






 本文详细解释了Python中引用计数的概念及其应用场景,包括何时增加和减少,以及sys.getrefcount()函数的使用。同时介绍了Python的垃圾回收机制,特别是分代回收和标记清除策略,以及内存池(包括小整数缓冲池和简单字符串驻留区)的作用。最后讲解了深浅拷贝的区别和实现方法。
本文详细解释了Python中引用计数的概念及其应用场景,包括何时增加和减少,以及sys.getrefcount()函数的使用。同时介绍了Python的垃圾回收机制,特别是分代回收和标记清除策略,以及内存池(包括小整数缓冲池和简单字符串驻留区)的作用。最后讲解了深浅拷贝的区别和实现方法。
引用计数
Python的内存管理以引用计数为主。
引用计数增加的场景如下:
1.对象被创建并赋值给某个变量
2.变量间相互引用,相当于变量指向了同一个对象
3.变量作为参数传入某个函数中
4.将对象放入某个容器对象中
引用计数减少的场景如下:
1.对象的引用变量被销毁
2.对象的引用被赋值给其他对象
3.变量离开作用域,如:函数执行完成
4.对象被从容器对象中销毁,或整个容器被销毁
sys.getrefcount()函数可以查看对象的引用计数,但是调用此函数时,会临时增加一个引用计数,得到的结果比预期多一次,如下图

使用引用计数会存在循环引用的问题,导致在程序运行期间,应该被回收的内存并没有正确回收,造成了内存泄露,我们可以使用gc机制强制回收内存
from sys import getrefcount
x = ["xxx"]
y = ["yyy"]
print(f"reference count of x is {getrefcount(x)}")
print(f"reference count of y is {getrefcount(y)}")
#两个列表之间相互引用
x.append(y) #引用y
y.append(x) #引用x
print("*" * 30)
print(f"reference count of x is {getrefcount(x)}")
print(f"reference count of y is {getrefcount(y)}")
#del语句--删除到变量到对象的引用和变量名称本身
del x #引用计数仍为1,不是0,所以对象不会被销毁-->内存泄露
del y
try:
print(f"reference count of x is {getrefcount(x)}")
print(f"reference count of y is {getrefcount(y)}")
except NameError as err:
print(err)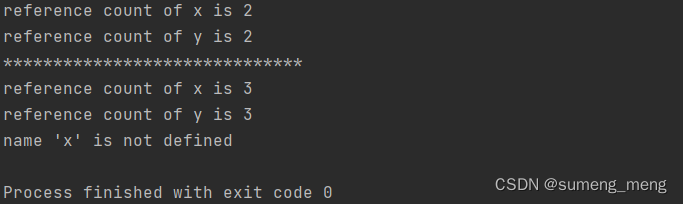
gc机制--垃圾回收机制
在Python中,会采用分代回收的方式:把对象分为三代,对象在创建的时候,放在一代中,当一代的总数达到上限时,就会触发垃圾回收机制,把那些可以回收的对象回收掉,那些没被回收的对象就被移动到二代中去,以此类推,三代中的对象是存活最久的对象,甚至会存活于整个系统的生命周期内
分代回收是建立在标记清除基础上的(垃圾回收=垃圾检查+垃圾回收),分为两个阶段:
1.标记阶段:遍历所有对象,如果还有对象引用它,那么就标记该对象为可达
2.清除阶段:再次遍历对象,如果发现某个对象没有标记可达,就将其回收
总结来说,Python的垃圾回收方式为以引用计数为主,分代回收和标记清除为辅的垃圾回收方式
内存池
在内存分配时,引入内存池机制,以此来缓存小整数和简单字符串
小整数缓冲池
程序运行时会创建小整数([-5, 256])放入内存池中,如果创建整数对象的时候,在-5~256之间就直接从内存池分配空间;如果不在这个区间,就创建新的对象
a = 1
b = 1
#两个变量的内存地址是一样的
print(f"id of a is {id(a)}")
print(f"id of b is {id(b)}")
简单字符串驻留区
特殊字符不会驻留(但是仅有一个特殊字符会进入驻留区),长度超过一定范围也不会驻留
str1 = "abc"
str2 = "abc"
# 两个变量的内存地址是一样的
print(f"id of str1 is {id(str1)}")
print(f"id of str2 is {id(str2)}")
深浅拷贝
深浅拷贝只有在容器类型中包含可变数据类型的时候才会有区别
浅拷贝只会拷贝最外层数据的引用,它里面可变数据类型的修改可能会影响原对象
深拷贝会对容器类型里面的可变数据类型做一次全新的copy,生成新的可变数据类型,它里面的修改不会影响原来那个对象
浅拷贝
例:使用可变数据类型的copy属性
lst1 = [1, "abc", 2, ["hello"]]
lst2 = lst1.copy()
print(f"lst1: {lst1}, lst1 id: {id(lst1)}")
print(f"lst2: {lst2}, lst1 id: {id(lst2)}")
#列表中元素的地址是一样的,说明浅拷贝就是新建一个列表空间将引用拷贝一份
print(f"lst1[0] id: {id(lst1[0])}")
print(f"lst2[0] id: {id(lst2[0])}")
# 修改lst2中可变数据类型的值
lst2[3].append("sumeng")
print("after modify......")
print(f"lst1: {lst1}")
print(f"lst2: {lst2}")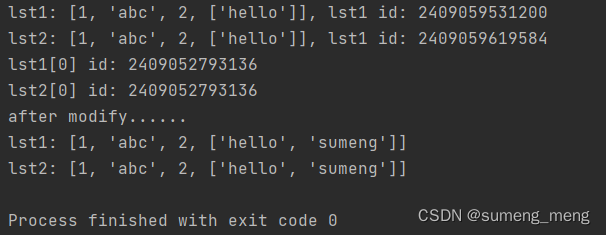
深拷贝
只有一种形式可以实现:copy模块中的deepcopy
from copy import deepcopy
lst1 = [1, 'abc', 2, ['hello']]
lst2 = deepcopy(lst1)
# 列表中值的地址是不一致的,说明深拷贝是拷贝值
print(f"lst1[3] id: {id(lst1[3])}")
print(f"lst2[3] id: {id(lst2[3])}")
# 修改列表中可变数据类型的值,不会影响原始列表lst1
lst2[3].append("sumeng")
print("after modify......")
print(f"lst1: {lst1}")
print(f"lst2: {lst2}")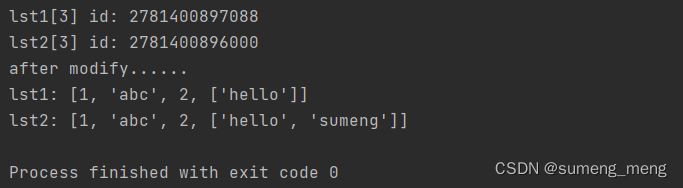

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









