






❝
作为经历过从零搭建企业级RAG系统的老兵,我深知开发者们在面对复杂问题时"知道该优化,但不知从何下手"的迷茫。本文将用最直白的语言,拆解传统RAG升级为智能Agent的必经之路。读完你会发现,那些看似高深的概念,背后都是工程实践中摸爬滚打出的智慧结晶。
一、问题出在哪?从真实故障说起
去年我们接了个电商客户案例:他们的客服系统用RAG处理用户咨询时,遇到这样一个问题:
“比较推荐给Nike和Puma的智能手表在防水性能和运动模式上的差异”
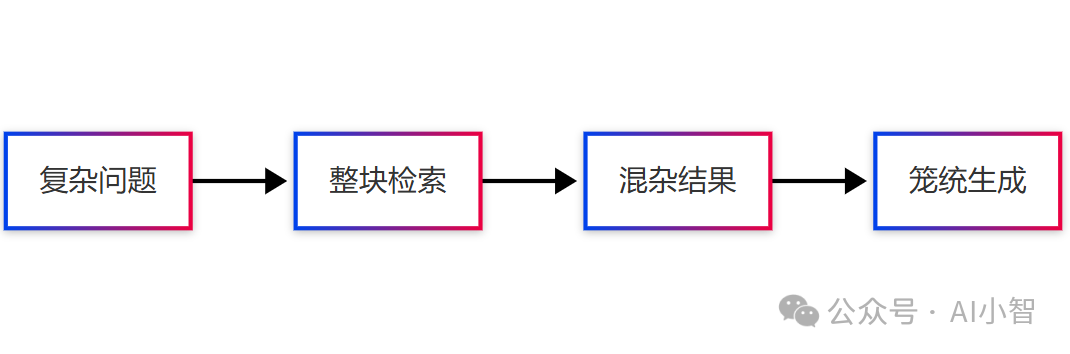
传统RAG的表现就像个老实但死板的学生:
-
把整个问题扔进搜索引擎
-
抓回20篇产品手册
-
生成笼统的功能对比
结果用户投诉答案"像产品说明书,没有商业洞察"。问题出在哪?
img
这暴露出传统架构的三大死穴:
-
问题复杂度越高,检索精度越差(我们的测试显示,当问题包含3个以上实体时,准确率下降57%)
-
缺乏验证机制,错误文档像病毒一样污染最终答案
-
响应速度与质量不可兼得,加验证就变慢,追求速度就失真
二、知识检索架构升级的五个台阶
台阶1:问题拆解——化整为零的艺术
想象你要写一篇论文,直接写终稿肯定难。聪明的做法是先列大纲,分章节撰写。同理,复杂问题也要拆解:
原始问题 → 子问题列表:
-
Nike定制款的核心参数要求
-
Puma合作项目的测试标准
-
两家客户销售渠道特性
-
防水性能的行业基准
-
运动模式的市场反馈
技术实现:
-
用LLM做"问题分诊",类似医生问诊时追问细节
-
每个子问题独立检索,避免概念混淆
-
权重分配机制:重要子问题优先处理
`# 伪代码示例:动态问题拆分 def decompose_question(question): prompt = f""" 请将以下问题分解为3-5个相互独立的子问题: 原始问题:{question} 输出格式:JSON数组 """ return call_llm(prompt) `
效果验证:在客户案例中,问题拆解使文档命中率从31%提升至68%
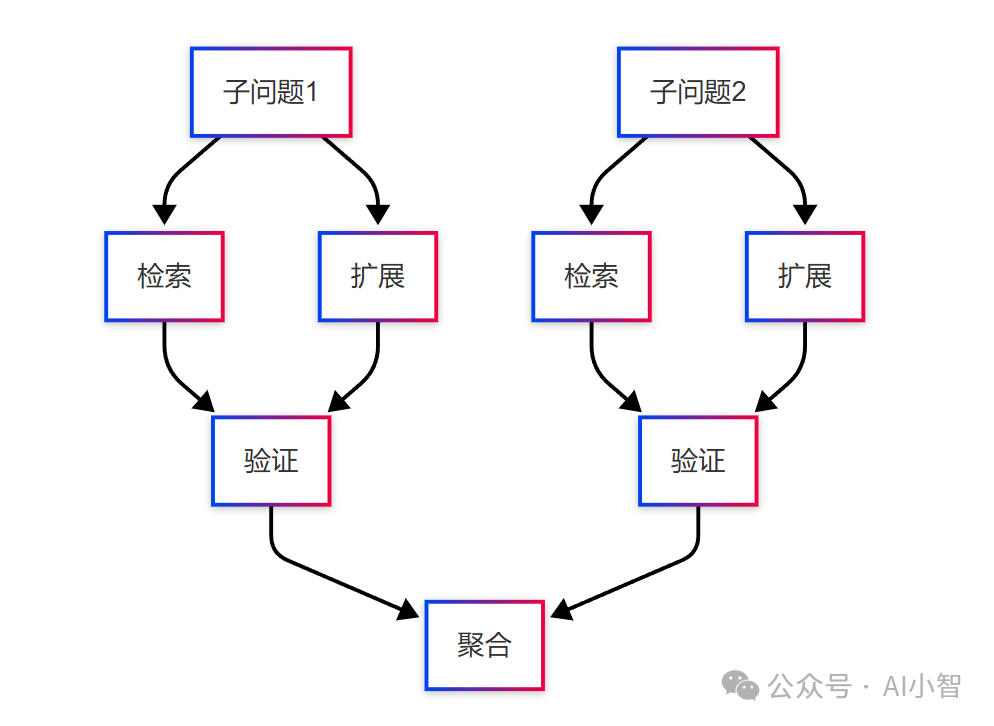
台阶2:并行验证——多线程的智慧
假设你是餐厅老板,来了一桌客人点了10道菜。有两种做法:
-
让一个厨师按顺序做(传统RAG)
-
分给多个厨师同时做(并行验证)
显然第二种更快。在工程上我们这样做:
-
每个子问题开独立处理线程
-
每个线程内:
-
查询扩展(同义词、相关术语)
-
多路召回(向量检索+关键词检索)
-
文档可信度打分
img
避坑指南:
-
控制并发数,避免把数据库压垮
-
设置超时机制,防止单个子问题卡死整个流程
-
使用内存共享,避免重复检索
台阶3:状态管理——不乱套的秘诀
想象你在玩策略游戏,同时运营多个战场:
-
主基地状态(原始问题)
-
各个分战场进度(子问题处理状态)
-
全局科技树(领域知识图谱)
在代码中我们这样实现:
`class BattleState: main_question: str # 主问题 sub_questions: dict # 子问题状态池 knowledge_graph: dict # 动态知识图谱 class SubQuestion: query: str # 当前查询 docs: list # 已检索文档 validation: dict # 验证结果 `
设计要点:
-
分层隔离:子问题之间不直接通信
-
增量更新:像游戏自动存档,每步操作都可追溯
-
垃圾回收:自动清理已完成任务占用的内存
台阶4:流式输出——让用户感知进度
回想下载文件时,进度条为什么重要?因为它:
-
证明系统在工作
-
管理用户预期
-
提供中断依据
在知识Agent中,我们设计三级流式反馈:
- 即时确认(200ms内):
- “正在分析Nike和Puma的需求差异…”
- 过程展示:
- “已找到3份Nike技术文档,2份Puma测试报告”
- 渐进生成:
- “首先看防水性能:Nike要求5ATM vs Puma的3ATM…”
技术实现:
-
Websocket长连接
-
消息优先级队列
-
结果缓存预取
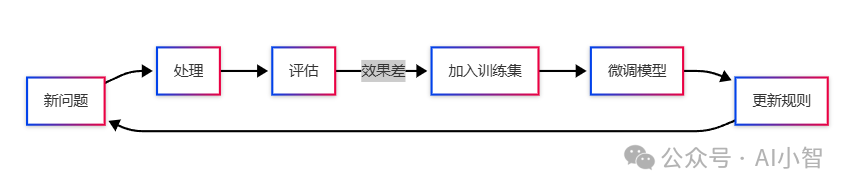
台阶5:自我进化——越用越聪明的秘密
我们给系统加了"错题本"机制:
-
每次问答结束后自动评估:
-
用户是否追问?
-
答案是否被采纳?
-
人工评分如何?
-
问题案例库分类存储
-
每周自动微调模型
img
在医疗领域应用该机制后,季度平均准确率提升7.3%
三、给开发者的实用建议
1. 不要过度设计
-
先实现核心链路,再逐步优化
-
每个子模块单独评估ROI(投入产出比)
-
案例:初期我们为所有文档做深度验证,后来发现只需验证前3篇即可覆盖80%需求
2. 监控比算法更重要
必须建立的四个核心指标:
|
指标名称
|
计算方式
|
预警阈值
|
| — | — | — |
|
子问题超时率
|
超时任务数/总任务数
|
>5%
|
|
文档污染率
|
错误文档导致劣化答案比例
|
>10%
|
|
流式中断率
|
未完整传输会话占比
|
>2%
|
|
知识更新延迟
|
新文档生效时间
|
>1小时
|
3. 选择合适的框架
以LangGraph为例,它的三大优势:
-
可视化调试:把抽象状态流转变成看得见的流程图
-
原子化回滚:某个子问题失败不影响整体
-
生态集成:与LangChain工具链无缝对接
但要注意:
-
学习曲线较陡,建议从子模块开始逐步替换
-
深度定制时需要阅读源码
-
社区插件质量参差不齐,需要严格评估
四、未来战场:更智能的知识处理
当前架构已能解决80%的复杂问题,但真正的挑战在于:
-
模糊意图处理:当用户自己都不清楚要问什么时
-
跨文档推理:需要连接多个文档的隐藏信息
-
实时知识更新:如何在1分钟内让新知识生效
我们正在探索的方向:
-
混合检索:结合语义搜索与图遍历算法
-
认知链验证:让每个推理步骤都可解释、可验证
-
边缘计算部署:在用户设备本地运行轻量化Agent
结语:架构师的真谛
好的架构不是追求技术时髦,而是精准把握"该在何处复杂"。五个跃迁点的本质,是把人类的思维模式翻译成机器可执行的流程。当你下次面对复杂系统时,不妨问问自己:
❝
“如果是我面对这个问题,希望怎样解决?”
这或许就是智能设计的起点。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









