









 文章介绍了线程池的概念,强调其用于提升程序执行效率,特别是在用户态下优于内核态。线程池通过减少线程创建和销毁的开销来提高性能,文章列举了四种线程池的创建方式,并详细解释了线程池的核心参数和拒绝策略。此外,还探讨了手动实现线程池的基本思路。
文章介绍了线程池的概念,强调其用于提升程序执行效率,特别是在用户态下优于内核态。线程池通过减少线程创建和销毁的开销来提高性能,文章列举了四种线程池的创建方式,并详细解释了线程池的核心参数和拒绝策略。此外,还探讨了手动实现线程池的基本思路。
目录
池是什么东西?为何要有池这个概念?
其实学到现在 大家已经对池这个概念有了简单的理解了 这个池的主要功能就是为了提升程序执行效率的 不知大家是否还记得“常量池” 在SE阶段我们接触了这个常量池 这个池的功能就是为了减少冗余的创建 如果要用到池中有的数据 直接取出来省去了创建的时间 线程池也是一样的概念 主要功能就是为了提升程序的执行效率 线程池中存放的跟常量池中的不同 线程池顾名思义存放的就是线程 当需要线程来执行任务的时候 取出对应数量的线程去执行所需要执行的任务
为什么要有线程池
首先要明确 我们创建线程和销毁线程都是需要经过内核态来处理的 而如果我们想要提升效率 就可以考虑将这个“创建销毁”放在用户态
为何说在用户态可以提升效率?
我们先要了解一下什么是内核态和用户态
内核态
如果将任务交给内核态 就需要通过操作系统来操作内核态 因为内核态中间我们是接触不到的 而我们又不知道当前内核态中有多少需要执行的任务 所以我们的创建完成不知道要等到什么时候
用户态
我们有多少任务 是可以明确知道的 相比较而言 我们用户态是更加可控的
形象理解一下内核态与用户态

这是一个银行 今天我们帅气的博主来办理业务

此时我到了办理业务窗口
我:要办理业务
柜员: 先生您带身份证复印件了吗?
我:没有带
柜员:先生您现在有两个选择 a.您可以把身份证交给我 我去帮您打印一下身份证复印件 b.银行那边角落有打印机 您也可以自己去打印一下
此时 我们选择a就是交给了内核态 因为我们不确定柜员身上有多少任务 可能他去打印的同时 上个厕所 遇到同事分享分享博主的帅气 也可能上级领导交给了他一个新任务需要马上去做 此时我们要等待多久 我们完全不知道
如果我们选择了b 那么我们需要等待的时间都是可控并且明晰的 这个就是用户态和内核态的区别
线程池的创建
线程池有四种不同的创建方式
public class ThreadDemo9 {
public static void main (String[] args) {
//创建一个有固定线程数量的线程池
ExecutorService pool = Executors.newFixedThreadPool(10);
//创建一个自动适应线程数量的线程池
ExecutorService pool1 = Executors.newCachedThreadPool();
//创建一个只有一个线程的线程池
ExecutorService pool2 = Executors.newSingleThreadExecutor();
//创建一个带有定时器功能的线程池
ExecutorService pool3 = Executors.newScheduledThreadPool(10);
}
}为何创建线程池和创建对象不一样?
此处用到的是工厂模式 因为我们ExecutorService的构造方法 如果全部都只传入一个参数的话 我们是无法分辨这些线程池的 特性的 所以我们便拓展出了这种工厂模式的方法 工厂模式就类似于工厂生产出产品 你拿到即可直接使用
ThreadPoolService
Java中提供了线程池的相关标准ThreadPoolService,我们参照JDK1.8的来研究一下
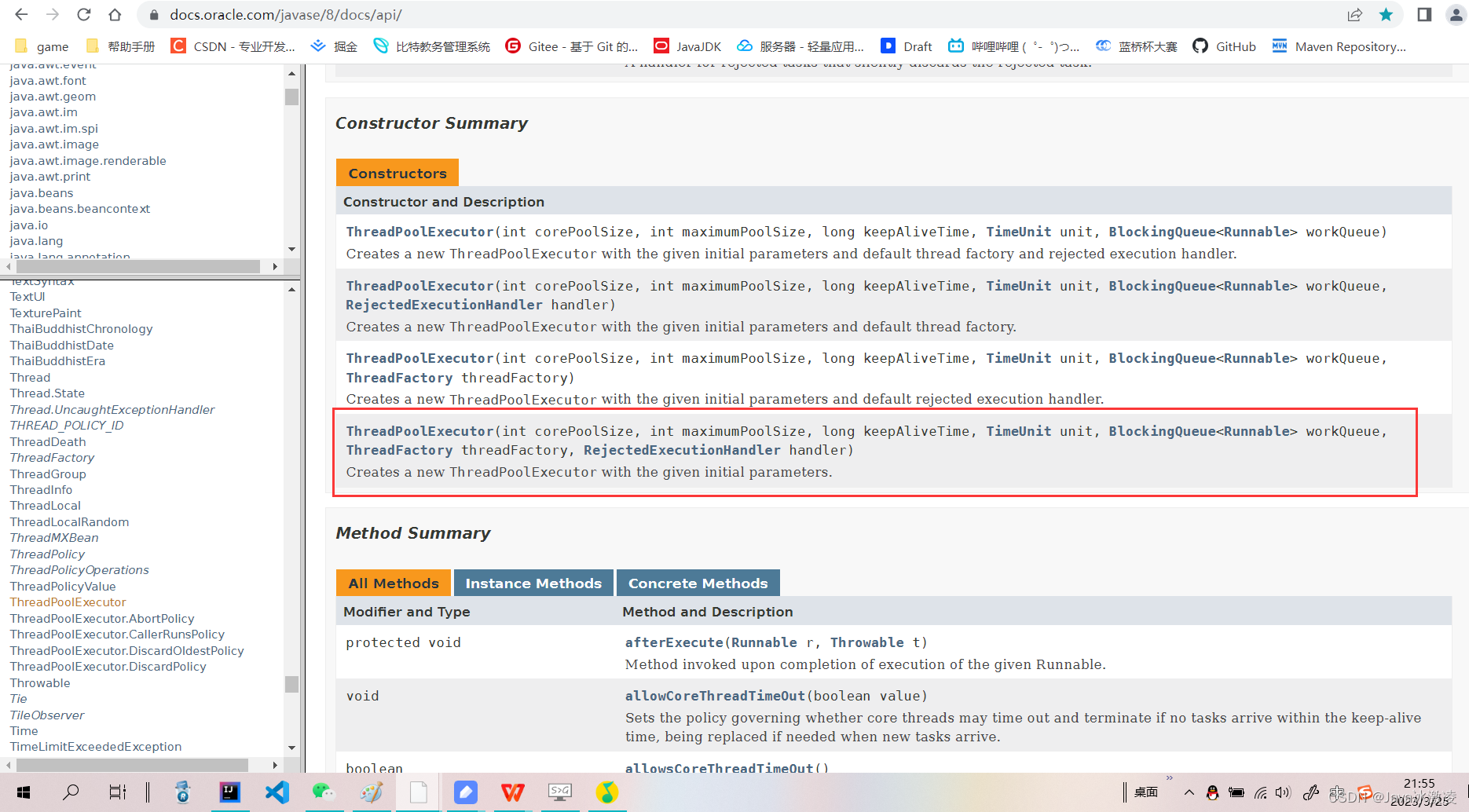
我们来解读一下这个方法
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
Creates a new ThreadPoolExecutor with the given initial parameters.corePoolSize:表示核心线程数
maximumPoolSize:最大线程数量(可以存在临时线程 但是有最大线程数量这个界限)
keepAliveTime:非核心线程存在的最大等待时间
unit:keepAliveTime的时间单位
workQueue:线程池的任务队列
threadFactory:线程工厂 线程创建的方案
handler:拒绝策略 描述如果当前的任务队列如果满了 以什么方式拒绝
拒绝策略(handler)
我们来重点解读一下拒绝策略
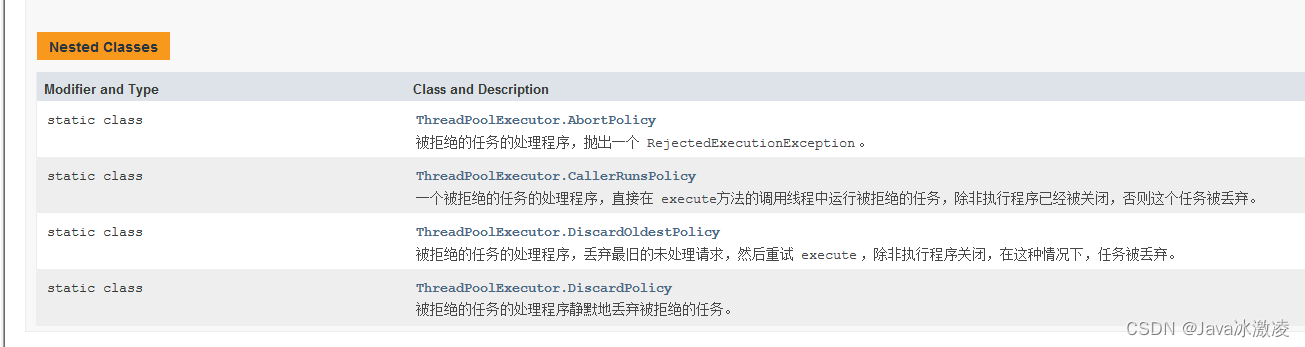
ThreadPoolExecutor.AbortPolicy :如果任务太多, 队列满了, 直接抛出异常RejectedExecutionException
就可以模拟一个情景 假设今天我作业是非常多的 老师还要给我布置一个大作业 此时 我因为受不了 哇的一声就哭出来了 耍赖 之前的作业和老师这次布置的作业我都不做了
ThreadPoolExecutor.CallerRunsPolicy 如果任务太多, 队列满了, 多出来的任务, 谁加的, 谁负责执行
还是之前的情景 今天我的作业是非常多的 老师还要给我布置作业 我说我不要了 别给我布置 谁给我布置谁去做(滑稽)
ThreadPoolExecutor.DiscardOldestPolicy 如果任务太多, 队列满了, 丢弃最旧的未处理的任务
还是之前的情景 如果我的作业实在是太多了 而我又要保证充足的休息 那么老师早布置的作业 我直接就不做了 我保留老师新布置的作业
ThreadPoolExecutor.DiscardPolicy 如果任务太多, 队列满了, 丢弃多出来的任务
还是之前的情景 如果我的作业实在是太多了 而我又要保证充足的休息 那么老师新布置的作业 我直接就不做了 之前的我还是照旧完成
手动实现一个简单的线程池
实现线程池
·使用一个BlockingQueue来组织任务
·使用worker类描述一个工作线程 使用Runnable来描述一个具体的任务
·每个线程要做的工作 使用worker类不停的去读取BlockingQueue中的任务
·指定一个固定线程数量的线程池 当线程个数超过最大个数的时候 此时便不会再去创建线程
·实现submit来放入一个任务到BlockingQueue
逻辑已理顺 开干~
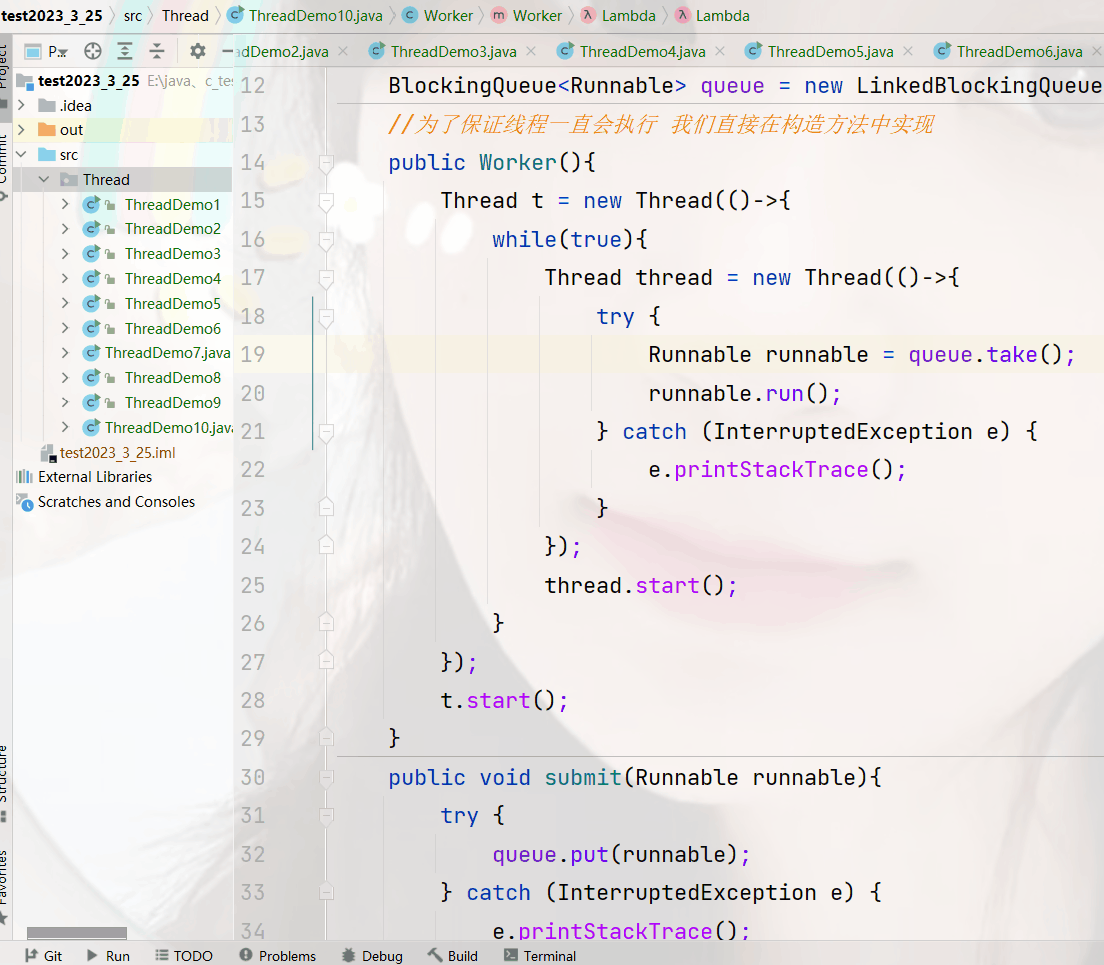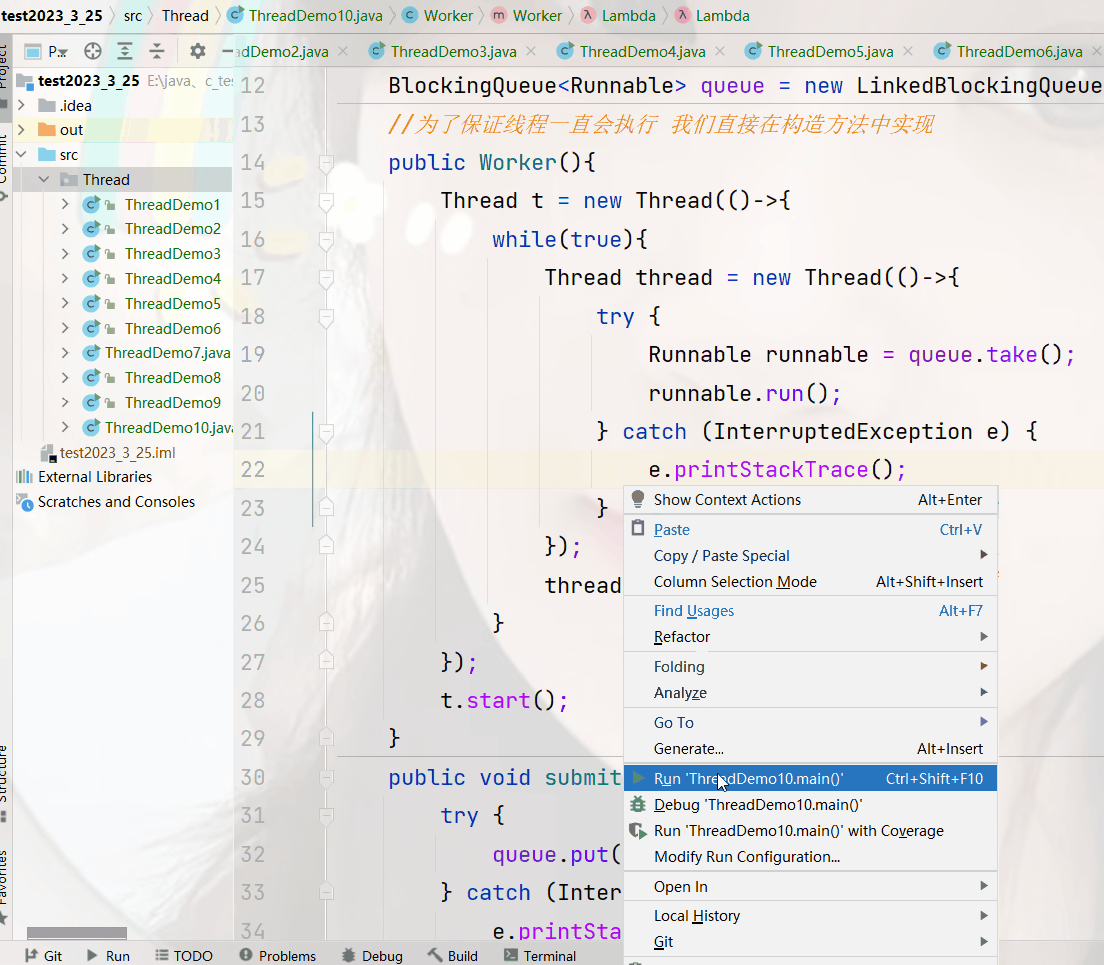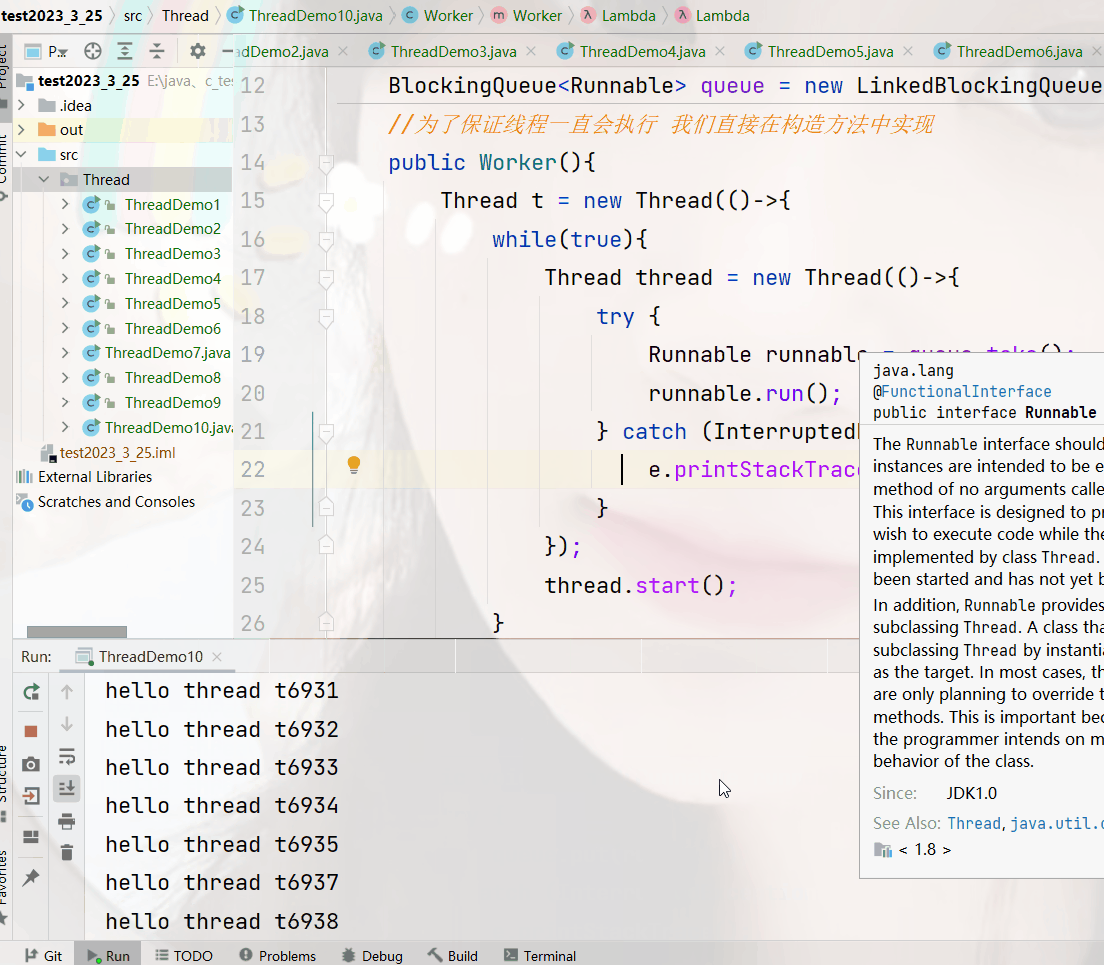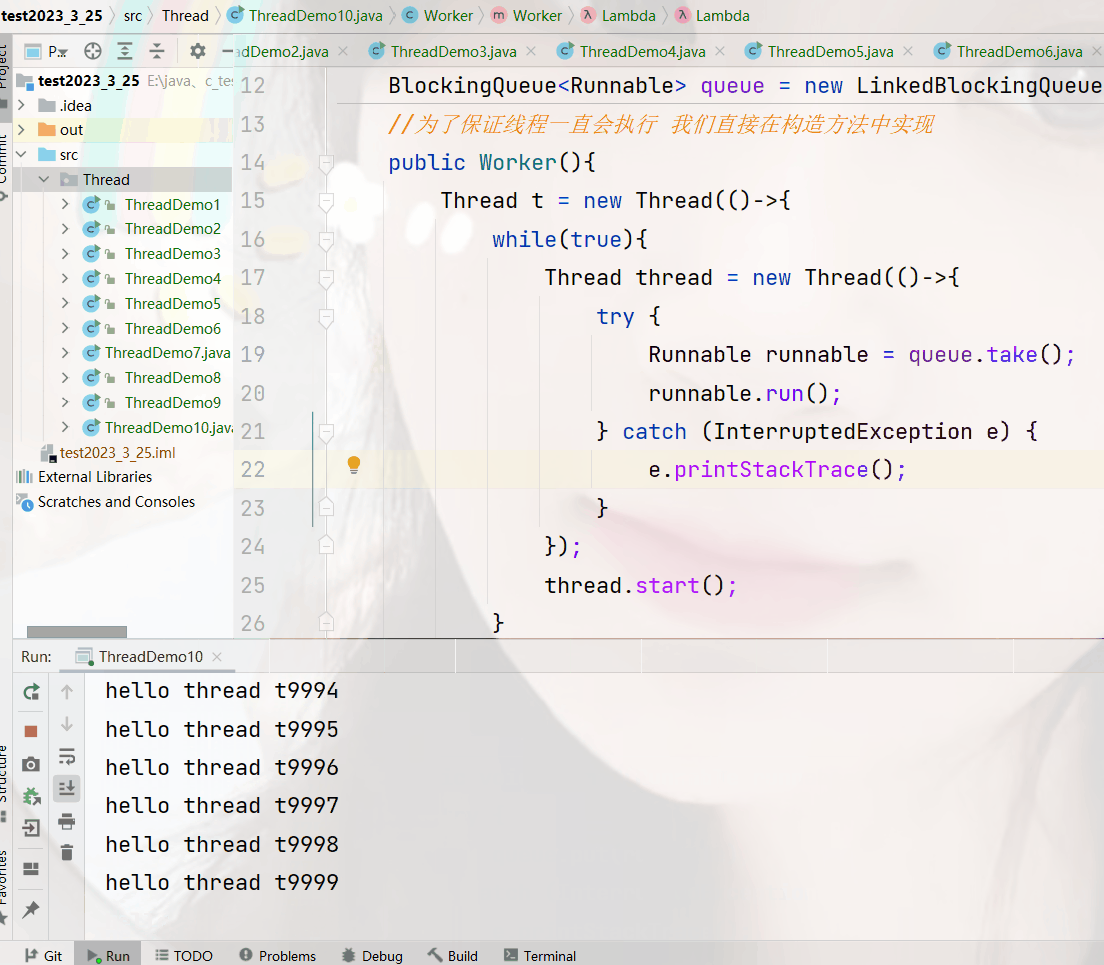
class Worker{
//我们使用一个阻塞队列来组织任务
BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(100);
//为了保证线程一直会执行 我们直接在构造方法中实现
public Worker(int n){
Thread t = new Thread(()-> {
for(int i = 0; i < n; i++){
Thread thread = new Thread(()->{
while(true){
try {
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
}
});
t.start();
}
public void submit(Runnable runnable){
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class ThreadDemo10 {
public static void main (String[] args) {
Worker worker = new Worker(10);
for (int i = 0 ; i < 10000 ; i++) {
int n = i;//此处要注意变量捕获的问题
worker.submit(new Runnable() {
@Override
public void run () {
System.out.println("hello thread t" + n);
}
});
}
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











