






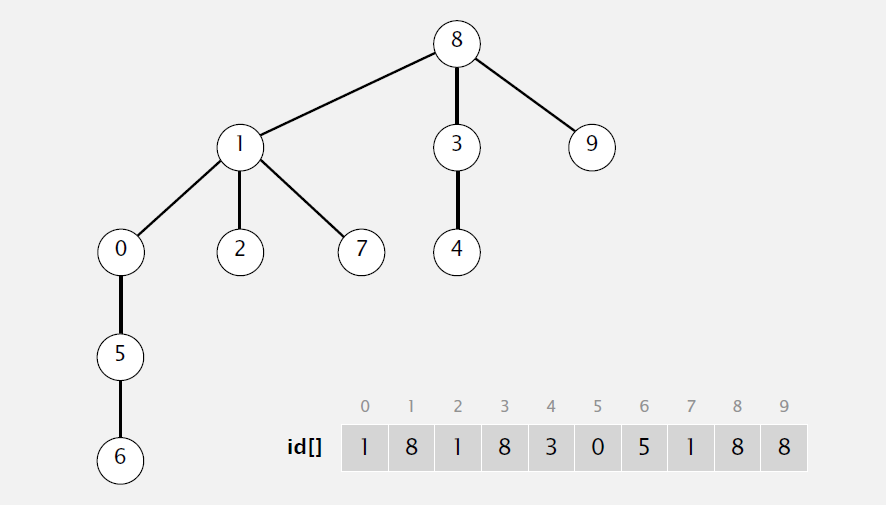
###1. 概念
- 触点:区域内的点
- 连接:点与点之间的连接。
- 分量:区域内部分相互连通的所有点构成一个分量,整个区域可以划分为多个分量(包含互相联通的点)
| 概念 | 举例 |
|---|---|
| 触点 | 0、1、2…… |
| 连接 | 0-1,1-2,3-4…… |
| 分量 | {0、1、2、5、6、7},{3、4、8、9} |
 | |
###2. API
public class UF |
|---|
| UF | 构造方法 |
|---|---|---|
int | find(p) | 找到当前触点p所属分量 |
void | union(p,q) | 将p,q合并到同一分量 |
boolean | connected(p,q) | 验证p,q是否属于同一分量 |
int | count() | 计算当前分量个数 |
find和union方法是决定算法运算量的重点 | ||
###3. 模型实现
代码
import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut;
public class UF {
private int[] id;
private int count;
public UF(int N){
for(int i=0;i<N;i++){
id[i]=i;
}
}
//见后章节
public int find(int p){}
public void union(int p,int q){}
public boolean connected(int p,int q){
return find(p)==find(q);
}
public int count(){
return count;
}
public static void main(String[] args){
int N = StdIn.readInt();
UF uf = new UF(N);
while(!StdIn.isEmpty()){
int p = StdIn.readInt();
int q = StdIn.readInt();
if(uf.connected(p,q)){
continue;
}
uf.union(p,q);
StdOut.printf(p+" "+q);//打印出来的都是原本没联通,刚刚建立联通的
}
StdOut.printf(uf.count()+"components");
}
}
###4. quick-find算法
find及union方法代码
//QuickFind算法
public int find(int p){
return id[p];//find只需要一步
}
public void union(int p,int q){
int pid = find(p);
int qid = find(q);
if(pid == qid){return;}
//数据量最大处
for(int i=0;i<id.length;i++){
if(id[i] == pid){id[i] = qid;}
}
count--;
}
- 特点:find速度快,union速度慢
- 思路:id标号储存触点编号,id内容储存分量编号,find指令只需要返回id特定标号下的内容。union指令将id中内容变更即可。
- 缺点:quick-find算法属于N方级算法,运行速度慢。find方法已经满足要求,但是union方法对数组的访问较大,需要提出一种新的方法来减小union方法的计算量。
###5. quick-union算法 find及union方法代码
//QuickUnion算法
public int find(int p){
//数据量最大处
while(id[p]!=p){p=id[p];}
return p;
}
public void union(int p,int q){
int pid = find(p);
int qid = find(q);
if(pid==qid){return;}
id[pid]=qid;//union只需要一步
count--;
}
- 特点:find速度慢,union速度快。与quick-find算法相比,减少了中union操作遍历整个·数组的计算量。使用单链表可以排除无关元素无需进行遍历搜索,减少了union的计算量
- 思路:id标号储存触点编号,id内容储存上级触点编号,find指令使用循环返回p最上层根触点编号,union指令使p的根节点指向q的根节点
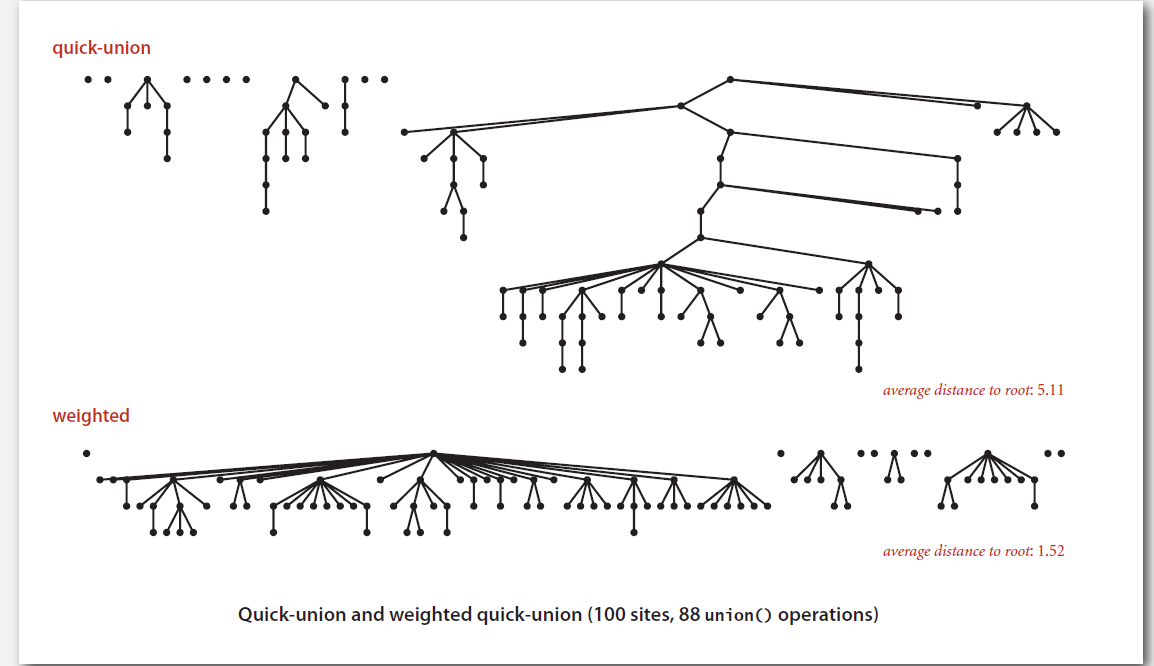
- 缺点:虽然使用单链表方式能够大大减少union方法的计算量,但是这种方式也在一定程度上增大了find方法的计算量。如果在union过程中出现瘦高树,则会大大加大find的运算量,所以在实际运算过程中,quick-union算法的实际效率并不一定比quick-find算法效率高。因此如果有一种能够解决瘦高树问题的算法,则find和union方法的效率都将大大提升。
###6. 加权quick-union算法
find及union方法代码以及sz定义
private int[] id;
private int count;
private int[] sz;//代表根节点引领树的大小(非根节点处数字没有意义)
public WeightedQuickUnionUF(int N){
count = N;
id = new int[N];
for(int i=0;i<N;i++){id[i]=i;}
sz = new int[N];
for(int i=0;i<N;i++){sz[i]=1;}
}
//加权QuickUnion算法
public int find(int p){
while(id[p]!=p){p=id[p];}
return p;
}
public void union(int p,int q){
int pid = find(p);
int qid = find(q);
if(pid==qid){return;}
if(sz[pid]<sz[qid]){ id[pid]=qid; sz[qid]=sz[pid]+sz[qid];}
else{ id[qid]=pid; sz[pid]=sz[pid]+sz[qid];}
count--;
}
- 特点:对于N个节点,树高最大为lgN,相比quick-union算法,加权quick-union算法避免了瘦高树的形成,减少了find方法的计算量,同时union方法计算量与quick-union算法的union方法计算量类似,提高了效率
- 思路:为了保证不会生成瘦高树,只需要保证大树总是主树,小树总是在下方即可。此时只需要多一个数组sz,用于记录各树的大小,在合并前比较两棵树的大小即可
###7. 路径压缩的加权quick-union算法 find及union方法代码
public int find(int p){
while(id[p]!=p){
id[p]=id[id[p]];//如果p不是根节点,就让他指向倒数第二级节点
p=id[p];//直接找到倒数第二级节点
}
return p;
}
- 思路:在find方法中添加一行代码,使得在寻找根节点的过程中,如果某个节点本身不是根节点,则让他指向上级节点的上级节点,隔层压缩。最终会使所有分支节点都将连接在根节点上
- 本质:使所有分支节点直接连接在根节点上,这样find方法最多只需要搜寻两层,而不需要搜寻lgN层。而union算法又可以与quick-union方法中的union方法般高效,进一步提升了计算效率。
###8. 比较
|
|—|—|—|—|
|quick-find算法|触点标号|分量标号|find快,union慢|
|quick-union算法|触点标号|上级节点标号|单链表,find慢,union快|
|加权quick-union算法|触点标号|上级节点标号|避免瘦高树的生成,find提速|
|路径压缩的加权quick-union算法|触点标号|(不断变更的)上级节点编号|以常数级计算量置换更高效率|


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









