






2.6
递归思想:
def num(x):
if x>0:
print(x)
num(x-1)
num(3)对比理解
def num(x):
if x>0:
num(x-1)
print(x)
num(3)
第一个输出3,2,1 第二个输出1,2,3,利用栈概念理解
汉诺塔问题(递归)
def hannuota(n,a,b,c):
if n>0:
hannuota(n - 1, a, c, b)
print("moving %s to %s" % (a, c))
hannuota(n - 1, b, a, c)
hannuota(3,'A','B','C')关键在于理解搬运的过程:
第一步把n-1个从A经过B运到C
第二步把最后一个从A运到C
第三步把n-1个从B经过A运到C
顺序查找
def fg(ls,v):
for index,value in enumerate(ls):
if value==v:
return index
return 0
print(fg([2,3,4],4))def fg(ls,v):
for i in range(len(ls)):
if ls[i]==v:
return i
return 0
print(fg([2,3,4],4))
顺序查找就是从头遍历到尾,复杂度为O(n)
二分法查找
def fg(ls,val):
left=0
right=len(ls)-1
while right>=left:
mid=(left+right)//2
if ls[mid]==val:
return mid
elif ls[mid]<val:
left=mid+1
else:
right=mid-1
else:
return None
print(fg([1,2,3,4],2))
默认已经排好序,原理就是折中查找,复杂度为O(logn),比顺序查找效率高
因此系统默认的index()函数采用的是顺序查找,因为不用排序,如果查找次数很多可以用二分查找,不然比较得不偿失
排序介绍

冒泡排序:
import random
def fg(ls):
for i in range(len(ls)-1):#i表示第i趟,len(ls)-1表示一共需要多少趟
for j in range(len(ls)-i-1):#箭头最多指到len(ls)-i-1,另外注意左闭右开,右边取不到
if ls[j]>ls[j+1]:
ls[j],ls[j+1]=ls[j+1],ls[j]
ls=[random.randint(0,10000) for i in range(1000)]
print(ls)
fg(ls)
print(ls)当冒泡排序中的一趟排序没有发生交换,默认不用排序,表明列表已有序,可以直接结束算法
故冒泡排序最好复杂度为O(n),一般为O(n2)
def fg(ls):
for i in range(len(ls)-1):#i表示第i趟,len(ls)-1表示一共需要多少趟
for j in range(len(ls)-i-1):#箭头最多指到len(ls)-i-1,另外注意左闭右开,右边取不到
flag=False
if ls[j]>ls[j+1]:
ls[j],ls[j+1]=ls[j+1],ls[j]
flag=True
print(ls)
if not flag:
return
ls=[1,2,3,4,5]
fg(ls)选择排序:
def fg(ls):
newls=[]
for i in range(len(ls)):
minvalue=min(ls)
newls.append(minvalue)
ls.remove(minvalue)
return newls
ls=[2,3,5,4]
print(fg(ls))缺点:1.额外占用内存 2.复杂度高
改进:
def fg(ls):
for i in range(len(ls)-1):#i表示第几趟
minco=i#记录无序区最小位置
for j in range(i+1, len(ls)):
if ls[j]<ls[minco]:
minco=j#改变最小位置
ls[i],ls[minco]=ls[minco],ls[i]#把最小的数放最前面
ls=[2,3,5,4]
fg(ls)
print(ls)
复杂度:O(n2)
插入排序:
刚开始(有序区)只有一张牌,每次从无序区抽一张牌插入到手里已有牌的正确位置
def fg(ls):
for i in range(1,len(ls)):#i表示摸到的牌下标
tmp=ls[i]
j=i-1#j表示手里的牌的下标
while j>=0 and ls[j]>tmp:#j<0表示j移动到j-1的位置,也就没有更小的;或者手里的牌都小于抽到的牌,这两种情况不用移动
ls[j+1]=ls[j]
j-=1
ls[j+1]=tmp
ls=[2,4,1,6]
fg(ls)
print(ls)时间复杂度:O(n2)
快速排序
def guiwei(ls,left,right):
tmp=ls[left]
while left<right:
while ls[right]>=tmp and left<right:#遍历寻找:从右侧找比tmp小的数
right-=1#左移一步,一步一步找
ls[left]=ls[right]#找到了就赋值
while left<right and ls[left]<tmp:#右边空出来了,找左边比tmp大的数
left+=1
ls[right] = ls[left]
ls[left]=tmp#此时ls[left]==ls[right],将递归值放中间;如果ls[left]==ls[right],则直接跳过前面步骤
return left#返回中间值
def fg(ls,left,right):
if left<right:
mid = guiwei(ls, left, right)
fg(ls, left, mid - 1)#左边递归
fg(ls, mid + 1, right)#右边递归
ls=[5,2,1,4,3]
fg(ls,0,len(ls)-1)
print(ls)复杂度O(nlogn)
但这个代码如果用[5,4,3,2,1]就不对,结果出来是[1,4,3,2,5]希望大佬指点一下(已解决)

上面的例子就是快速递归出现最坏情况的例子,在最坏情况中复杂度也发生了变化,由于每次只交换一个数,复杂度就变成了O(n2)
解决办法:随机化,即随机选一个数,与第一个数交换然后guiwei
除此之外,快排还会消耗系统资源,可能达到最大深度
解决:import sys
sys.setrecursionlimit(最大深度)
堆排序:
过程:
1.构造堆(农村包围城市,得到堆顶元素,即最大元素)
2.挨个出数(退休-旗子上去-调整,得第二大元素)
3.重复步骤,直到堆变空
def sift(ls,low,high):#调整函数
#low:堆顶,即堆的根节点位置
#high:堆的最后一个元素
i=low#i最开始指向根节点
j=2*i+1#j最开始是左孩子
tmp=ls[low]#把堆顶存起来
flag=0
while j<=high:#只要不越界
if j+1<=high:
flag=1
if flag==1 and ls[j + 1] > ls[j]: # 两个孩子相比谁大就指向谁,但同时需要保证大的孩子存在
j = j + 1 # 改变指向
if tmp<ls[j]:#现在已经找到孩子中比较大的,拿大的和tmp比较,如果tmp小
ls[i]=ls[j]#把大的移动到上面位置
i=j#i向下移动一层
j=2*i+1#j也随之改变
else:#但如果i已经比孩子大
ls[i]=tmp#直接赋值
break#同时说明循环结束
else:#j发生了越界
ls[i]=tmp
def heap_sort(ls):#堆排序,要先建堆
n=len(ls)
for i in range((n-2)//2,-1,-1):#由最后一个孩子找最后一个父元素
# i表示建堆时候调整的部分的根的下标
sift(ls,i,len(ls)-1)
# high相当于扩大范围了,真正的high是其中的子集
#建堆完成
for i in range(n-1,-1,-1):#i是整个堆最后一个元素
ls[0],ls[i]=ls[i],ls[0]#旗子上去的过程
sift(ls,0,i-1)#然后对整个堆进行调整,注意此时i还没变所以整个堆最后一个元素是i-1
ls=[i for i in range(10)]
import random
random.shuffle(ls)
heap_sort(ls)
print(ls)时间复杂度O(nlogn)
内置模块:
import heapq
import random
ls=[i for i in range(100)]
random.shuffle(ls)
heapq.heapify(ls)#堆排序
print(ls)
for i in range(len(ls)):
print(heapq.heappop(ls),end=' ')#其实相当于每次把列表里面最小的数pop出来典型例子:topk问题
现在有n个数,设计算法得到前k大的数(k<n)
思路:1、排序后切片(复杂度O(nlogn))
2、Lowb三人组(复杂度O(kn))
3、堆排序(复杂度O(klogk))

注意建立的是小根堆,代码如下,主要改动了两个大小符号:
def sift(ls,low,high):#调整函数
#low:堆顶,即堆的根节点位置
#high:堆的最后一个元素
i=low#i最开始指向根节点
j=2*i+1#j最开始是左孩子
tmp=ls[low]#把堆顶存起来
while j<=high:#只要不越界
if j<=high and ls[j + 1]<ls[j]: # 两个孩子相比谁大就指向谁,但同时需要保证大的孩子存在
j = j + 1 # 改变指向
if tmp<ls[j]:#现在已经找到孩子中比较大的,拿大的和tmp比较,如果tmp小
ls[i]=ls[j]#把大的移动到上面位置
i=j#i向下移动一层
j=2*i+1#j也随之改变
else:#但如果i已经比孩子大
ls[i]=tmp#直接赋值
break#同时说明循环结束
else:#j发生了越界
ls[i]=tmp另一部分代码:
def topk(ls,k):
heap=ls[0:k]
for i in range((k - 2) // 2, -1, -1): # 由最后一个孩子找最后一个父元素
# i表示建堆时候调整的部分的根的下标
sift(heap, i, k - 1)
# high相当于扩大范围了,真正的high是其中的子集
# 1.建堆完成
for i in range(k,len(ls)-1):
if ls[i]>ls[k]:
ls[k]=ls[i]
sift(heap,0,k-1)
#2.遍历
for i in range(k - 1, -1, -1):
ls[0], ls[i] = ls[i], ls[0] # 旗子上去的过程
sift(ls, 0, i - 1) # 然后对整个堆进行调整,注意此时i还没变所以整个堆最后一个元素是i-1
#3.挨个输出所以总体代码为:
def sift(ls,low,high):#调整函数
#low:堆顶,即堆的根节点位置
#high:堆的最后一个元素
i=low#i最开始指向根节点
j=2*i+1#j最开始是左孩子
tmp=ls[low]#把堆顶存起来
while j<=high:#只要不越界
if j+1<=high and ls[j + 1]<ls[j]: # 两个孩子相比谁大就指向谁,但同时需要保证大的孩子存在
j = j + 1 # 改变指向
if tmp<ls[j]:#现在已经找到孩子中比较大的,拿大的和tmp比较,如果tmp小
ls[i]=ls[j]#把大的移动到上面位置
i=j#i向下移动一层
j=2*i+1#j也随之改变
else:#但如果i已经比孩子大
ls[i]=tmp#直接赋值
break#同时说明循环结束
else:#j发生了越界
ls[i]=tmp
def topk(ls,k):
heap=ls[0:k]
for i in range((k - 2) // 2, -1, -1): # 由最后一个孩子找最后一个父元素
# i表示建堆时候调整的部分的根的下标
sift(heap, i, k - 1)
# high相当于扩大范围了,真正的high是其中的子集
# 1.建堆完成
for i in range(k,len(ls)-1):
if ls[i]>heap[0]:#如果序列里面的元素比堆顶元素大
heap[0]=ls[i]#则覆盖
sift(heap, 0, k - 1)#覆盖后在小范围内进行一次调整
#2.遍历
for i in range(k - 1, -1, -1):
heap[0], heap[i] = heap[i], heap[0] # 旗子上去的过程
sift(heap, 0, i - 1) # 然后对整个堆进行调整,注意此时i还没变所以整个堆最后一个元素是i-1
#3.挨个输出
return heap
import random
ls=[i for i in range(100)]
random.shuffle(ls)
print(ls)
print(topk(ls,10))但很奇怪,运行不出来。。。
归并排序
过程:把两个有序列表合并成一个列表,时间复杂度O(nlogn),空间复杂度(O(n))
def merge(ls,low,mid,high):
i=low
j=mid+1
ltmp=[]
while i<=mid and j<=high:
if ls[i]<ls[j]:
ltmp.append(ls[i])
i+=1
else:
ltmp.append(ls[j])
j+=1
#一部分执行完,有一方没数了
while i<=mid:
ltmp.append(ls[i])
i += 1
while j<=high:
ltmp.append(ls[j])
j += 1
ls[low:high + 1] = ltmp
def merge_sort(ls,low,high):
if low<high:
mid=(low+high)//2
merge_sort(ls,low,mid)#左边排好序
merge_sort(ls,mid+1,high)#右边排好序
merge(ls,low,mid,high)#进行归并操作
ls=[2,4,5,7,1,3,6,8]
merge_sort(ls,0,7)
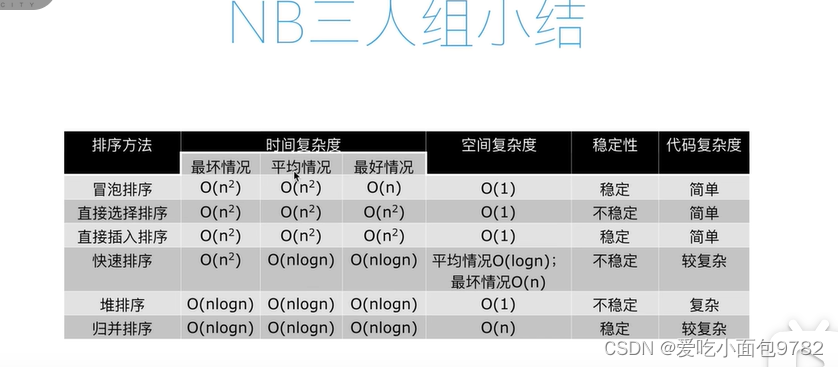
print(ls)NB三人组:快速排序、堆排序、归并排序
时间复杂度都是O(nlogn)
运行时间:快速排序<归并排序<堆排序
快速排序:极端情况下(倒序)效率比较低(n2),但可以用随机
归并排序:额外占用存储空间
堆排序:相比之下速度最慢
希尔排序
就是插入排序的变形,不过间隔是gap
时间复杂度较多不做讨论
def insert_sort_gap(ls,gap):
for i in range(len(ls)):
tmp=ls[i]
j=i-gap
while j>=0 and ls[j]>tmp:
ls[j+gap]=ls[j]
j-=gap
ls[j+gap]=tmp
def xier(ls):
d=len(ls)//2
while d>=1:
insert_sort_gap(ls, d)
d=d//2
import random
ls=[i for i in range(1000)]#list(range(1000))
random.shuffle(ls)
print(ls)
xier(ls)
print(ls)计数排序
特点:1.有一个最大值 2.时间复杂度为O(n) 3.需要占据较多额外空间
def count_sort(ls,max_count=100):
count=[0 for _ in range(max_count+1)]
for val in ls:
count[val]+=1
ls.clear()
for ind,val in enumerate(count):
for i in range(val):#因为有val个ind,所以应该把ind遍历val遍
ls.append(ind)
import random
ls=[random.randint(0,100) for _ in range(1000)]#把0-100的数遍历1000次
print(ls)
count_sort(ls,max_count=100)
print(ls)
桶排序
在计数排序的基础上,如果数比较多,则计数排序占据内存较大,可以用桶排序,即把数字放在不同的桶(区间)里面,由于各个区间是有序的,那么将每个区间按顺序输出后,输出的列表也是有序的
def buckets_sort(ls,n=100,max_num=10000):
buckets=[[] for _ in range(n)]#创建桶
for val in ls:#遍历列表中的值
i=min(val//(max_num//n),n-1)#一共有0-99的桶,为了避免最后的10000越界,只能把10000放在第99个桶里面
buckets[i].append(val)
#把元素放进桶内,下一步是对桶里面的元素进行排序
for j in range(len(buckets[i])-1,0,-1):#从最后一个元素到第一个元素进行冒泡排序
if buckets[i][j]<buckets[i][j-1]:#如果一个桶里面的某一个元素要比前一个元素小、
buckets[i][j],buckets[i][j-1]=buckets[i][j-1],buckets[i][j]#将前后元素进行交换
else:#后面的元素要比前面的大
break
sort = []
for buc in buckets:
sort.extend(buc) # 把每个桶里面的元素看成一个列表,然后把每个列表连在空列表sort后面
return sort
import random
ls=[random.randint(0,10000) for _ in range(100000)]
print(buckets_sort(ls,n=100,max_num=10000))基数排序
时间复杂度O(kn),空间复杂度O(k+n),与k的取值有关,不一定比快速排序(nlogn)还快
def radix_sort(ls):
it=0
max_sort=max(ls)
while 10 ** it <= max_sort:
buckets=[[] for _ in range(10)]
for val in ls:
digit = (val // 10 ** it) % 10 # 按照每个位置上的数字遍历然后放到正确的桶里
buckets[digit].append(val)
#分桶完成
ls.clear()
for buc in buckets:
ls.extend(buc)
it+=1
import random
ls=list(range(1000))
random.shuffle(ls)
print(ls)
radix_sort(ls)
print(ls)
#与桶排序不同的是,桶排序是装一次然后在桶里面进行排序,但基数排序是分次装桶然后输出,也就是会执行多次典型例题
1.在一个二维数组里面找一个数
h=len(matrix)#二维列表行数
if h<=0:
return False
w=len(matrix[0])#二维列表列数
if w<=0:
return True
left=0
right=h*w-1
while left<=right:
mid=(left+right)//2
i=mid//w
j=mid%w
if matrix[i][j]=mid:
return True
elif matrix[i][j]<mid:
right=mid-1
else:
left=mid+1
else:
return False利用二分法效率会很高
数据结构
列表
线性结构:一对一
树结构:一对多
图结构:多对多
在Python列表中插入和删除的时间复杂度为O(n)
栈
定义:只能在一端进行插入或删除操作的列表
特点:后进先出
概念:栈顶,栈底
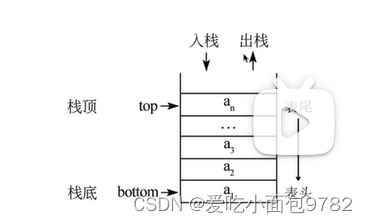
栈的操作:
进栈push ls.append() 出栈pop ls.pop() 取栈顶gettop ls[-1]
class Stack:
def __init__(self):
self.stack=[]
def push(self,element):
self.stack.append(element)
def pop(self):
return self.stack.pop()#返回最上面的元素
def get_top(self):
if len(self.stack)>0:
return self.stack[-1]
else:
return None
stack=Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.pop())
class Stack:
def __init__(self):
self.stack=[]
def push(self,element):
self.stack.append(element)
def pop(self):
return self.stack.pop()#返回最上面的元素
def get_top(self):
if len(self.stack)>0:
return self.stack[-1]
else:
return None
def is_empty(self):
return len(self.stack)==0
def match(s):
match_={'}':'{',']':'[',')':'('}
stack=Stack()
for ch in s:
if ch in {'{','[','('}:
stack.push(ch)
else:#ch not in {'{','[','('}
if stack.is_empty():#空栈
return False
elif stack.get_top()==match_[ch]:
stack.pop()
else:
return False
if stack.is_empty():
return True
else:
return False
print(match('[{}]'))队列
特点:先进先出,从一端进入从另一端退出
插入的一端为队尾,插入的动作称为进队或入队
删除的一端称为队头,删除动作称为出队
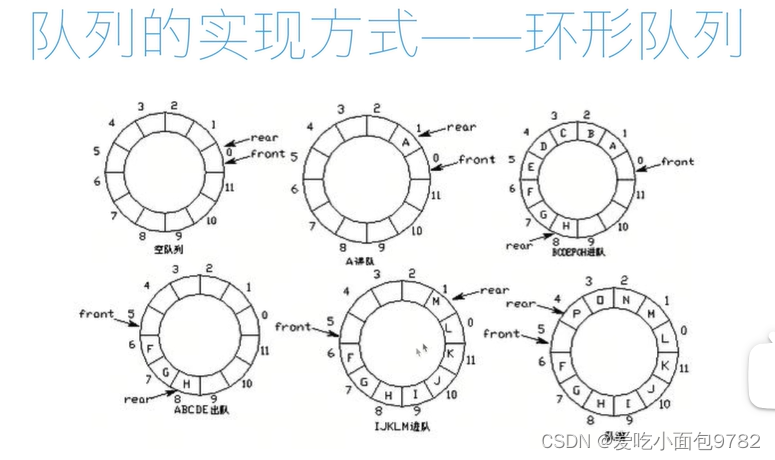
空队列:front=rear
队满:front=(rear+1)%maxsize
当指针front/rear=maxsize-1时,再进一个位置自动到0

队列的实现
class Queue:#创建关于队列的类
def __init__(self,size=100):
self.queue=[0 for _ in range(size)]
self.size=size
self.rear=0
self.front=0
def push(self,element):
self.rear=(self.rear+1)%self.size
self.queue[self.rear]=element
def pop(self):
if not self.is_empty():
self.front = (self.front + 1) % self.size
return self.queue[self.front]
else:
return False
def is_empty(self):
return self.rear==self.front
def is_filled(self):
return self.front==(self.rear+1)%self.size
q=Queue(5)#长度为5的队列
q.push(1)
q.push(2)
q.push(3)
q.push(4)#由于front指的是空的,所以长度为5的队列只能存4个数
print(q.pop())#先进先出队列的内置模块
from collections import deque
q=deque()
q.append(1)
print(q.popleft())#默认右进左出
#以下展示的是deque作为一个双向队列,即左进右出
q.appendleft(2)
print(q.pop())
#在双向队列中,如果队列满了则会按顺序把元素踢出去,而不会报错
q=deque([1,2,3,4,5],5)#队列满了
q.append(6)
print(q.popleft())#因为当6进去后1被pop出来了
#用队列打印文件后几行
def fg(n):
with open('note.txt','r') as f:
q=deque(f,n)#相当于队列最多有n个位置,将note里面的文本每次传进来一行,也就是f,利用的是上面那个规律
return q
for line in fg(2):
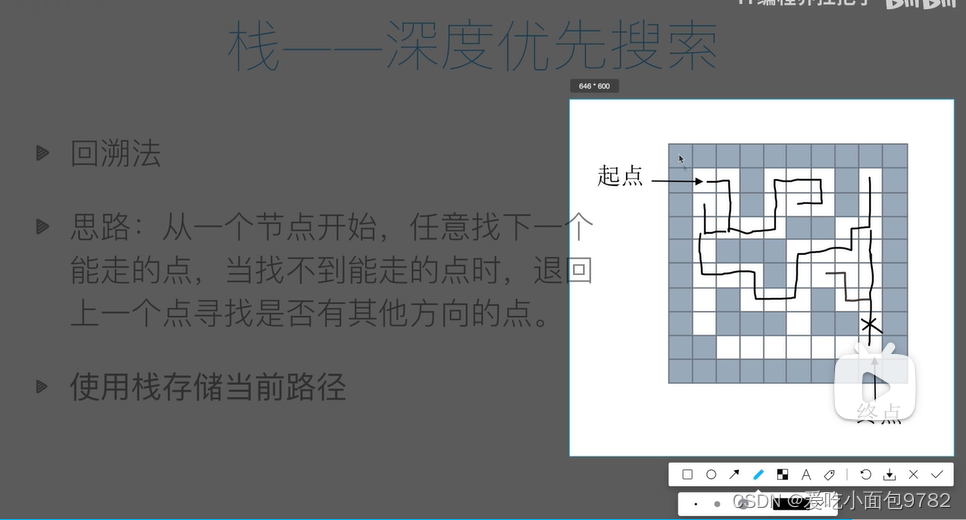
print(line,end=' ')#将文本最后两行打印出来了栈和队列的应用——解决迷宫问题
栈解决——深度优先搜索(一条路走到黑)
mach=[
[1,1,1,1,1,1,1,1,1,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,0,0,1,1,0,0,1],
[1,0,1,1,1,0,0,0,0,1],
[1,0,0,0,1,0,0,0,0,1],
[1,0,1,0,0,0,1,0,0,1],
[1,0,1,1,1,0,1,1,0,1],
[1,1,0,0,0,0,0,0,0,1],
[1,1,1,1,1,1,1,1,1,1]
]
dics=[
lambda x,y:(x-1,y),#上面元素
lambda x,y:(x+1,y),#下面元素
lambda x,y:(x,y-1),#左边元素
lambda x,y:(x,y+1)#右边元素
]
def matche(x1,y1,x2,y2):
stack=[]#用列表创建栈
stack.append((x1,y1))#把起点放进栈
while len(stack)>0:#确保栈不空
curNode = stack[-1] # 当前的节点
if curNode[0]==x2 and curNode[1]==y2:#走到终点了,说明该结束了,需要输出整个路径
for i in stack:
print(i)
return True
for dic in dics:
nextNode = dic(curNode[0],curNode[1])#下一个节点
if mach[nextNode[0]][nextNode[1]]==0:#说明存在下一个路点
stack.append(nextNode)
mach[nextNode[0]][nextNode[1]] = 2#保证单次路径中走过的路不会再走
break
else:#说明不存在下一个路点
mach[nextNode[0]][nextNode[1]] = 2#不要忘了这个已经走过的标记一下
stack.pop()#pop掉栈顶元素
else:#说明栈中元素是空的,也就是没有路径
return False
matche(1,1,8,8)缺点:路径不一定是最短的
队列解决——广度优先搜索(最短)
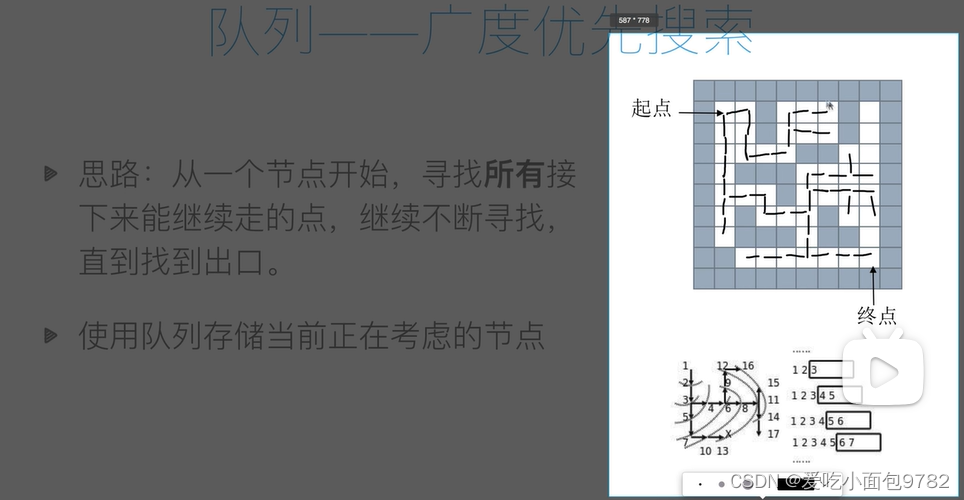
from collections import deque
mach=[
[1,1,1,1,1,1,1,1,1,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,0,0,1,1,0,0,1],
[1,0,1,1,1,0,0,0,0,1],
[1,0,0,0,1,0,0,0,0,1],
[1,0,1,0,0,0,1,0,0,1],
[1,0,1,1,1,0,1,1,0,1],
[1,1,0,0,0,0,0,0,0,1],
[1,1,1,1,1,1,1,1,1,1]
]
def print_(path):
curNode=path[-1]#当curNode到达终点时,由于同时把curNode也存在path里面,所以path的最后一个元素就是curNode
realpath=[]
while curNode[2]!=-1:
realpath.append((curNode[0],curNode[1]))
curNode=path[curNode[2]]
realpath.append((curNode[0], curNode[1]))
realpath.reverse()
for i in realpath:
print(i)
dics=[
lambda x,y:(x-1,y),#上面元素
lambda x,y:(x+1,y),#下面元素
lambda x,y:(x,y-1),#左边元素
lambda x,y:(x,y+1)#右边元素
]
def matche(x1,y1,x2,y2):
queue=deque()#创建一个队列
queue.append((x1,y1,-1))#把起点放进队列,注意还要把上一个元素的标号放进去
path=[]
while len(queue)>0:#确保队列不空
curNode = queue.pop() # 当前的节点在队首
path.append(curNode)
if curNode[0]==x2 and curNode[1]==y2:#走到终点了,说明该结束了,需要输出整个路径
print_(path)
return True
for dic in dics:
nextNode = dic(curNode[0],curNode[1])#下一个节点
if mach[nextNode[0]][nextNode[1]]==0:#说明存在下一个路点
queue.append((nextNode[0],nextNode[1],len(path)-1))#
mach[nextNode[0]][nextNode[1]] = 2#保证单次路径中走过的路不会再走
else:#说明栈中元素是空的,也就是没有路径
return False
matche(1,1,8,8)链表
#手动创建链表
class Node:
def __init__(self,item):
self.item=item
self.next=None
a=Node(1)
b=Node(2)
c=Node(3)
a.next=b
b.next=c
print(a.next.item)#头插法创建链表,输出列表为倒序
class Node:
def __init__(self,item):
self.item=item
self.next =None
def creat_linelink(ls):
head=Node(ls[0])
for element in ls[1:]:
node=Node(element)
node.next=head
head=node
return head
def print_link(lk):
while lk:
print(lk.item,end=' ')
lk=lk.next
lk=creat_linelink([1,2,3])
print_link(lk)#尾插法创建链表,输出列表为正序
class Node:
def __init__(self,item):
self.item=item
self.next=None
def creat_linetail(ls):
head=Node(ls[0])
tail=head
for element in ls[1:]:
node=Node(element)#插入的元素
tail.next=node
tail=node
return head
def print_(lk):
while lk:
print(lk.item,end=' ')
lk=lk.next
lk=creat_linetail([1,2,3])
print_(lk)# 链表节点的插入
p.next=curNode.next
curNode.next=p
#链表节点的删除
p=curNode.next
curNode.next=curNode.next.next
del p#双链表的定义
class Node(object):
def __init__(self,item=None):
self.item=item
self.next=None
self.prior=None
#双链表的插入
p.next=curNode.next
curNode.next.prior=p
p.prior=curNode
curNode.next=p
#双链表的删除
p=curNode.next
curNode.next=p.next
p.next.prior=curNode
del p总结:
时间复杂度:
按元素查找、插入和删除中顺序表(列表/数组,O(n))要比链表慢O(1)
如果按照下标查找,则前者快O(1),但链表是O(n)
相比于顺序表,链表只要可以一直next下去就不会满
哈希表
存储原理:假如哈希表长度为7,则哈希函数h(k)=k%7(除法哈希),然后放进相应的存储空间内
如果当前空间已经有元素,则应该把当前元素向后储存,解决办法(开放寻址法)有:
1.线性探查,即按照i+1,i+2.......
2.二次探查,即按照i+1(平方),i-1(平方),i+2(平方),i-2(平方).....
拉链法
哈希表每个位置都连接一个链表,当冲突发生后,将冲突元素加到该位置链表的最后
哈希表的实现
树
class Node:
def __init__(self,name,type='dir'):
self.name=name
self.type=type
self.children=[]
self.parent=None
def __repr__(self):
return self.name
class FileSystemtree:
def __init__(self):
self.root=Node("/")
self.now=self.root
def mk(self, name):
if name[-1] != "/":
name += "/"
node = Node(name)
self.now.children.append(node)
node.parent = self.now
def ls(self):
return self.now.children
def cd(self,name):
if name[-1] != "/":
name+="/"
for child in self.now.children:
if child.name==name:
self.now=child
return
tree=FileSystemtree()
tree.mk("val/")
tree.mk("mer/")
tree.mk("cdf/")
tree.cd("bin/")
tree.mk("Python/")
print(tree.ls())二叉树
from collections import deque
#二叉树的定义
class bitreeNode:
def __init__(self,data):
self.data=data
self.lchild=None
self.rchild = None
a=bitreeNode("A")
b=bitreeNode("B")
c=bitreeNode("C")
d=bitreeNode("D")
e=bitreeNode("E")
f=bitreeNode("F")
g=bitreeNode("G")
e.lchild=a
e.rchild=g
a.rchild=c
c.lchild=b
c.rchild=d
g.rchild=f
root=e
# print(root.lchild.rchild.data)
#前序遍历
def pre_order(root):
if root:
print(root.data,end=' ')
pre_order(root.lchild)
pre_order(root.rchild)
pre_order(root)
print('/t')
#中序遍历
def in_order(root):
if root:
in_order(root.lchild)
print(root.data,end=' ')
in_order(root.rchild)
in_order(root)
print('/t')
#后序遍历
def post_order(root):
if root:
post_order(root.lchild)
post_order(root.rchild)
print(root.data, end=' ')
post_order(root)
print('/t')
#层次遍历
def level_order(root):
queue=deque()
queue.append(root)
while len(queue)>0:
node=queue.popleft()
print(node.data,end=' ')
if node.lchild:
queue.append(node.lchild)
if node.rchild:
queue.append(node.rchild)
level_order(root)二叉搜索树
特点:左边节点要比右边节点小
二叉搜索树的插入
class bitreeNode:
def __init__(self,data):
self.data=data
self.lchild=None
self.rchild = None
self.parent=None
class BST:
def __init__(self,ls=None):
self.root=None
if ls:
for val in ls:
self.insert_(val)
def insert(self,node,val):#利用递归
if not node:#即node为空
node=bitreeNode(val)
elif val<node.data:
node.lchild=insert(node.lchild,val)
node.lchild.parent=node
elif val>node.data:
node.rchild = insert(node.rchild, val)
node.rchild.parent = node
return node
def insert_(self,val):#用循环不用递归
p=self.root
if not p:
self.root=bitreeNode(val)
return
while True:
if val<p.data:
if p.lchild:
p=p.lchild
else:
p.lchild=bitreeNode(val)
p.lchild.parent=p
return
elif val>p.data:
if p.rchild:
p=p.rchild
else:
p.rchild = bitreeNode(val)
p.rchild.parent = p
return
else:
return
# 前序遍历
def pre_order(self,root):
if root:
print(root.data, end=' ')
self.pre_order(root.lchild)
self.pre_order(root.rchild)
# 中序遍历
def in_order(self,root):
if root:
self.in_order(root.lchild)
print(root.data, end=' ')
self.in_order(root.rchild)
# 后序遍历
def post_order(self,root):
if root:
self.post_order(root.lchild)
self.post_order(root.rchild)
print(root.data, end=' ')
tree=BST([4,6,7,9,2,1,3,5,8])
tree.pre_order(tree.root)
print("")
tree.in_order(tree.root)#二叉搜索树的中序序列是有序的
print("")
tree.post_order(tree.root)二叉搜索树的查询
def query(self,node,val):#递归版查询
if not node:#找不到
return None
if val<node.data:
return self.query(node.lchild,val)
if val>node.data:
return self.query(node.rchild,val)
else:
return node.data
def query_(self,val):#非递归版本查询
p=self.root
while p:
if val<p.data:
p=p.lchild
elif val>p.data:
p=p.rchild
else:
return p
return None二叉搜索树的删除

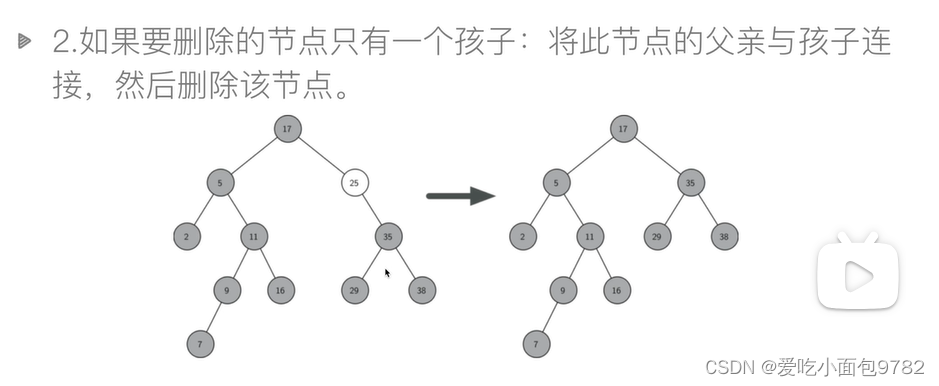
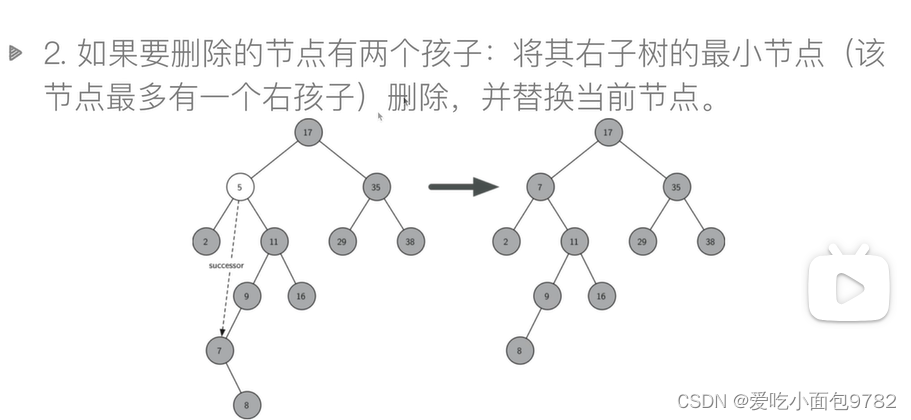
def remove_node_1(self,node):#node是叶子结点的情况
if not node.parent:#是叶子结点同时是根节点
self.root=None
if node==node.parent.lchild:#是叶子结点同时是左孩子
node.parent.lchild=None
else:#是叶子结点同时是右孩子
node.parent.rchild = None
def remove_node_21(self,node):#node只有一个孩子的情况
#如果只有一个左孩子
if not node.parent:#只有一个左孩子并且删除节点是根节点
self.root=node.lchild#根节点变为左孩子
node.lchild.parent=None#把根节点删除
elif node==node.parent.lchild:
node.parent.lchild=node.lchild#此时node只有一个左孩子,应该把node的左孩子和node的父亲连起来
node.lchild.parent = node.parent
else:#如果需要删除的节点是父亲的右孩子
node.parent.rchild = node.lchild
node.lchild.parent = node.parent
def remove_node_22(self,node):#node只有一个孩子的情况
# 如果只有一个右孩子
if not node.parent: # 只有一个右孩子并且删除节点是根节点
self.root = node.rchild # 根节点变为右孩子
node.rchild.parent = None # 把根节点删除
elif node == node.parent.lchild:
node.parent.lchild = node.rchild # 此时node只有一个右孩子,应该把node的右孩子和node的父亲连起来
node.rchild.parent = node.parent
else: # 如果需要删除的节点是父亲的右孩子
node.parent.rchild = node.rchild
node.rchild.parent = node.parent
def delete(self,val):
if self.root:#存在根节点
node=query_(val)#间接查找
if not node:#如果不存在
return False
if not node.lchild and not node.rchild:#如果既没有左孩子也没有右孩子
self.remove_node_1(node)
elif not node.rchild:
self.remove_node_21(node)
elif not node.lchild:
self.remove_node_22(node)
else:#两个孩子都有
min_node=node.rchild
while min_node:
min_node=min_node.lchild
node.data=min_node.data#覆盖值
#删除min_node
if min_node.rchild:
self.remove_node_22(min_node)
else:
self.remove_node_1(min_node)贪心算法
背包问题
对于0-1背包和分数背包,0-1背包不能用贪心算法,因为可能为了满足单位价值导致最后的总价值很低,但分数背包可以
goods=[(60,10),(100,20),(120,30)]
def fg(goods,w):
m=[0 for _ in range(len(goods))]
goods.sort(key=lambda x:x[0]/x[1],reverse=True)
total_=0
for i,(price,weight) in enumerate(goods):
if w>=weight:
m[i]=1
total_+=price
w-=weight
else:
m[i]=w/weight
total_+=m[i]*price
w=0
break
return total_,m
print(fg(goods,50))拼接最大数字问题
from functools import cmp_to_key
def xy_(x,y):
if x+y<y+x:
return 1
elif x+y>y+x:
return -1
else:
return 0
def fg(ls):
ls=list(map(str,ls))
ls.sort(key=cmp_to_key(xy_))
return"".join(ls)
ls=[32,94,128,1286,6,71]
print(fg(ls))活动选择问题
a=[(1,4),(3,5),(0,6),(5,7),(3,9),(5,9),(6,10),(8,11),(8,12),(2,14),(12,16)]
a.sort(key=lambda x:x[1])
def fg(a):
res=[a[0]]#用来储存结果
for i in range(1,len(a)):
if a[i][0]>res[-1][1]:#如果要检验的活动的开始时间比已经存在里面的活动的结束时间晚
res.append(a[i])
return res
print(fg(a))动态规划
从斐波那契看动态规划
#递归写法:
def fg(n):
if n==1 or n==2:
return 1
else:
return fg(n-1)+fg(n-2)
print(fg(5))
#但是由于子问题的重复计算,导致运行效率很低
#动态规划=递归+重复子问题
def fg(n):
f=[0,1,1]
if n>2:
for i in range(n-2):
num=f[-1]+f[-2]
f.append(num)
return f[n]
print(fg(100))钢条切割问题


p=[0,1,5,8,9,10,17,17,20,24,30]
def fg(p,n):
if n==0:
return 0
else:
res=p[n]
for i in range(1,n):
res = max(res, fg(p, i)+fg(p,n-i))#rn=max(pn,r1+rn-1,r2+rn-2......)
return res
print(fg(p,9))
#因为用到递归所以会很慢
def fg2(p,n):
if n==0:
return 0
else:
res=0
for i in range(1,n+1):
res=max(res,p[i]+fg2(p,n-i))# rn=max(pi+rn-i)(1<=i<=n)
return res
print(fg(p,9))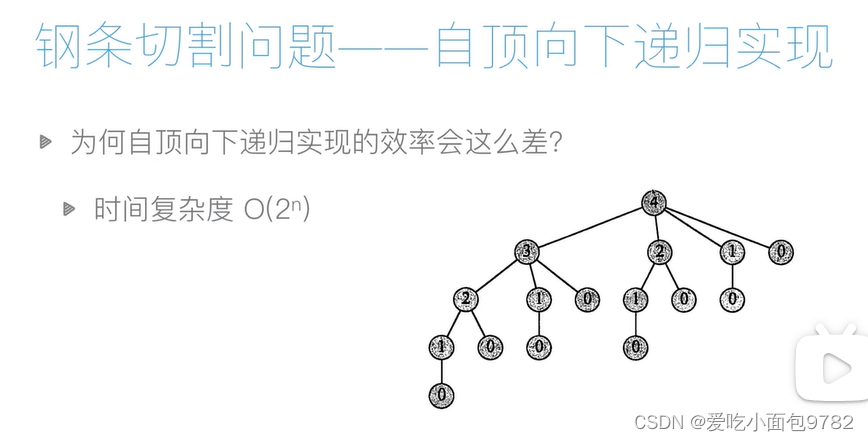
def fg(p,n):
r=[0]
for i in range(1,n+1):
res = 0
for j in range(1,i+1):
res=max(res,p[j]+r[i-j])
r.append(res)
return r[n]
p=[0,1,5,8,9,10,17,17,20,24,30]
print(fg(p,6))
问:如何输出整个最优切割方案?
def fg(p,n):
r=[0]
s=[0]
for i in range(1,n+1):
res_r=0#价格的最大值
res_s=0#价格最大值对应的最优解
for j in range(1,i+1):
if res_r<p[j]+r[i-j]:
res_r=p[j]+r[i-j]
res_s=j
r.append(res_r)
s.append(res_s)
return r[n],s
def fg1(p,n):
r,s=fg(p,n)
nus=[]
while n>0:
nus.append(s[n])
n-=s[n]
return nus
p=[0,1,5,8,9,10,17,17,20,24,30]
print(fg1(p,9))
最长公共子序列


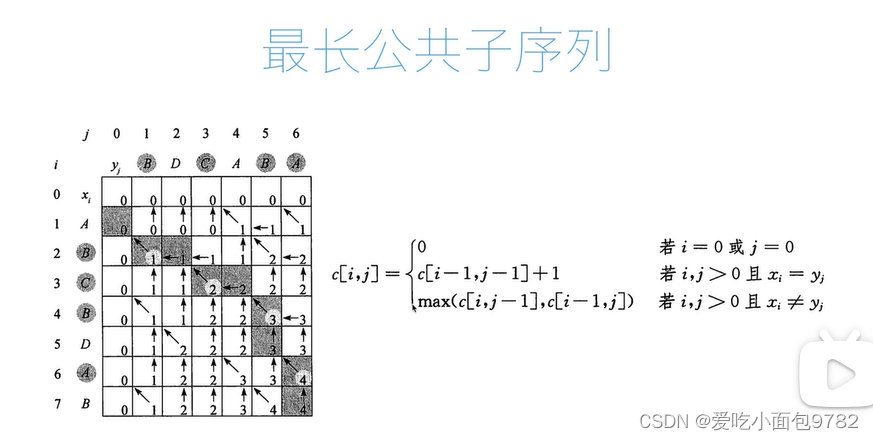
def lcs(x,y):
m=len(x)
n=len(y)
c=[[0 for _ in range(n+1)]for _ in range(m+1)]
b=[[0 for _ in range(n+1)]for _ in range(m+1)]
for i in range(1,m+1):
for j in range(1,n+1):
if x[i-1]==y[j-1]:
c[i][j]=c[i-1][j-1]+1
b[i][j]=1#左上方
elif c[i-1][j]>c[i][j-1]:
c[i][j]==c[i-1][j]
b[i][j]=2#上方
else:
c[i][j]==c[i][j-1]
b[i][j]=3#左方
return c[m][n],b
def trace(x,y):
c,b=lcs(x,y)
num=[]
i=len(x)
j=len(y)
while i>0 and j>0:
if b[i][j]==1:
num.append(x[i-1])
elif b[i][j]==2:
i-=1
else:
j-=1
return"".join(reversed(num))
print(trace("ABCBDAB","BDCABA"))欧几里得算法(求最大公约数辗转相除法)
# 利用欧几里得进行约分
class Fraction:
def __init__(self,a,b):
self.a=a
self.b = b
x=self.gcd(a,b)
self.a/=x
self.b /= x
@staticmethod
def gcd(a,b):
while b > 0:
r = a % b
a = b
b = r
return a
def __str__(self):
return "%d/%d" % (self.a, self.b)
f=Fraction(30,16)
print(f)
# 利用欧几里得进行分数相加
class Fraction:
def __init__(self,a,b):
self.a=a
self.b = b
x=self.gcd(a,b)
self.a/=x
self.b /= x
def gcd(self,a,b):
while b > 0:
r = a % b
a = b
b = r
return a
def zbs(self,a,b):
x=self.gcd(a,b)
return x*(a/x)*(b/x)
def __add__(self,other):
a=self.a
b=self.b
c=other.a
d=other.b
fenmu=self.zbs(b,d)
fenzi=a*(fenmu/b)+c*(fenmu/d)
return Fraction(fenzi,fenmu)
def __str__(self):
return "%d/%d" % (self.a, self.b)
a=Fraction(1,2)
b=Fraction(2,3)
print(a+b)RSA加密算法




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









