







老早之前写的草稿,现在发现可能以后会想回忆或者找找灵感。
随便选取B站一个弹幕较多的视频,将其弹幕文件作为练习:
提取前:

提取后:
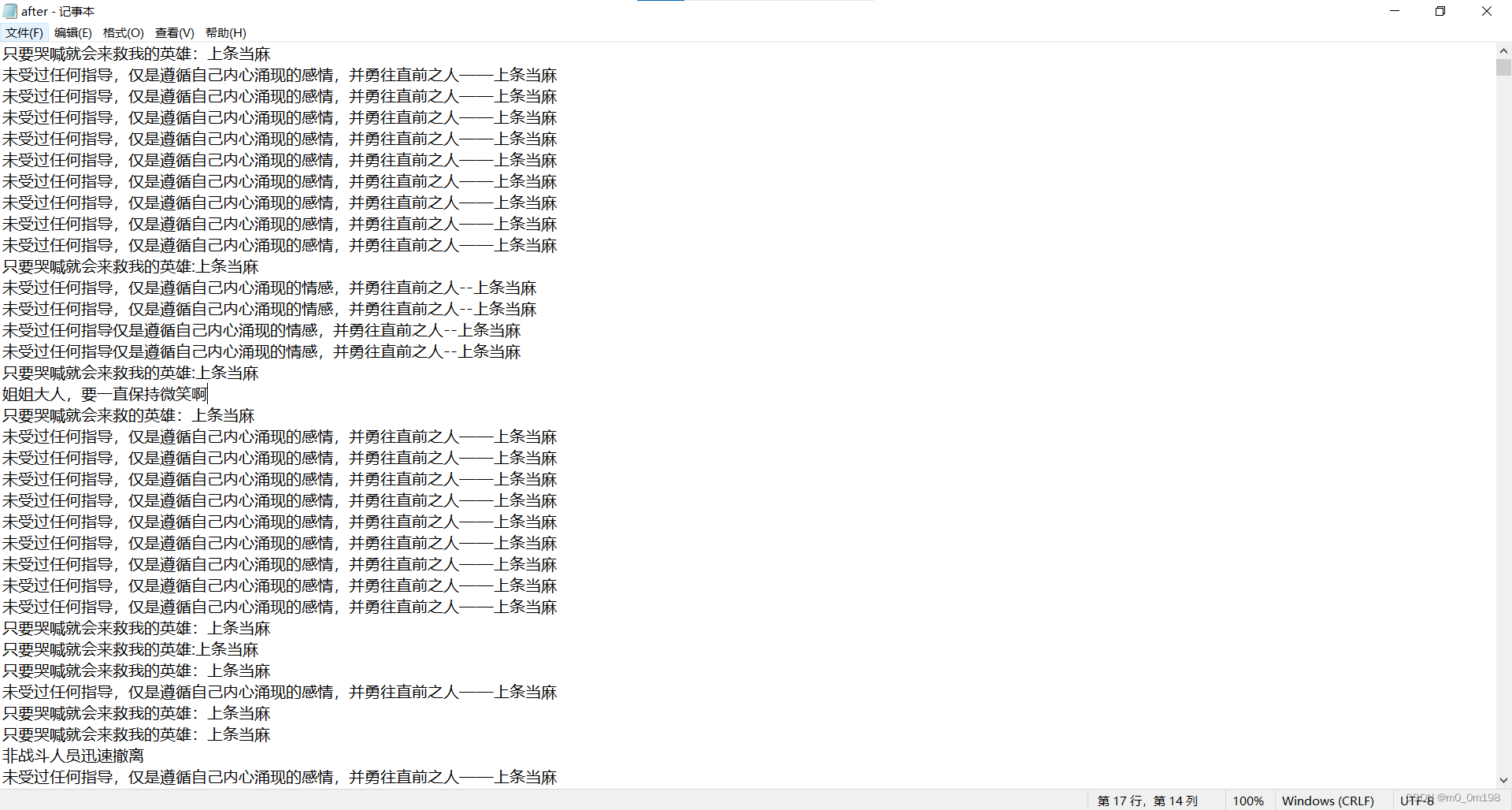
分析:
【最好直接用正则表达式提取(一步解决):data = re.findall('<d p=".*?">(.*?)</d>', data)
(.*?代表任意字符,括号括起来的表示需要提取的部分,其他不需要提取的需观察共有部分照写上去,后面,data那个参数表示对data变量进行提取)】
1、首先读取原文件,打印输出发现是2105行9列二维的DataFrame,只有最后一列包含了需要提纯的弹幕,前8列都是与弹幕内容无关的信息,[:, 8]表示所有行,第9列。
2、因为需要访问具体行列,所以要将DataFrame转换成ndarray
否则会有以下错误:
TypeError: '(slice(None, None, None), 1)' is an invalid key
参考:https://blog.youkuaiyun.com/qxqxqzzz/article/details/88315577
3、最后存储文件用pandas的to_csv函数,每条弹幕换行存储也即间隔为'\n'
(最后:如果no module names pandas,去setting里将project interpreter 设为python 3.10)
代码:
import pandas as pd
data = pd.read_csv('炮姐.txt', error_bad_lines=False)
# 遇到问题1:dataframe转成ndarray的问题(即用下面一行来解决)
data = data.values
data_new = data[:, 8]
# 存储:
data2 = pd.Series(data_new) # 再将其转为DataFrame
data2.to_csv('after.txt', sep='\n', index=False)
现在效果图:
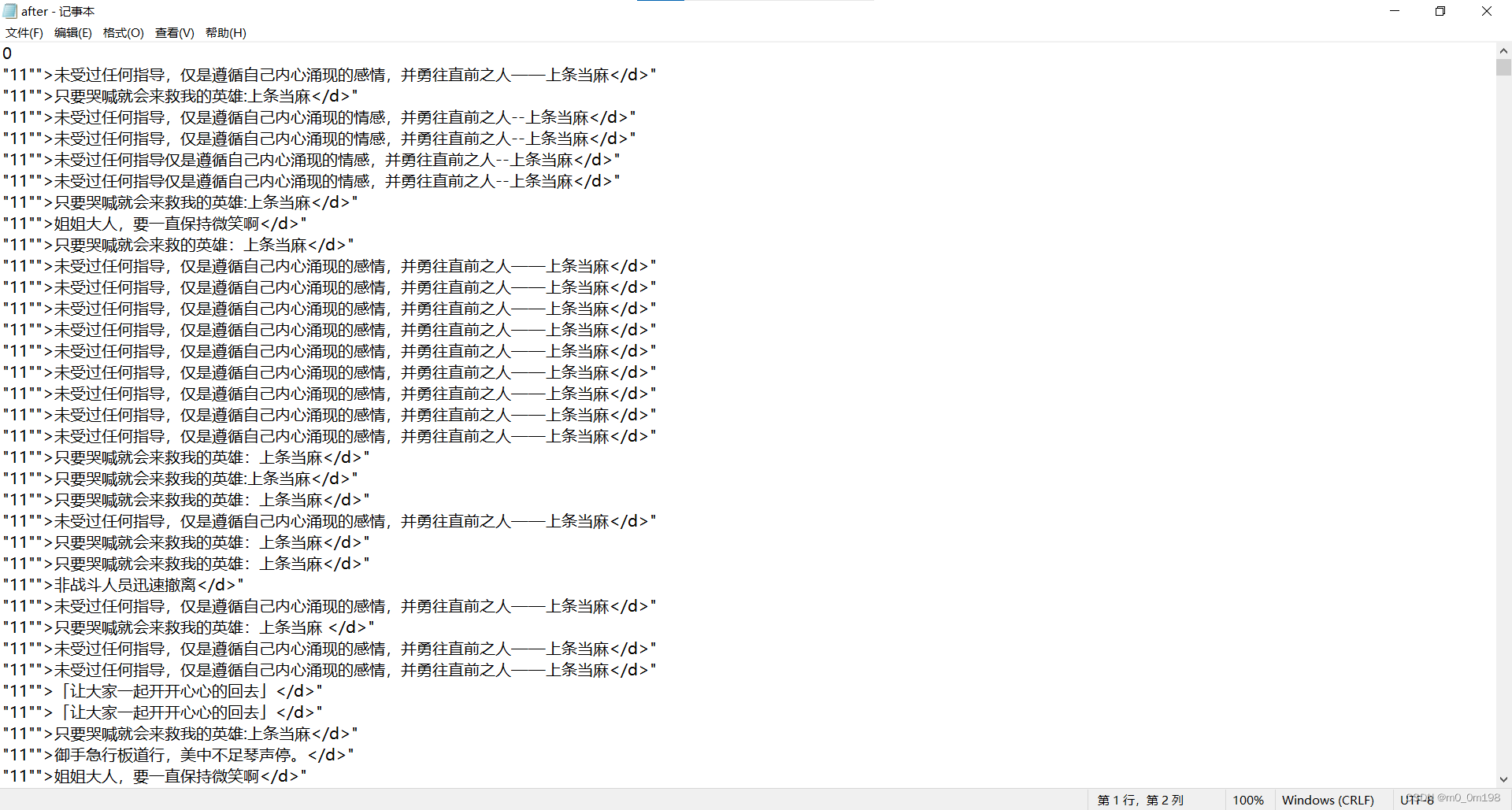
最后用pandas的dtype查看元素类型发现是object类型的元素,文件里存储的是一个完整的元素,对一个元素删改不同与对一个数组删改,由于对一个元素删改较复杂。
所以最后还是选择用txt自带的查找功能:ctrl +H 手动花1min将有规律的多余部分替换为空。并先删去与内容无关的第一行。即可满足需求。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









