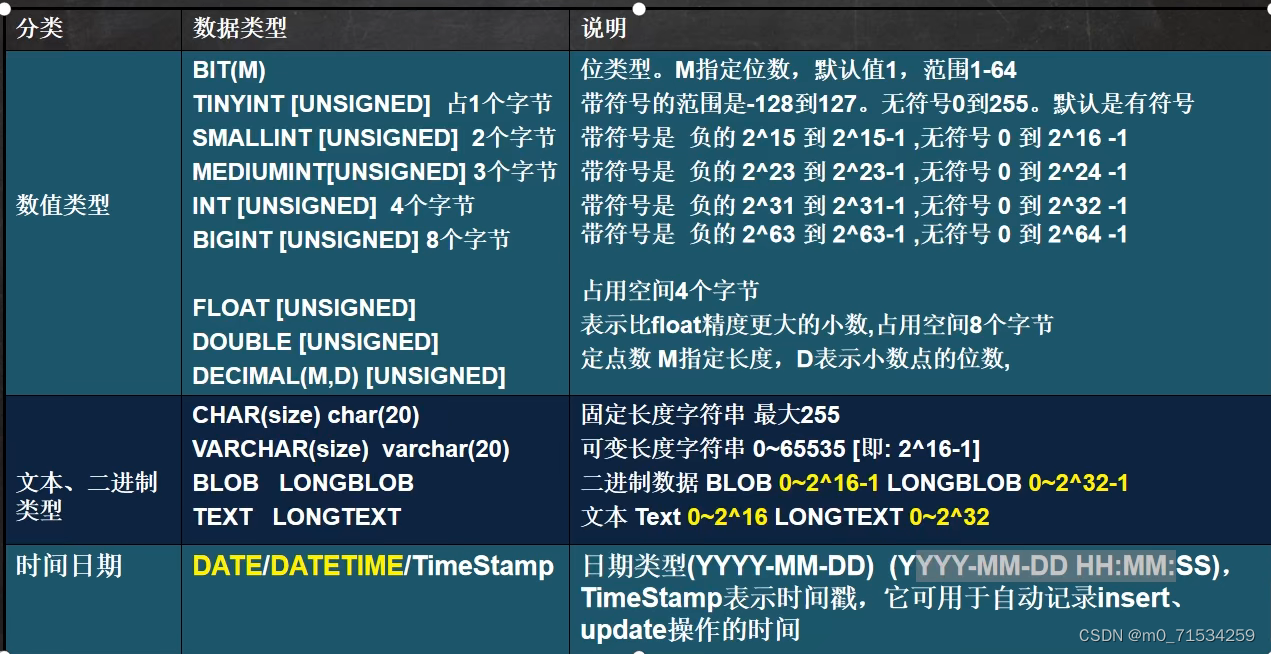
1、int
decimal[M,D] M为长度,D为小数的位数。D写0时就是很多字节的整型
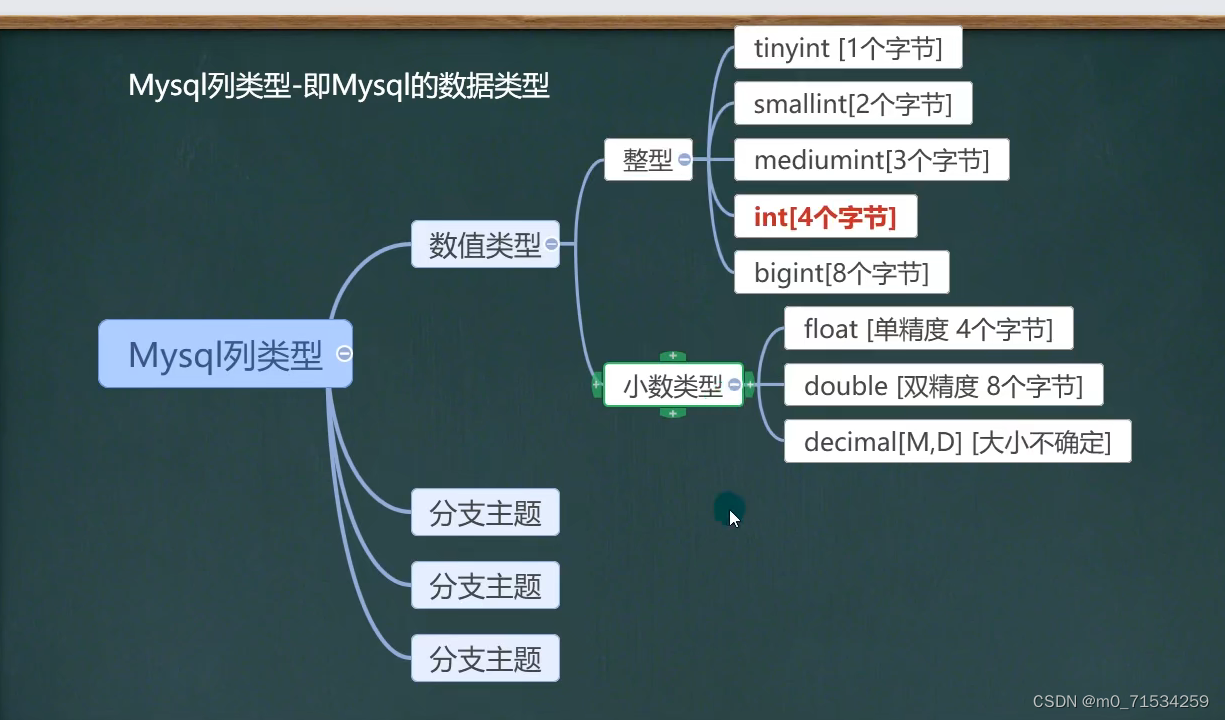
整数类型默认为有符号,设置为无符号的要加关键字unsigned
CREATE TABLE t(
`id` INT UNSIGNED);2、bit
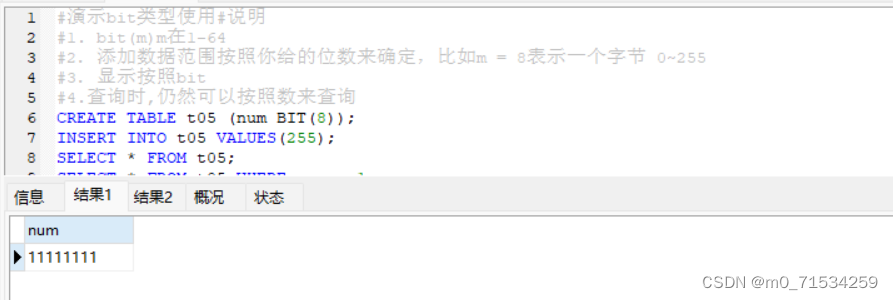
#演示bit类型使用#说明
#1. bit(m)m在1-64
#2.添加数据范围按照你给的位数来确定,比如m = 8表示一个字节 0~255
#3.显示按照bit
#4.查询时,仍然可以按照数来查询
CREATE TABLE t05 (num BIT(8));
INSERT INTO t05 VALUES(255);
SELECT * FROM t05;
SELECT * FROM t05 WHERE num = 1;
3、小数

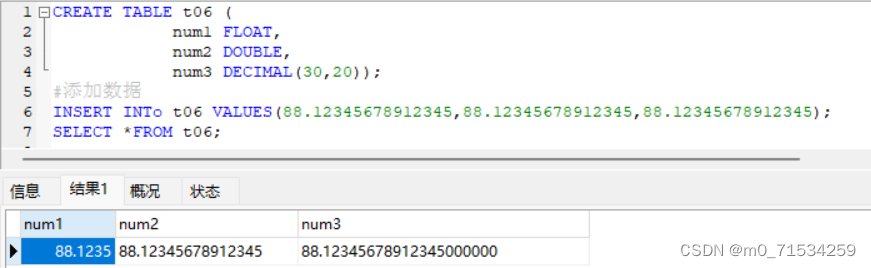
CREATE TABLE t06 (
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20));
#添加数据
INSERT INTO t06 VALUES(88.12345678912345,88.12345678912345,88.12345678912345);
SELECT *FROM t06;
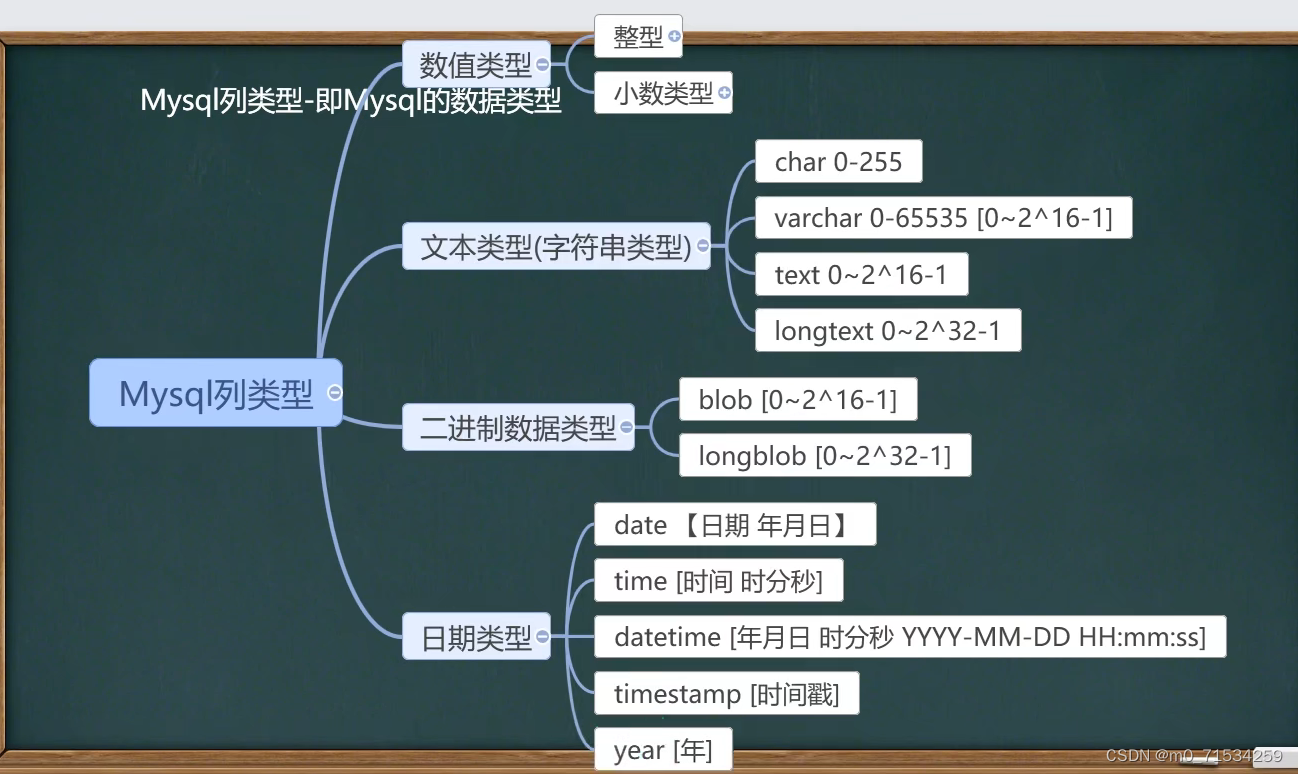
4、字符串
utf8编码3个字节表示一个字符,gbk编码2个字节表示一个字符,所以varchar(size)中所能填写的最大值不同

细节:
1.char()是定长的,比如用char(4)存储'aa' ,那么它占用的空间任然是4个字符,varchar()是变长的,比如用varchar(4)存储‘aa’,存储空间是:两个字符+(1~3)个字节(用于记录数据大小)。
2.如果确定某个数据的长度,就用char(),因为查询速度:char() > varchar()
3.mediumtext 和 longtext 也是变长的
5、日期类型
#创建一张表,date , datetime , timestamp
CREATE TABLE t2 (
birthday DATE,
#生日
job_time DATETIME,
#记录年月日时分秒
login_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP #登录时间,如果希望1ogin_time列自动更新,则设置语句
#NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
#意思是:非空,创建时如果空则写入当前时间,更新时更新为当前时间
);
INSERT INTO t2 (birthday, job_time)
VALUES
(
'2022-11-11',
'2022-11-11 10:10:10'
);
SELECT
*
FROM
t2;
 3、修改表
3、修改表

#添加一个列
#不允许为空,默认为'',在`name`列的后面
ALTER TABLE `user` ADD `image` VARCHAR(32) NOT NULL DEFAULT '' AFTER `name`;
#修改password列,使其长度为60
ALTER TABLE `user` MODIFY `password` VARCHAR(60) NOT NULL DEFAULT '' ;
#删除birthday列
ALTER TABLE `user` DROP `birthday`;
#修改表名
RENAME TABLE `user` TO `user01`;
#修改表的字符集
ALTER TABLE `user01` CHARACTER SET utf8;
#列明name改为user_name
ALTER TABLE `user01` CHANGE `name` `user_name` VARCHAR(32) NOT NULL DEFAULT '';四、数据的增删改查
1、添加数据(INSERT)

INSERT INTO `user01` (
id,
user_name,
image,
`password`
)
VALUES
(1, 'jack', 'sss', '123'),
(2, '张三', 'aaa', '456');细节:
1、字符串和日期类型添加数据时要用 '' 括起来
2、如果该列使int型的,但是添加时使'30',可以添加成功,数据库底层会尝试把字符串转换成int型,但是写成'abc'就不行了。
2、修改数据(UPDATE)

-- 1.将所有员工薪水修改为5000元。[如果没有带where条件,会修改所有的记录,因此要小心]
UPDATE employee
SET salary = 5000;
-- 2.将姓名为小妖怪的员工薪水修改为3000元。
UPDATE employee
SET salary = 3000
WHERE
user_name = '小妖怪';
-- 3.将老妖怪的薪水在原有基础上增加1000元
UPDATE employee
SET salary = salary + 1000 , job = '军师'
WHERE
user_name = '老妖怪';细节:如果没有带where条件,会修改所有的记录
3、删除数据(DELETE)

DELETE
FROM
user01
WHERE
user_name = 'jack';细节:

4、查询数据(SELECT)
1、单表
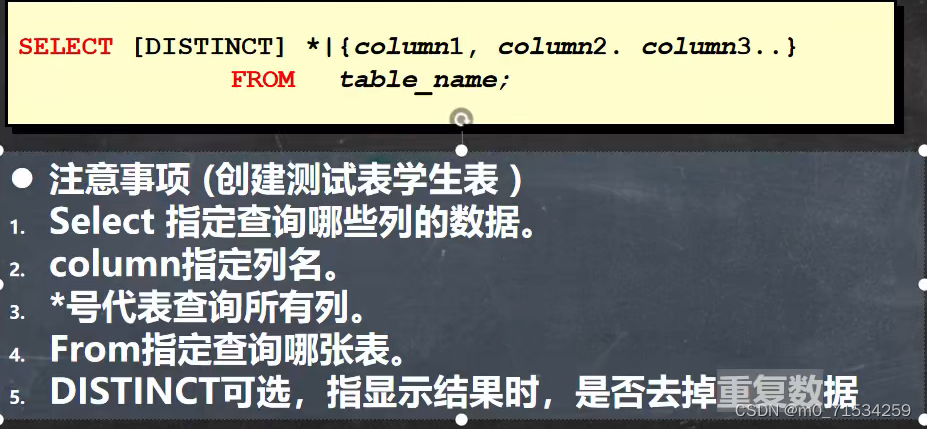

SELECT
`name` AS '姓名',
(chinese + math + english) AS '总分'
FROM
student;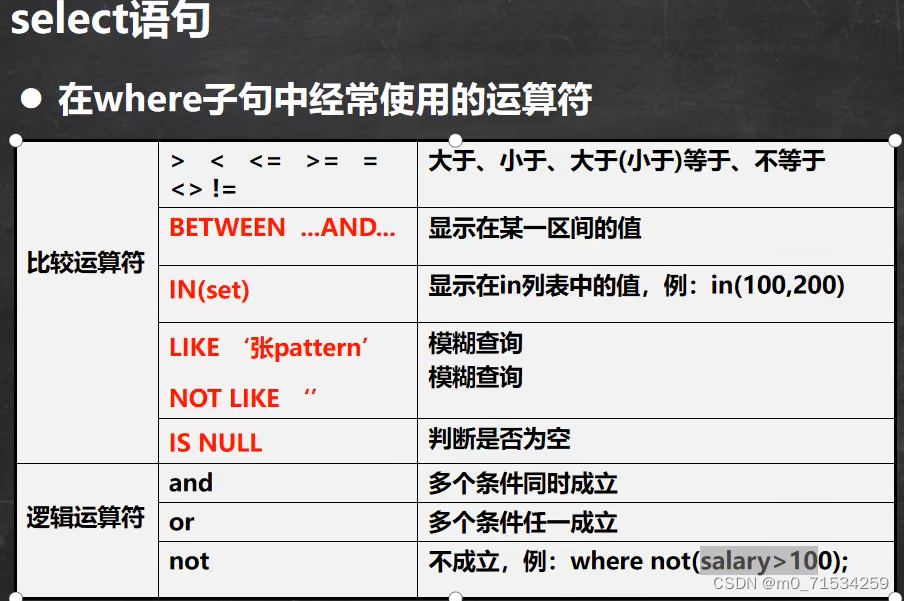
细节:
1、between是闭区间
2、like 后 % 不固定大小,_固定大小
1、排序(order by)
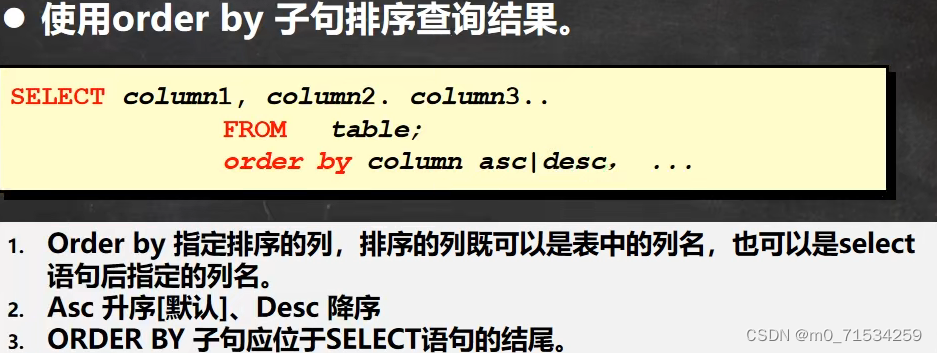
SELECT
`name` AS '姓名',
(chinese + math + english) AS '总分'
FROM
student
WHERE
`name` LIKE '李%'
ORDER BY
'总分' DESC; #或者 (chinese + math + english) DESC;2、统计函数
1、count

SELECT
COUNT(*)
FROM
user01
WHERE
`user_name` LIKE '张%';注意:

2、sum 
3、avg

4、max/min
3、分组查询(group by)
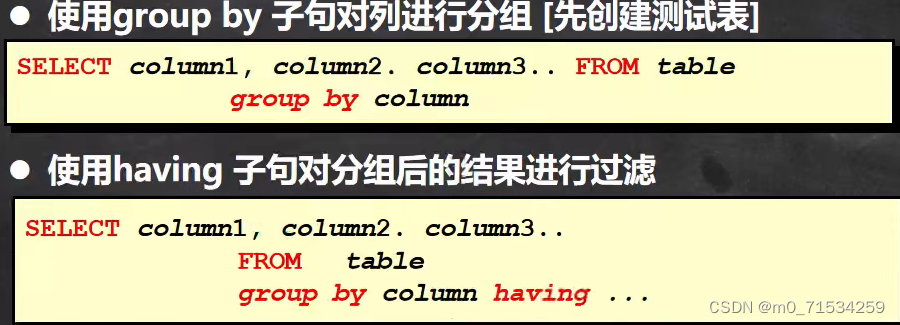
#显示平均工资低于2000的部门号和它的平均工资
SELECT
AVG(sal),
deptno
FROM
emp
GROUP BY
deptno
HAVING
AVG(sal) < 2000;4、字符串相关
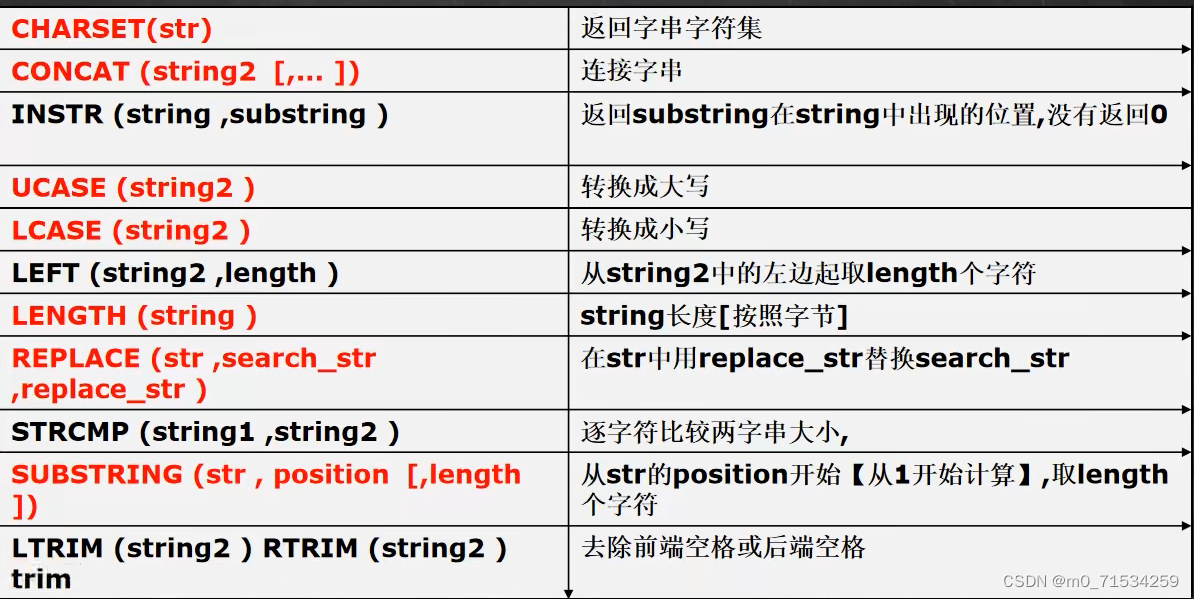
5、数学相关函数
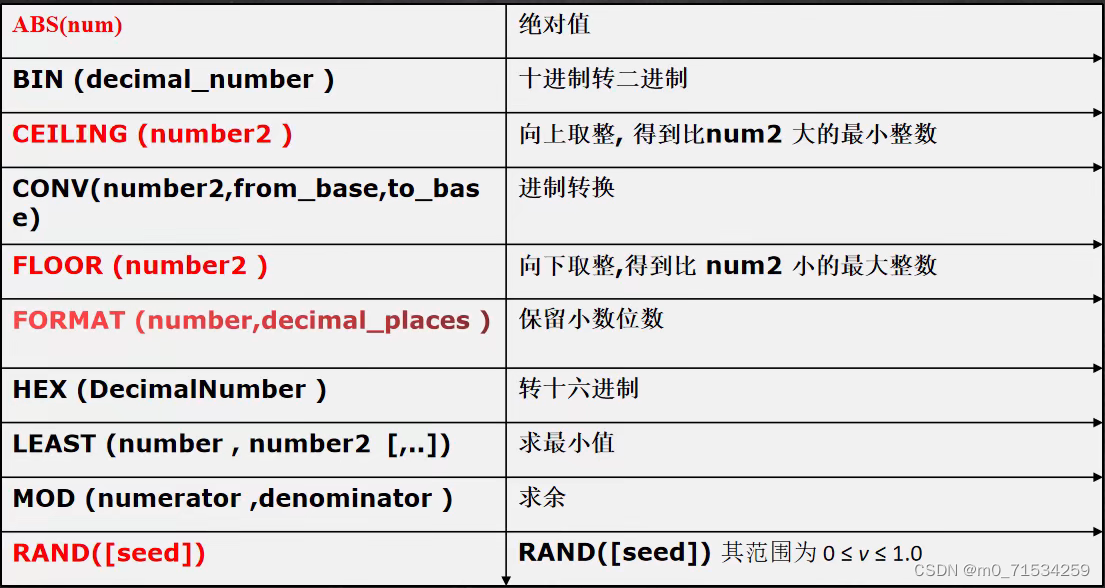
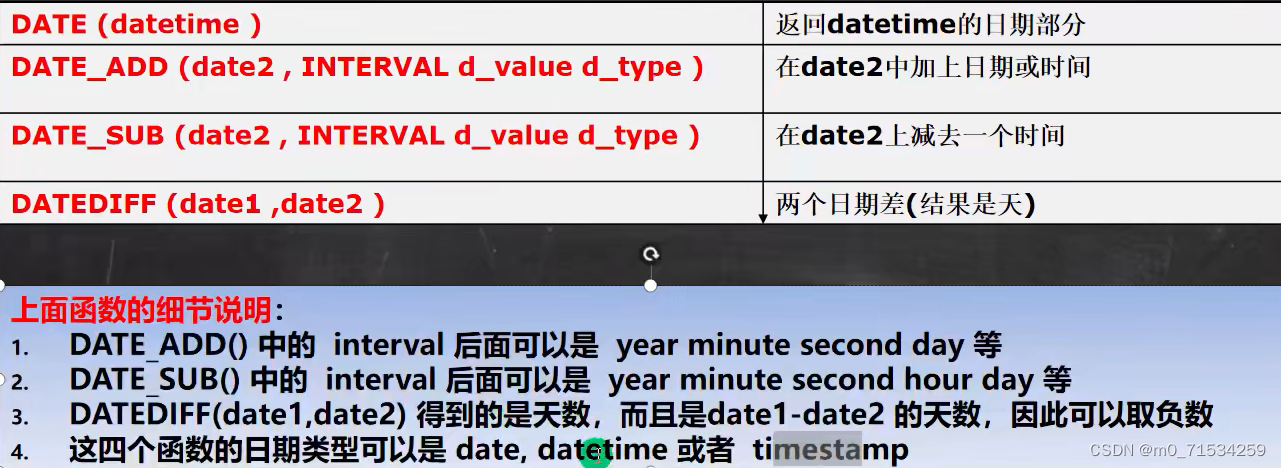
6、时间日期相关函数
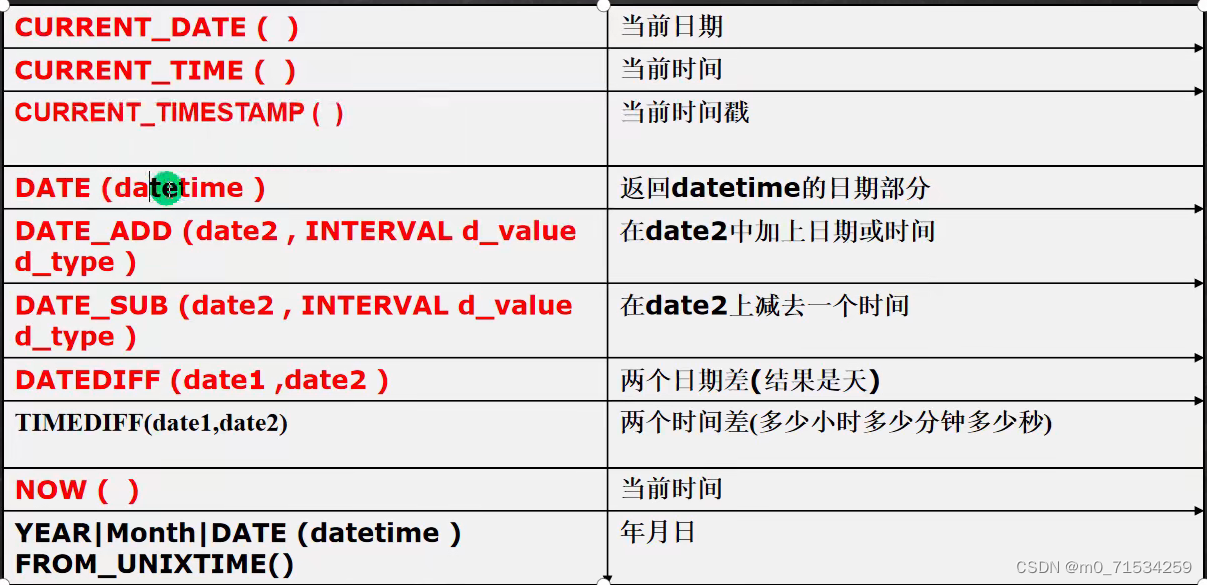


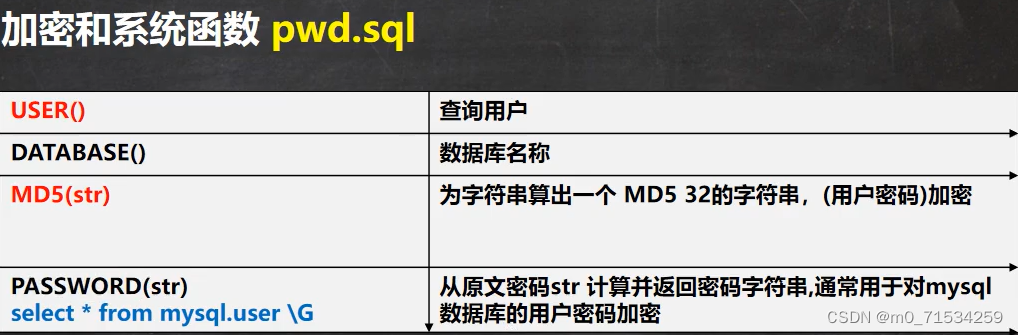
7、加密和系统函数
 8、流程控制函数
8、流程控制函数

9、分页查询


2、多表
SELECT * FROM t1,t2;返回t1,t2的笛卡尔集
自连接
嵌套查询
子查询临时表
all、any
多列子查询:
查询与ALLEN的部门和岗位完全相同的所有雇员(并且不含ALLEN本人)
#(字段1,字段2 ...) = (select 字段1,字段2 from . 。。。)
#分析:1.得到ALLEN的部门和岗位
SELECT
deptno,
job
FROM
emp
WHERE
ename = 'ALLEN';
#分析: 2把上面的查询当做子查询来使用,并且使用多列子查询的语法进行匹配
SELECT
*
FROM
emp
WHERE
(deptno, job) = (
SELECT
deptno,
job
FROM
emp
WHERE
ename = 'ALLEN'
)
AND ename != 'ALLEN';
表的自我复制
#表的自我复制
INSERT INTO user01 SELECT * FROM user01;复制表
#复制属性列
CREATE TABLE t1 LIKE t2;
#复制内容
INSERT INTO t1 SELECT * FROM t2;表元素去重
#创建一个临时表结构与原表相同
CREATE TABLE user01_temp LIKE user01;
#向临时表中添加原表去重的数据
INSERT INTO user01_temp
SELECT DISTINCT * FROM user01;
#删除原表中的信息
DELETE FROM user01;
#把临时表中的信息添加到原表中
INSERT into user01
SELECT * FROM user01_temp;
#删除临时表
DROP TABLE user01_temp;合并查询(union、union all)

左外连接(LEFT JOIN)
SELECT `name`,stu.id,grade
FROM stu LEFT JOIN exam ON stu.id = exam.id;右外连接(RIGHT JOIN)
五、表约束
1、主键(PRIMARY KEY)
CREATE TABLE t17 (
id INT PRIMARY KEY,
#表示id列是主键
`name` VARCHAR (32),
email VARCHAR (32)
);
或
CREATE TABLE t17 (
id INT PRIMARY KEY,
#表示id列是主键
`name` VARCHAR (32),
email VARCHAR (32),
PRIMARY KEY(id,`name`)
);2、not null、unique

细节:
unique约束的列可以有多个NULL
3、外键
#创建主表my_class
CREATE TABLE my_class (
id INT PRIMARY KEY,
`name` VARCHAR (32) NOT NULL DEFAULT ''
);
#创建从表my_stu
CREATE TABLE my_stu (
id INT PRIMARY KEY,
#学生编号
`name` VARCHAR (32) NOT NULL DEFAULT '',
class_id INT,
#下面指定外键关系
FOREIGN KEY (class_id) REFERENCES my_class (id)
);细节:

4、check(mysql8.0之后支持)
CREATE TABLE t23 (
id INT PRIMARY KEY,
`name` VARCHAR (32),
sex VARCHAR (6) CHECK (sex IN('man', 'woman')),
sal DOUBLE CHECK (sal > 1000 AND sal < 2000)
);
5、自增长
CREATE TABLE t25
(id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR (32) NOT NULL DEFAULT '',
`name` VARCHAR(32) NOT NULL DEFAULT '');
ALTER TABLE t25 AUTO_INCREMENT = 100;细节:
1.一般来说自增长是和primary key配合使用的
2.自增长也可以单独使用[但是需要配合一个unique]
3.自增长修饰的字段为整数型的(虽然小数也可以但是非常非常少这样使用)
4.自增长默认从1开始,你也可以通过如下命令修改altertable表名auto_increment =新的开始值;
5.如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准,下面再添加数据时从最大的值开始,如果指定了自增长,一般来说,就按照自增长的规则来添加数据
六、索引

1、创建索引
注意:
当创建表时定义主键和unique时,MySQL会自动创建索引

 2、删除索引
2、删除索引

3、修改索引
先删除,在添加
4、查询索引
#1
SHOW INDEX FROM t5
#2
SHOW KEYS FROM t5
#3
SHOW indexes FROM t5七、事务
1、开启事务


2、隔离级别
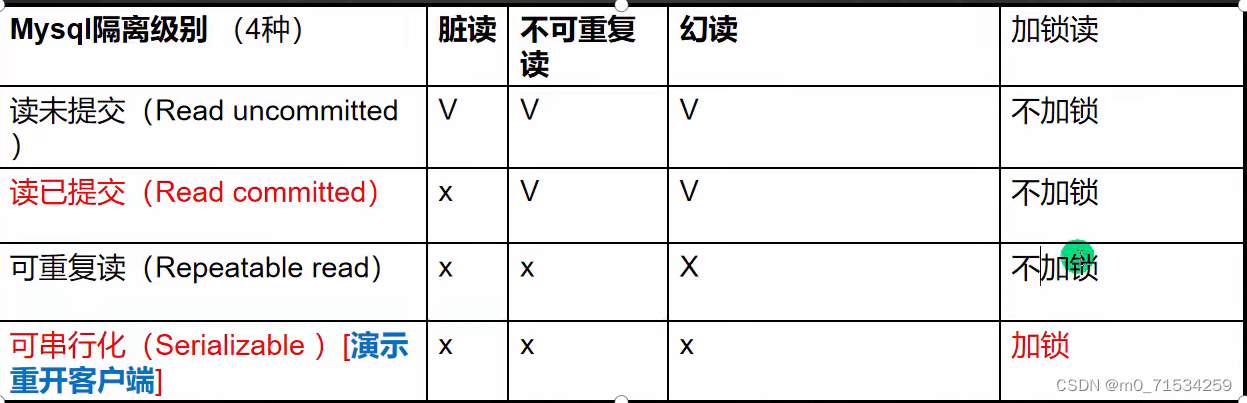
#查看当前会话隔离级别
SELECT @@transaction_isolation;
#查看系统当前隔离级别
SELECT @@global.transaction_isolation;
#设置当前会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
#设置系统当前隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL[你设置的级别]
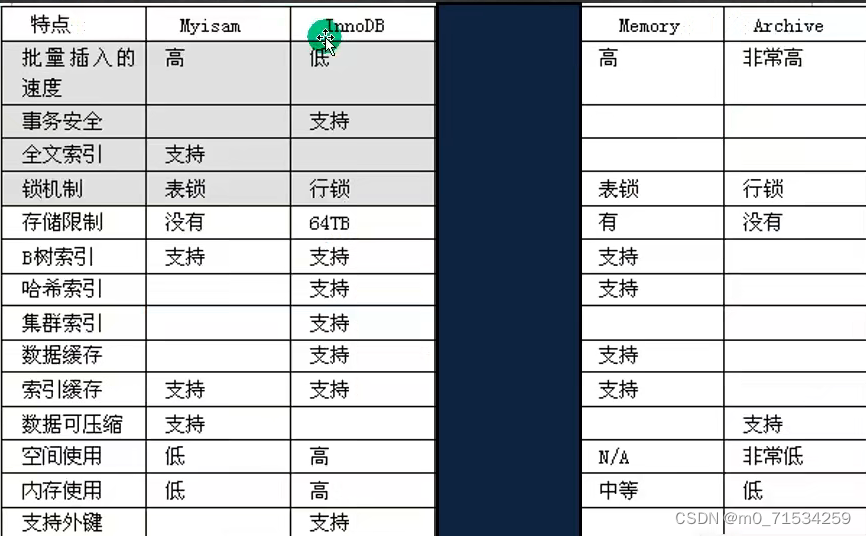
八、存储引擎

九、视图
1、对视图的总结
1.视图是根据基表(可以是多个)来创建的视图是虚拟的表
2.视图也有列,数据来自基表
3.通过视图可以修改基表的数据
4.基表的改变,也会影响到视图的数据
5.视图可以再创建视图
2、视图的使用

十、MySQL管理
1、用户管理

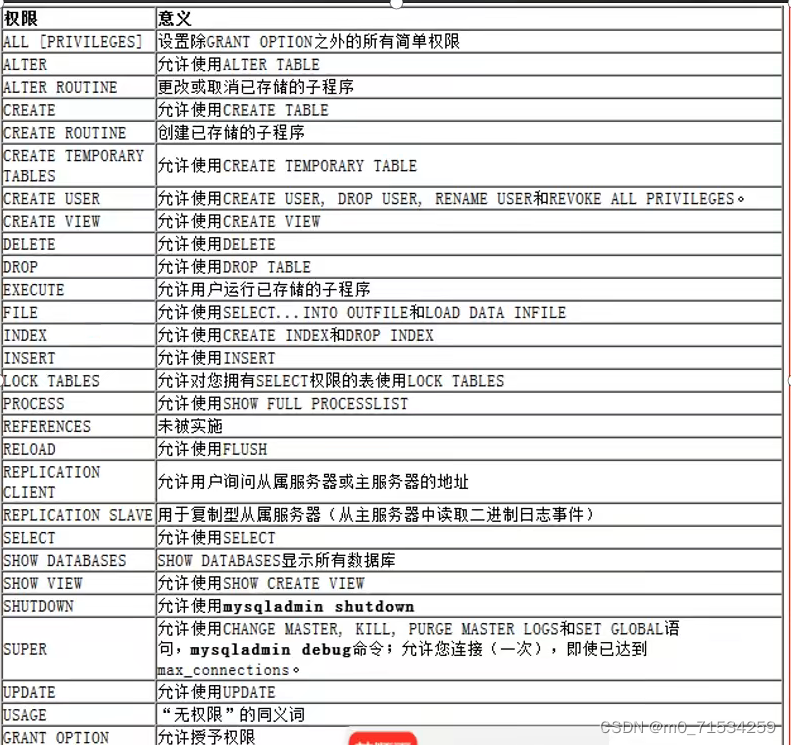
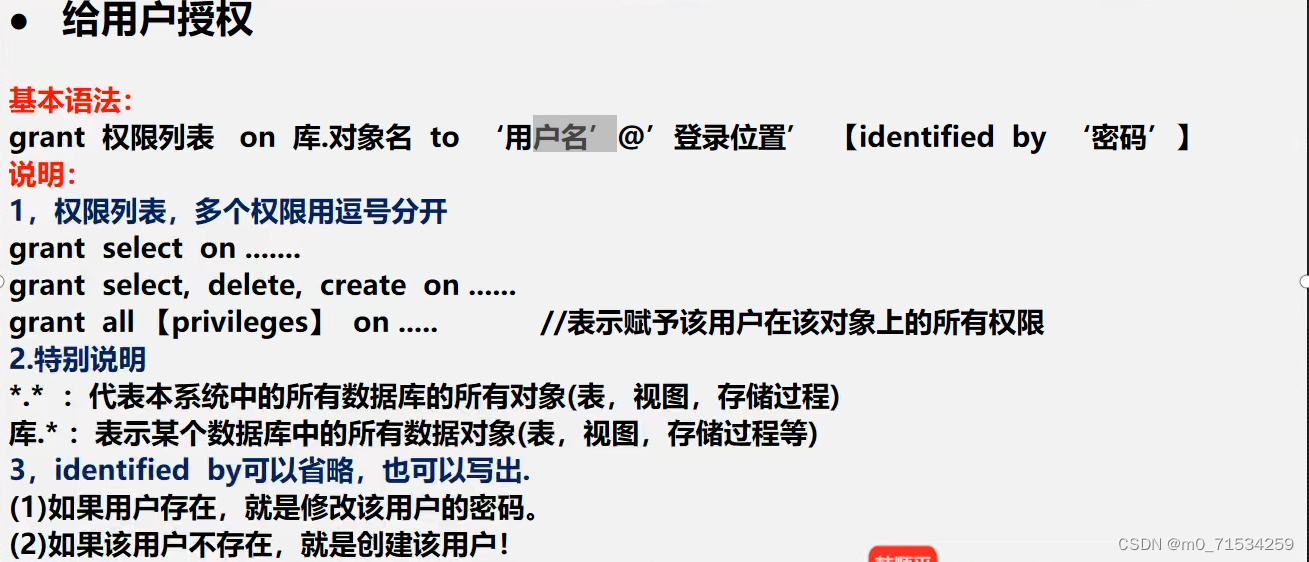
 2、权限管理
2、权限管理




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









