






贪心算法:区间选点 贪心:短视的一个行为,每次选点只看当前点的占据数量最大 ———局部最优解
AcWing 905区间选点
1将每个区间按右端点从小到大排序
2从前往后依次枚举每个区间 (查看右端点,右端点占据的区间数量比较多) 如果当前区间已经被包含点,则直接pass,否则选择当前区间的右端点。
证明ans
证明ans>=cnt : cnt可行方案是一个区间集合,区间从小到大排序,两两之间不相交。
所以覆盖每一个区间至少需要cnt个点。 (证明得出的解就是答案的论证过程)AcWing 905. 区间选点 - AcWing
2 AcWing 908最大不相交区间数量
证明ans
证明ans>=cnt 因为重点是我们排序的时候是把每个端点的右边作为排序条件的。所以就第一个选择的左端点就不会存在说第一个端点中包含了第二个端点,因为第一个是把每个端点的右边作为排序条件的
3AcWing 906 区间分组
1将每个区间的左端点从小到大排序(可以理解为是为了让每个组的区间都更加紧密,避免浪费空间。如果按照右端点进行排序的话,由于不知道左端点的位置,可能会造成同一组之间差距过大,导致空间的浪费,最后导致组的数目大于正确答案。
2 从前往后处理每个区间 判断能否将其放到某个现有的组中(看某一组的最后一个右端点是否大于新区间的左端点,如果大于,则不能放置,如果小于,则新区间就可以放置到该组中,同时这个组的最后一个右端点进行更新。
3AcWing 907区间覆盖
1将所有区间按左端点从小到达排序
2从前往后依次枚举每个区间,在所有的能覆盖start的区间中,选择右端点最大的区间,然后将start更新成右端点的最大值
接下来可以简单证明ans == cnt 可以通过前面设置的条件找到的cnt,然后把cnt一步步的转换成ans,得出ant>=cnt

Huffman树
AcWing_148_合并果子 只需要用一个优先队列就能写出来了
AcWing_913_排队打水
n个人打水,打水的时间各不相同,如何安排他们的打水顺序,才能够使所有人的的等待时间最少?
AcWing_104_货仓选址
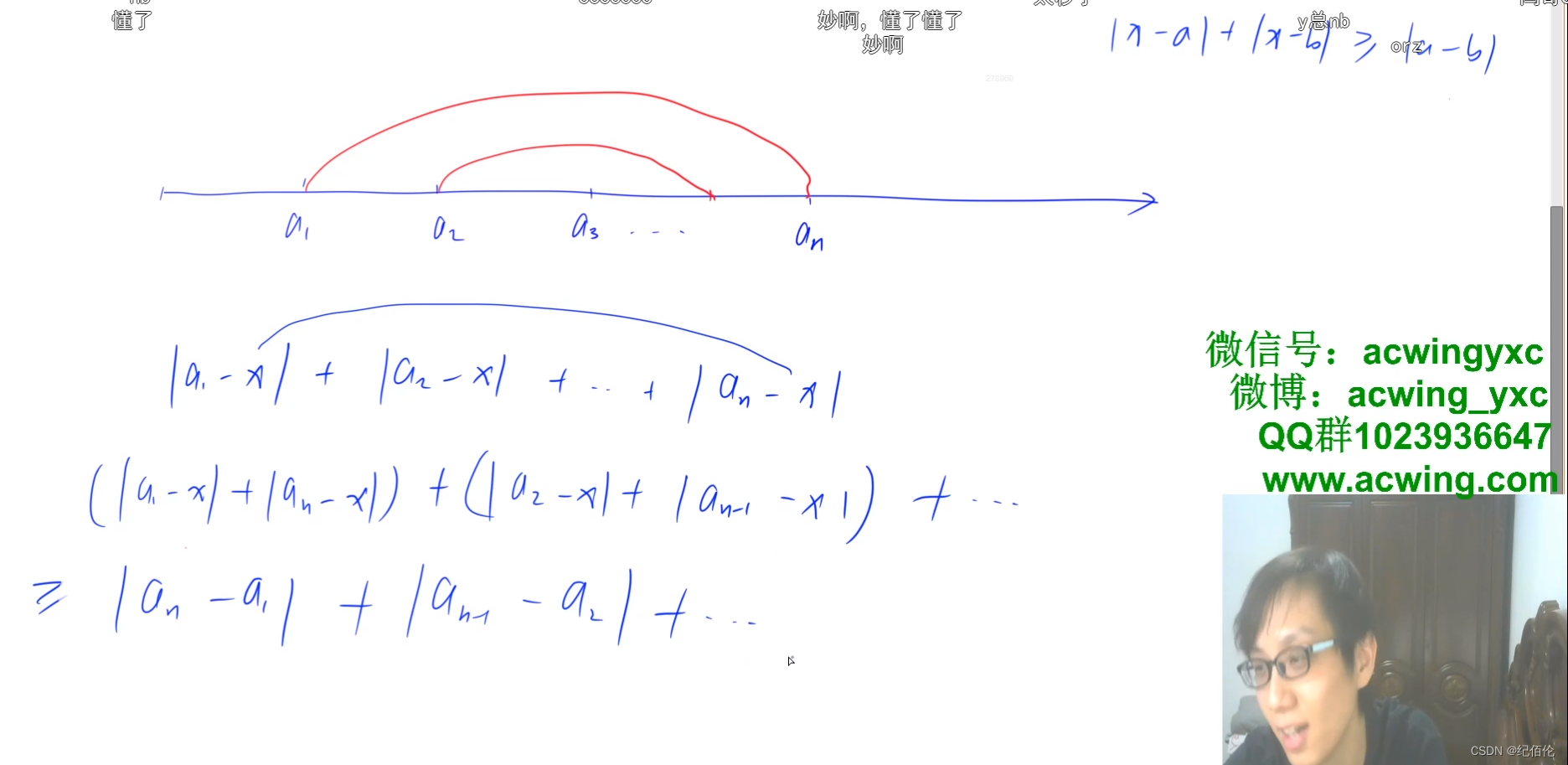
即一个数组,然后在数轴中选择一个点,然后来回走,直到经过了所有的点,问走的最短路程是多少,用的是右上角的哪一个不等式来解决的,之后就把数轴上的点两两相结合 ,然后a1和an结合,一直到最小的中间,如果是奇数个,最后刚好·1剩下一个点,n/2,如果是偶数的话,中间两个点,任选一个就好。
AcWing_125_耍杂技的牛
n头牛玩叠罗汉根据Scanner会给他们各自的重量以及承受力,然后每头牛的风险就是它的头顶的重量减去它的风险,如何排序n头牛来让风险最小的?所以最下面的牛就应该是重量最大且承受力最强大的? 应该尝试模拟,来推断一个数学公式,严谨的得出答案,先动笔,思路就会慢慢出现。

y总所推断

如果是这样写的排序,然后写了自定义排序方法的话,在return中记得写括号。来让编译器分的清除,,
Arrays.sort(arr, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
return (o1[0]+o1[1]) - (o2[0]+o2[1]);
}
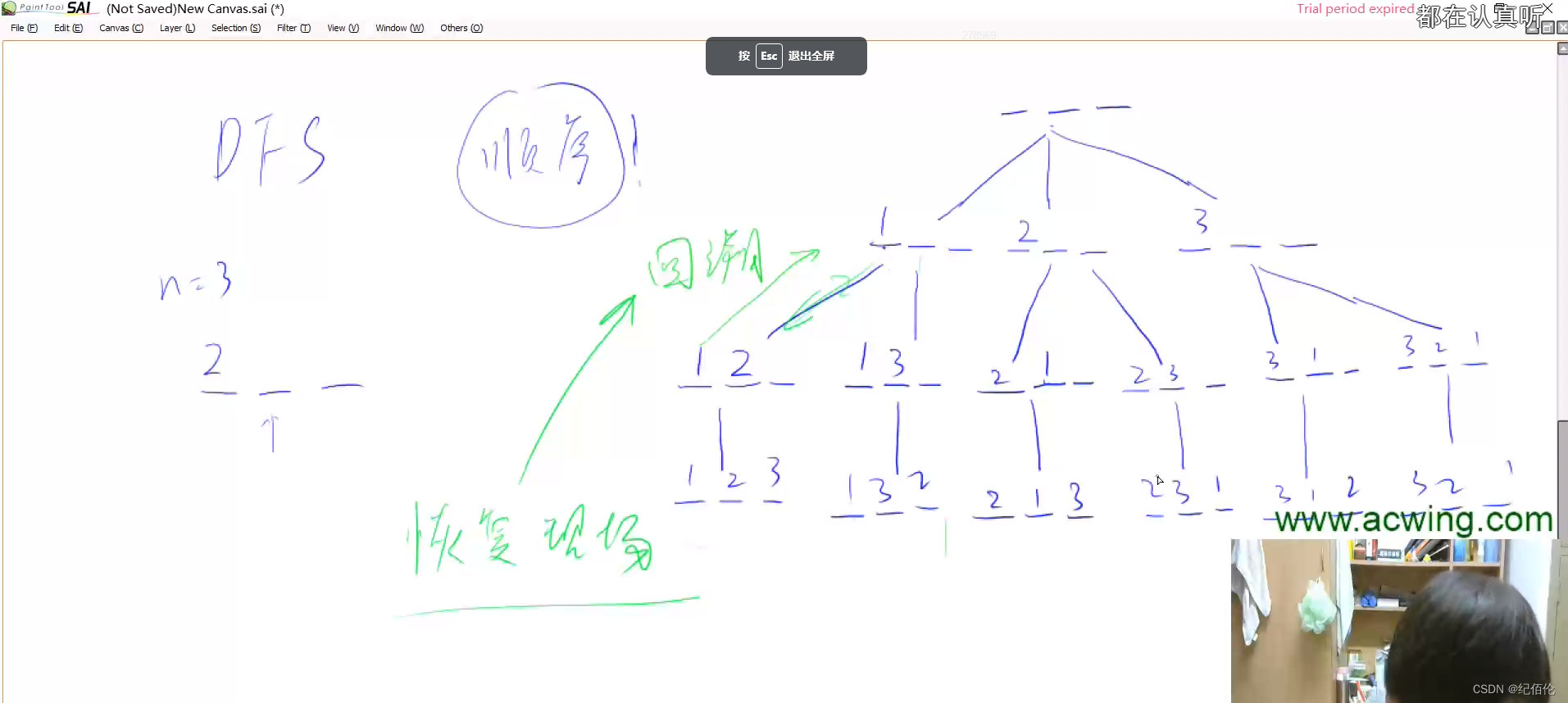
});AcWing_dfs1_842_排列数字
回溯+递归,注意当回溯的时候要恢复现场
AcWing_dfs2_843_n皇后问题
dfs函数,每次调用都是往里面深入的走了一层,然后当在循环中调用dfs函数的之后也就是这一层的回溯已经完成,所以需要把它的现场也回溯,就是把几个数组的值恢复原貌
for (int j = 0; j < n; j++) {
if(!col[j] && !dg[j + i] && !udg[n - i + j]){
g[i][j] = 'Q';
col[j] = dg[j + i] = udg[n - i + j] = true;
dfs(i+1);
col[j] = dg[j + i] = udg[n - i + j] = false;
g[i][j] = '.';
}
}这是另外一种方法,其中if(x == n) 的判断中的return是很重要的,因为调用dfs递归的地方并不是在for循环中,所以有可能无限递归,所以一定要写判断终止当前递归的代码。/
private static void dfs(int x, int y, int s) { //从左到右,从上到下,依次遍历,找到可以放皇后的地方, //y是从左到右,遍历一行就加一行从新来 if (y == n) { y = 0; x++; } if (x == n) { if (s == n) { //如果成功的找到了n个皇后就把答案输出。
private static void dfs(int x, int y, int s) {
//从左到右,从上到下,依次遍历,找到可以放皇后的地方,
//y是从左到右,遍历一行就加一行从新来
if (y == n) {
y = 0;
x++;
}
if (x == n) {
if (s == n) {
//如果成功的找到了n个皇后就把答案输出。
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
System.out.printf("%c", g[j][k]);
}
System.out.println();
}
System.out.println();
}
return;
}
//不放皇后
dfs(x, y + 1, s);
// 放置皇后
if (!row[x] && !col[y] && !dg[y + x] && !udg[n - y + x]) {
g[x][y] = 'Q';
row[x] = col[y] = dg[x + y] = udg[n - y + x] = true;
dfs(x, y + 1, s + 1);
row[x] = col[y] = dg[x + y] = udg[n - y + x] = false;
g[x][y] = '.';
}
}
















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









