






本次实战利用Bert模型进行下游文字分类,即对一类文本进行类别标签的预测,所用数据集为某外卖评论数据集。
与前面实战不同,本次实战对数据处理,模型定义与训练和验证三个过程进行了封装,将功能模块化,使代码更加简洁,易于维护。
1.数据处理
读取数据,将其划分为训练集和验证集,并获得相应数据加载器。
(1)读文件函数:
def read_file(path):
data = []
label = []
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i == 0: #第一行不可用,跳过
continue
if i > 200 and i < 11500:
continue
#只取前200条数据和后488数据(总共11988条数据,前好评后差评,根据数据集改,避免数据不均衡)
line = line.strip("\n") #去掉读出的换行符(读取数据时通常会出现换行符)
line = line.split(",", 1) #根据逗号分割,1表示分割次数
data.append(line[1])
label.append(line[0])
print("读了%d的数据"%len(data)) #打印读出多少条数据
return data, label(2)数据集类:三个函数与前两个实战类似,但需注意两点。第一,读文件函数得到了数据和标签,在数据集类的初始化函数中可直接赋值存储;第二,读文件函数中label列表里存储的是字符型数据,而通常进行训练验证的标签为整型,需进行转换。
(3)获得数据加载器:
def get_data_loader(path, batchsize, val_size=0.2):
#读入数据,分割数据,val_size=0.2代表五分之一的数据当作验证
data, label = read_file(path) #调用读文件函数
train_x, val_x, train_y, val_y = train_test_split(data, label, test_size=val_size,shuffle=True, stratify=label)
#stratify=label表示按标签的比例分割数据集
train_set = jdDataset(train_x, train_y)
val_set = jdDataset(val_x, val_y)
train_loader = DataLoader(train_set, batchsize, shuffle=True)
val_loader = DataLoader(val_set, batchsize, shuffle=True)
return train_loader, val_loader2.定义模型
class myBertModel(nn.Module):
def __init__(self, bert_path, num_class, device):
super(myBertModel, self).__init__()
self.bert = BertModel.from_pretrained(bert_path) #加载预训练的bert模型(设置和参数)
'''
config = BertConfig.from_pretrained(bert_path) #只加载设置
self.bert = BertModel(config) #根据设置建立模型
'''
self.device = device
self.cls_head = nn.Linear(768, num_class) #添加一个全连接层,映射到指定的类别数
self.tokenizer = BertTokenizer.from_pretrained(bert_path) #分词器
def forward(self, text):
input = self.tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
#对输入文本进行分词和编码,指定返回类型为pytorch张量,保证输入序列长度与给定的最大长度相同(填充加截断)
#ps:调用大佬模型,以下代码定义不确定可以调试看分词后包括什么部分
input_ids = input["input_ids"].to(self.device) #分词后的Token ID列表
token_type_ids = input['token_type_ids'].to(self.device) #区分不同句子的标识符
attention_mask = input['attention_mask'].to(self.device) #屏蔽填充的注意力掩码
sequence_out, pooler_out = self.bert(input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask,
return_dict=False) #return_dict=False,返回一个元组(True为字典)
pred = self.cls_head(pooler_out) #获得预测值
return pred3.训练和验证,与前两个实战基本类似,多一点优化。
scheduler.step() #调整优化器学习率
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) #梯度裁切,设置阈值防止梯度爆炸4.主函数调用与配置
#引入函数模块 from 文件夹.文件名 import 模块名
from model_utils.data1 import get_data_loader
from model_utils.model1 import myBertModel
from model_utils.train import train_val
#随机种子
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
lr = 0.0001 #学习率
batchsize = 16 #批次大小
loss = nn.CrossEntropyLoss() #损失函数
bert_path = "bert-base-chinese" #模型地址
num_class = 2 #标签类别数
device = "cuda" if torch.cuda.is_available() else "cpu" #设备
max_acc = 0.6 #最大准确率
val_epoch = 1
model = myBertModel(bert_path, num_class, device).to(device) #模型实例化
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=0.00001) #优化器
data_path = "waimai.txt" #初始数据集地址
train_loader, val_loader = get_data_loader(data_path, batchsize)
epochs = 5 #轮次数
save_path = "model_save/best_model.pth" #最优模型保存地址
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, eta_min=1e-9)
#改变学习率,定义了一个学习率调度器,在一个周期内,学习率会按照余弦函数的形式从初始值逐渐降低到最小值,T_0为重启周期长度,eta_min为最小学习率
#可以有效避免学习率过早降低导致模型陷入局部最优,
para = {
"model": model,
"train_loader": train_loader,
"val_loader": val_loader,
"scheduler": scheduler,
"optimizer": optimizer,
"loss": loss,
"epoch": epochs,
"device": device,
"save_path": save_path,
"max_acc": max_acc,
"val_epoch": val_epoch #训练多少轮验证一次
} #集中存储参数
train_val(para) #调用训练和验证模块结果如下:
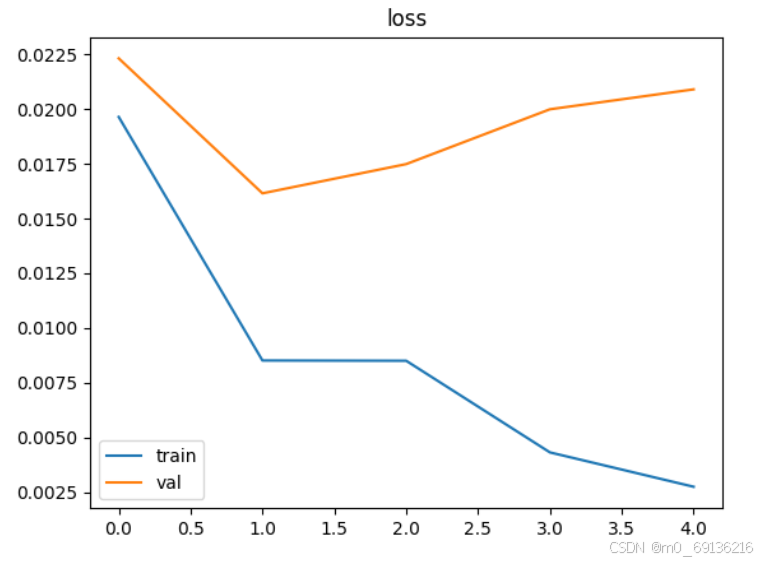
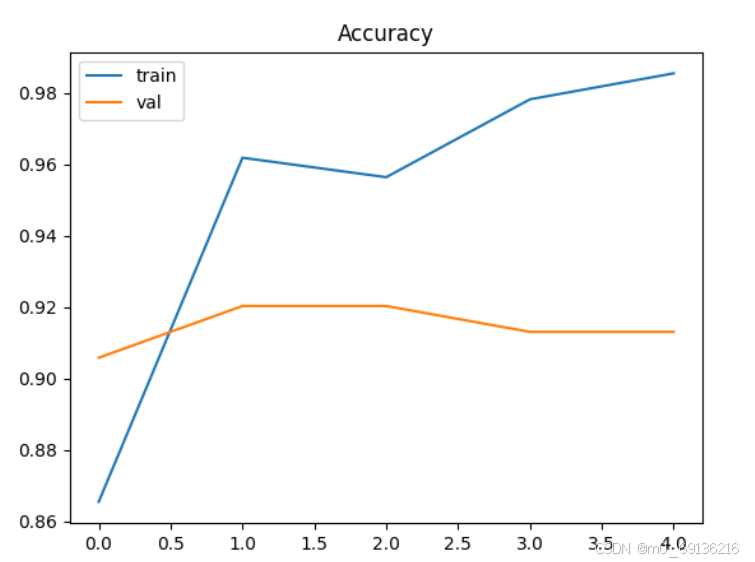


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









