






#AI夏令营 #Datawhale #夏令营
记录自己参加 Datawhale 夏令营期间的学习心得,欢迎交流讨论
一、前言
基于术语词典干预的机器翻译挑战赛选择以英文为源语言,中文为目标语言的机器翻译。本次大赛除英文到中文的双语数据,还提供英中对照的术语词典。参赛队伍需要基于提供的训练数据样本从多语言机器翻译模型的构建与训练,并基于测试集以及术语词典,提供最终的翻译结果,数据包括:
·训练集:双语数据:中英14万余双语句对
·开发集:英中1000双语句对
·测试集:英中1000双语句对
·术语词典:英中2226条
其中训练模型过程中不可以使用除提供的数据外的其他数据吗,不允许使用预训练模型。
通过学习Datawhale提供的baseline,利用魔搭平台的资源,完成以上任务需求。
二、思路
0. 环境配置
使用魔搭平台,安装一些库,不做赘述
1. 数据预处理
预处理阶段通常包括多个步骤,旨在清理、标准化和转换数据,使之适合模型训练。下面介绍我对于baseline的补充。
1.1 清洗数据
因为训练集中含有很多单个中文括号包含的脏数据,所以添加一个函数来进行清洗。
# 清理中文文本中的括号及其中间内容
def clean_zh_text(text: str) -> str:
cleaned_text = re.sub(r'([^()]*)', '', text)
return cleaned_text在这段代码中,通过使用正则表达式
re.sub(r'([^()]*)', '', zh)
来移除中文字符串zh中的括号及其中间内容,然后再使用中文分词器zh_tokenizer进行处理。这里的正则表达式r'([^()]*)'是一个简单的模式,它假定括号是成对出现的,且没有嵌套括号。
1.2 数据预处理
这里的中文开发集已经手动去除括号,所以单独对训练集进行预处理函数的修改。也可以统一去除。并且返回处理好的中文训练集作为参考检查。
# 数据预处理函数
def preprocess_trainzh_data(en_data: List[str], zh_data: List[str]) -> List[Tuple[List[str], List[str]]]:
processed_data = []
processed_zh_data = [] # 存储处理后的中文数据
for en, zh in zip(en_data, zh_data):
en_tokens = en_tokenizer(en.lower())[:MAX_LENGTH]
cleaned_zh = clean_zh_text(zh)
zh_tokens = zh_tokenizer(cleaned_zh)[:MAX_LENGTH]
if en_tokens and zh_tokens: # 确保两个序列都不为空
processed_data.append((en_tokens, zh_tokens))
processed_zh_data.append(' '.join(zh_tokens)) # 将处理后的中文数据转换为字符串形式
return processed_data, processed_zh_data
def preprocess_data(en_data: List[str], zh_data: List[str]) -> List[Tuple[List[str], List[str]]]:
processed_data = []
for en, zh in zip(en_data, zh_data):
en_tokens = en_tokenizer(en.lower())[:MAX_LENGTH]
zh_tokens = zh_tokenizer(zh)[:MAX_LENGTH]
if en_tokens and zh_tokens: # 确保两个序列都不为空
processed_data.append((en_tokens, zh_tokens))
return processed_data在数据加载函数中添加对应的步骤对中文训练集进行处理和返回。
# 读取训练数据
train_data = read_data(train_path)
train_en, train_zh = zip(*(line.split('\t') for line in train_data))
# 预处理数据
train_processed, processed_zh_texts = preprocess_trainzh_data(train_en, train_zh)
# 写入处理后的中文数据到文件
output_file = 'processed_zh_data.txt'
with open(output_file, 'w', encoding='utf-8') as f:
for zh_text in processed_zh_texts:
f.write(zh_text + '\n')
2. 模型训练
使用Seq2Seq 这种编码器、解码器架构,中间层使用GRU网络,并且网络中加入了注意力机制。
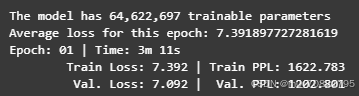
训练过程选择10000个样本,15个epoch,这样时间上可以接受,但是效果也没有特别好,因为样本和epoch的提高会使得训练时间大幅增加。因此Task2选择参数如此。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









