






一 ,前言
数据结构是一门研究计算机的操作对象及其相互之间的关系和运算等的学科,它关系到算法的选择进而影响程序执行的效率。简单来说,就是这样:数据结构+算法=程序,由此,其重要性也就不言而喻了吧。
1,基本概念
数据:能被计算机识别和处理的符号集合,想想计算机能识别什么嘛,没错,各种二进制数,0呀,1呀这些符号(别误会,还有很多图像,数字,声音等都是数据,因为最终都会被转化为二进制数从而被识别)。
数据元素:数据的基本单位,可以被看做某个逻辑整体,比如包含学生姓名,年级,学号等系列的一张学生信息表的这个整体。
数据项:构成数据元素的最小单位,比如姓名,年级...见图一
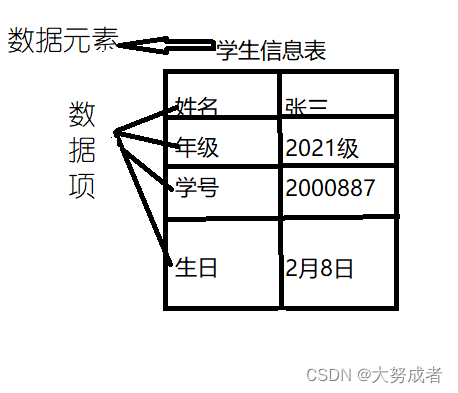
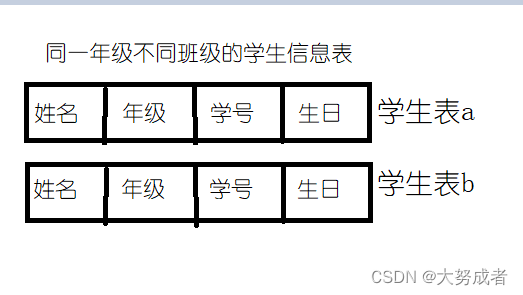
数据对象:具有相同性质的数据元素的集合,如图二N={姓名,学号,年级,生日,...}所有的学生信息,再来一个例子,学科={语文,数学,英语,物理,化学,生物}
数据结构:
其分为逻辑结构和物理结构,逻辑结构又分为集合结构,线性结构,树结构,图结构
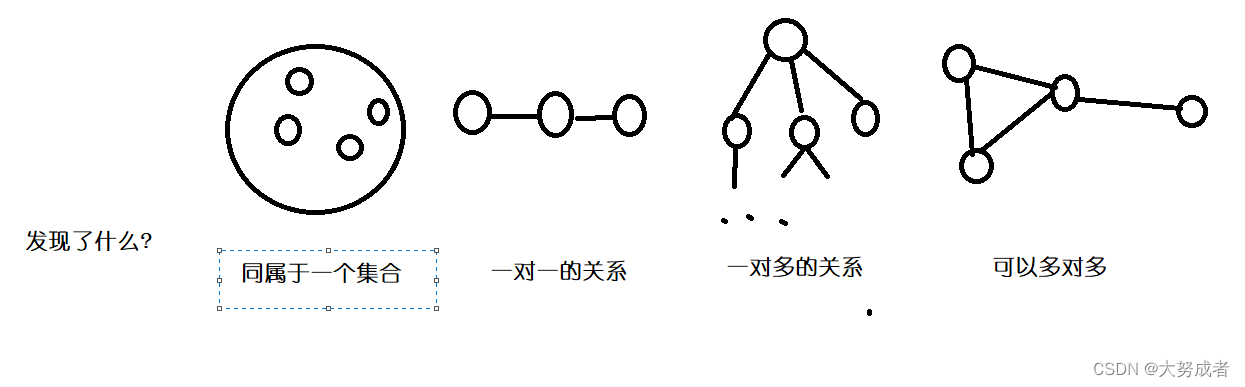
物理结构分为①顺序存储(逻辑上相邻的数据元素存储在物理位置相邻的存储单元中)数组就是这样,a[10]=a[0]+ a[1]+a[2]+a[3]+...其空间分配也相邻。②链式存储(逻辑上相邻的数据元素不要求其存储位置必须相同,用指针来存储。
算法特性:有输入 有输出 有穷性 确定性 有效性
评价:正确性 可读性 健壮性 有效性
2,算法的复杂度
2.1 时间复杂度
算法所耗的具体时间很难算出,也没有必要上机测试,只需要知道哪个算法花的时间多,哪个算法花的时间少,算法中语句的执行次数多,其花费的时间也就越多,一般情况,算法中基本操作重复执行的次数 是问题规模n个函数,,用T(n)表示。O(f(n))为算法的渐进时间复杂度,f(n)为函数形式。T(n)=O(f(n))。
2.1.1 计算方法
(1)简单的输入输出,赋值语句,近视认为需O(1)时间
(2)求和法则 顺序结构 两个部分的时间复杂度,取大的个
![]()
(3) 选择在结构 如if语句,O(1).
(4)乘法法则 嵌套循环
![]()
例如:
for(i=1;i<n;i++)
x++;//加法循环n次,因此时间为O(n)
for(i=1;i<n;i++)
for(j=1;j<i;j++)
x++;//i的加法执行1次的同时,j也会执行,即O(n²)一般的,对n足够大时,常用的复杂度顺序如下:
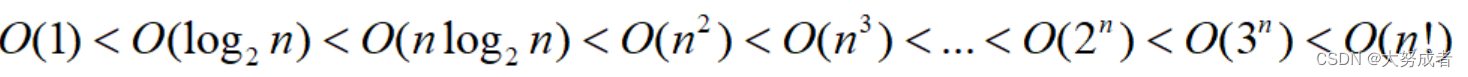
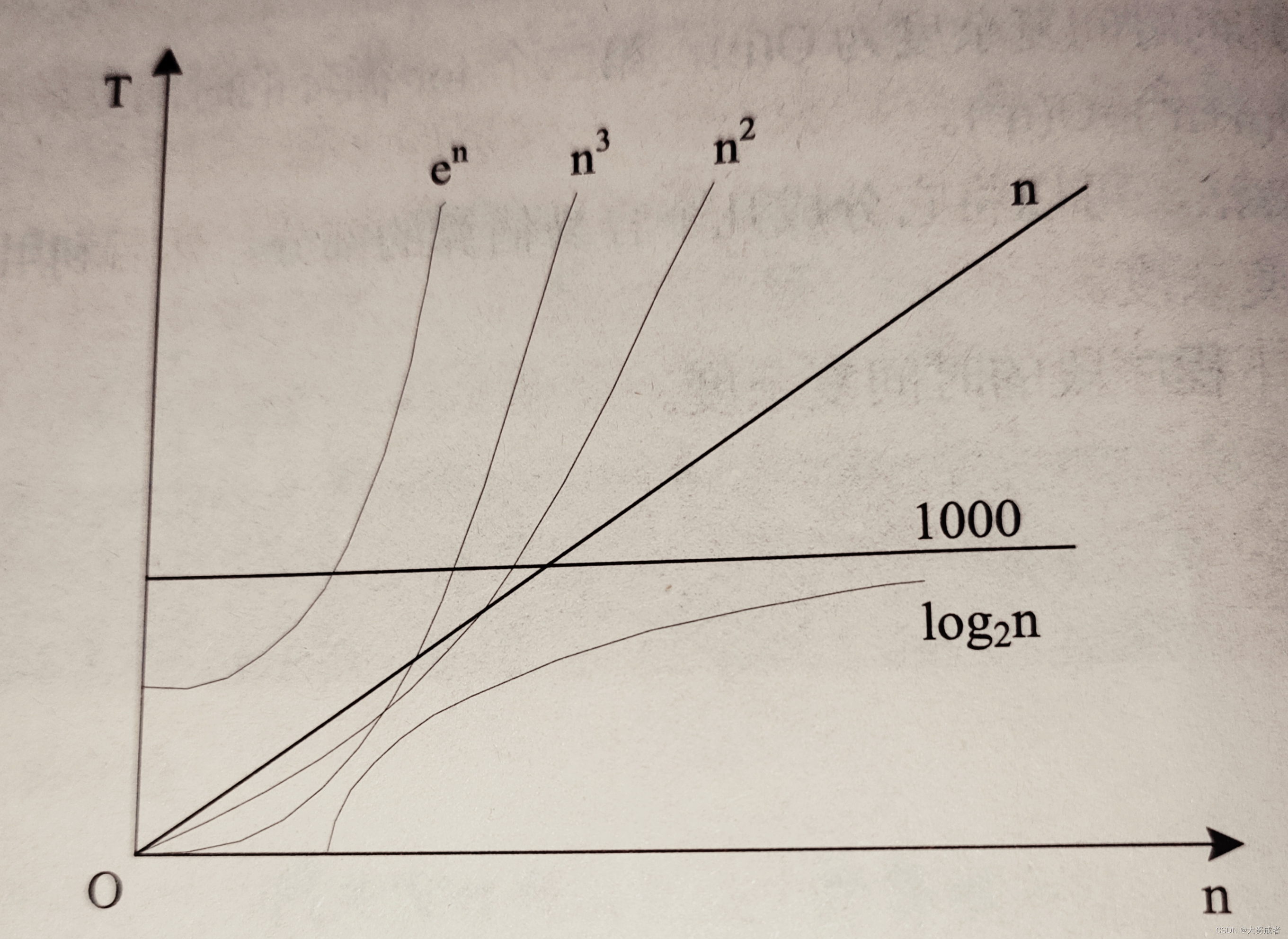
2.2 空间复杂度
当问题规模n趋近于无穷大时的空间量级称为算法的渐近空间复杂度S(n)=O(f(n))
re(int a[],int n)
{
int i,j,*b;//只看这里,b所占空间n+2个控制变量i,j,所以S(n)=n+2=O(n)
b=(int *)malloc(sizeof(int)*n);
for(i=0,j=n-1;i<n;i++,j++)
b[i]=a[i];
for(i=j=0;i<n;i++,j++)
a[i]=b[i];
free(b);
}3,线性表
3.1 顺序存储
顺序表(逻辑上相邻的数据元素物理上也相邻的基本操作基本操作
1 静态分配
#include<stdio.h>
#define MaxSize 6
typedef struct {
int data[MaxSize];
int length;
}sqlist;
void InitList(sqlist &L){
L.length=0;//设置默认值
}
int main()
{
sqlist L;
InitList(L);
for(int i=0;i<L.length;i++)
printf("data[%d]=%d\n",i,L.length);
return 0;
}2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









