









亲爱的小伙伴们,大家好!在这篇文章中,我们将深入浅出地为大家讲解 MySQL索引 帮助您轻松入门,快速掌握核心概念。
如果文章对您有所启发或帮助,请别忘了 点赞 👍、收藏 🌟、留言 📝 支持!您的每一份鼓励,都是我持续创作的源动力。让我们携手前行,共同进步!
上一篇文章中,博主介绍了 :
表的查询语句和聚合函数可以将上一篇文章看完之后再来看这篇文章,链接如下:
那么接下来正文开始:
1. 什么是索引
1.1 概念
- 索引的主要作用是为了 提高数据库查询的性能;
- 不用加内存,不用改程序,不用调
sql,只要执行正确的create index,查询速度就可能提高成百上千倍; - 但是会 增加删除、更新、插入的效率。
1.2 示例
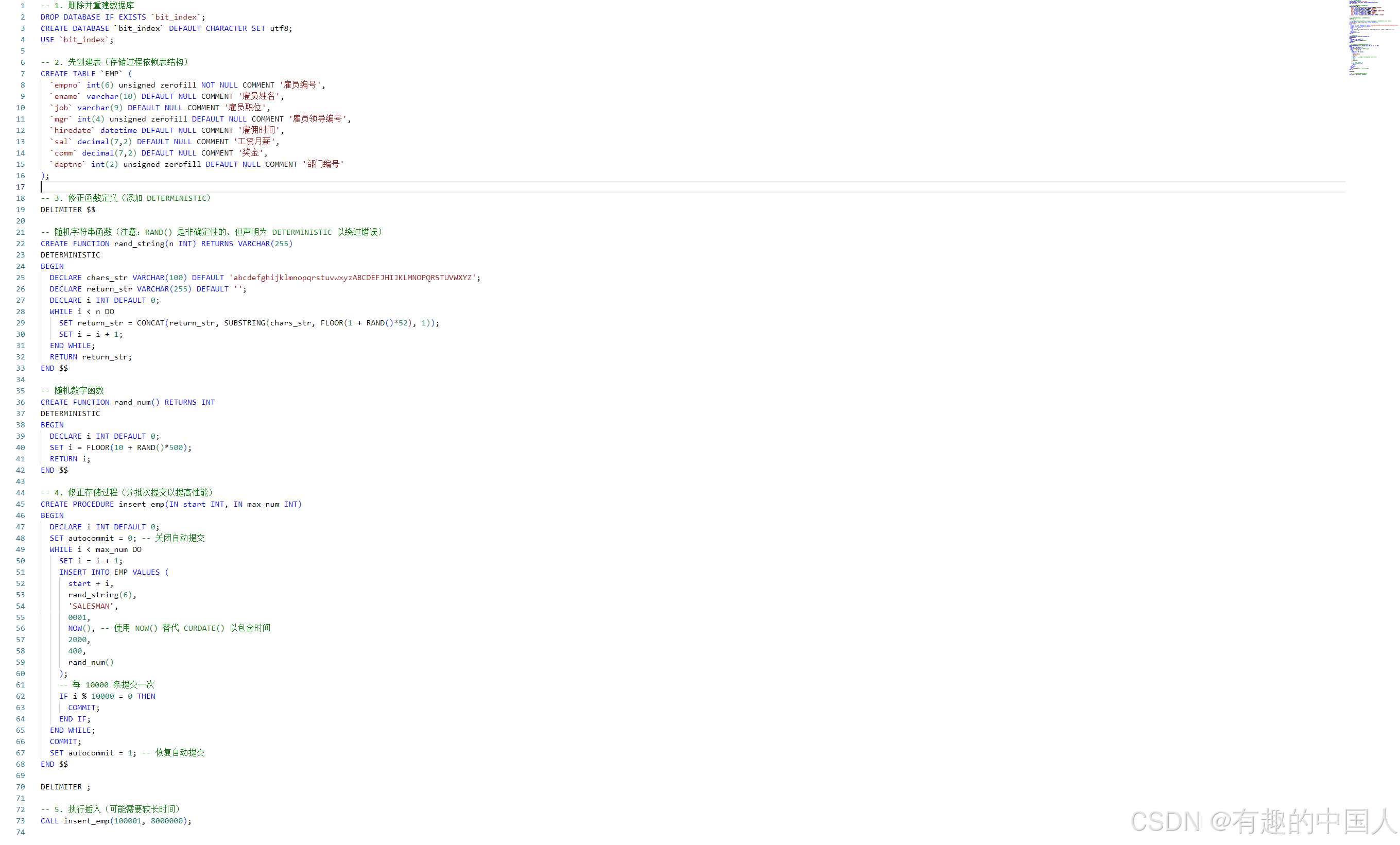
- 首先构建一个
8000000条记录的数据,用下面的代码:
- 然后查询
empno=998877的员工:
mysql> select * from EMP where empno=998877;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 998877 | tLvWwr | SALESMAN | 0001 | 2025-03-01 20:21:42 | 2000.00 | 400.00 | 199 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
1 row in set (8.90 sec) -- 将近 9 秒
可以发现用了很长的时间…
- 给
empno加上索引:
mysql> alter table EMP add index(empno);
Query OK, 0 rows affected (32.58 sec)
Records: 0 Duplicates: 0 Warnings: 0
- 再次查询
empno=998877的员工:
mysql> select * from EMP where empno=998877;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 998877 | tLvWwr | SALESMAN | 0001 | 2025-03-01 20:21:42 | 2000.00 | 400.00 | 199 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
1 row in set (0.00 sec) -- 不到 0.1 秒
发现快了很多,这就是索引的作用。
1.3 数据写到磁盘流程
- 需要首先认识一点,创建数据库本质上就是创建一个目录,创建表本质上就是创建一个文件,都是内存级别的,然后再由
OS刷新到磁盘上,流程大致如下:
数据写入流程
- 应用程序写入:
- 当数据库执行写操作(如
INSERT)时,数据首先被写入 用户态内存缓冲区(如 InnoDB 的 Buffer Pool)。
- 当数据库执行写操作(如
- 系统调用写入:
- 数据通过
write()系统调用进入 内核态页缓存(Page Cache),此时数据尚未落盘。
- 数据通过
- 调用
fsync:
执行fsync(fd)后,操作系统会:- 将指定文件描述符
fd对应的所有脏页(修改过的页)刷新到磁盘。 - 等待磁盘确认写入完成(确保数据持久化)。
- 将指定文件描述符
- 返回结果:
fsync返回成功表示数据已写入磁盘介质,断电不会丢失。
2. 认识磁盘
2.1 MySQL与存储
MySQL给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。- 磁盘是计算机中的一个机械设备,相比于计算机其他电子元件,磁盘效率是比较低的,在加上
IO本身的特征,可以知道,如何提交效率,是MySQL的一个重要话题。
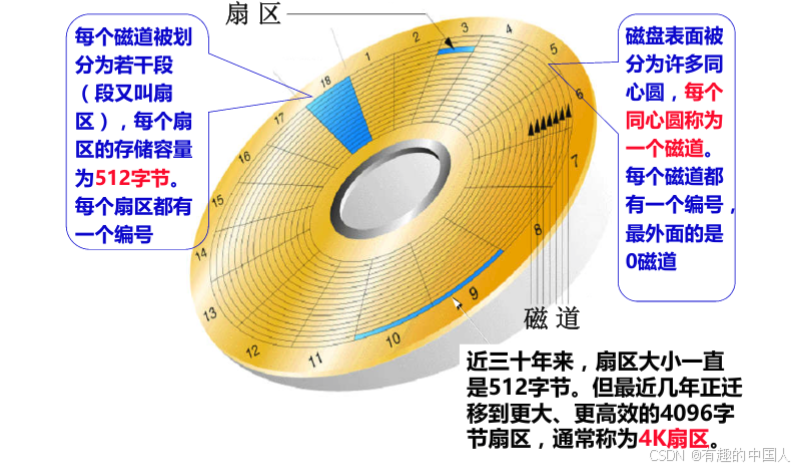
2.2 扇区
- 数据库文件,本质其实就是保存在磁盘的盘片当中。也就是上面的一个个小格子中,就是我们经常所说的扇区。当然,数据库文件很大,也很多,一定需要占据多个扇区;
- 从上图可以看出来,在半径方向上,距离圆心越近,扇区越小,距离圆心越远,扇区越大;
- 所有扇区都是默认
512字节; - 虽然最新的技术可以让每个扇区的存储容量不一样,但是这里可以不用考虑。
2.3 定位扇区
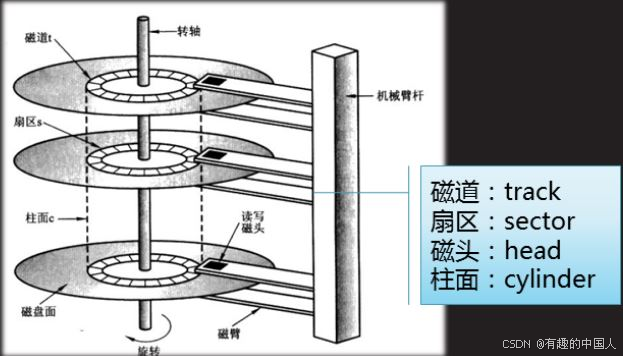
- 柱面(磁道): 多盘磁盘,每盘都是双面,大小完全相等。那么同半径的磁道,整体上便构成了一个柱面;
- 每个盘面都有一个磁头,那么磁头和盘面的对应关系便是1对1的;
- 所以,我们只需要知道,磁头(Heads)、柱面(Cylinder)(等价于磁道)、扇区(Sector)对应的编号。即可在磁盘上定位所要访问的扇区。这种磁盘数据定位方式叫做
CHS。 - 不过实际系统软件使用的并不是
CHS(但是硬件是),而是LBA,一种线性地址,可以想象成虚拟地址与物理地址。系统将LBA地址最后会转化成为CHS,交给磁盘去进行数据读取。不过,我们现在不关心转化细节,知道这个东西,让我们逻辑自洽起来即可。
2.4 MySQL与磁盘交互的基本单位
-
系统读取磁盘,是以块为单位的,基本单位是 4KB。而 MySQL 作为一款应用软件,可以想象成一种特殊的文件系统 它有着更高的IO场景,所以,为了提高基本的IO效率, MySQL 进行IO的基本单位是 16KB。
-
也就是说,磁盘这个硬件设备的基本单位是
512字节,而MySQL InnoDB引擎 使用16KB进行IO交互。即,MySQL和磁盘进行数据交互的基本单位是16KB。这个基本数据单元,在MySQL这里叫做page。
3. InnoDB数据插入的核心流程
3.1 默认模式(innodb_flush_method=fsync)
- 特点:
- 双重缓存: 数据同时存在于
Buffer Pool和Page Cache。 - 双重刷盘:
InnoDB刷脏页到磁盘时,数据先到Page Cache,再由操作系统异步刷盘。 - 潜在问题: 内存浪费,
Page Cache可能被其他进程挤占。
- 双重缓存: 数据同时存在于
3.2 O_DIRECT 模式(innodb_flush_method=O_DIRECT)
- 特点:
- 绕过
Page Cache:InnoDB直接管理磁盘I/O,避免双重缓存; - 内存更高效:
Buffer Pool独占内存,不与Page Cache重叠; - 适合场景:
OLTP高并发写入,需严格控制内存使用。
- 绕过
3.3 不同场景
场景 1 :空表首次插入
-
流程:
- InnoDB 在 Buffer Pool 分配新页。
- 插入数据到 Buffer Pool 的新页。
- 记录 Redo Log。
- 异步刷脏页到磁盘(绕过或经过 Page Cache,取决于配置)。
-
Page Cache 参与:
- 若为默认模式(
fsync),脏页刷盘时写入 Page Cache。 - 若为
O_DIRECT,直接写磁盘,不经过 Page Cache。
- 若为默认模式(
场景 2 : 更新已经存在的页
-
流程:
- 若页在 Buffer Pool 中,直接修改。
- 若页不在 Buffer Pool 中,从磁盘加载到 Buffer Pool 后修改。
- 异步刷脏页到磁盘。
-
Page Cache 参与
- 同场景 1,依赖
innodb_flush_method配置。
- 同场景 1,依赖
| 配置模式 | 数据加载路径 | 刷盘路径 | 内存占用特点 |
|---|---|---|---|
fsync(默认) | 磁盘 → Buffer Pool | Buffer Pool → Page Cache → 磁盘 | 双重缓存,内存占用高 |
O_DIRECT | 磁盘 → Buffer Pool | Buffer Pool → 直接写磁盘 | 单一缓存,内存占用可控 |
4. 索引的理解
4.1 理解单个 Page
- MySQL 中一个 page 是
16KB,但是一个表可能很大,所以不止一个 page; - 所以要对这些 page 进行管理,就要用特定的数据结构进行描述和组织。
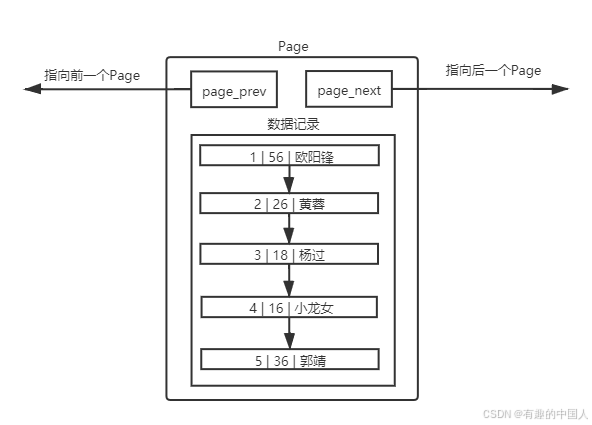
- 不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表;
- 因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序,从上面的 Page 内数据记录可以看出,数据是有序且彼此关联的。
4.2 理解多个 Page
- 通过上面的分析,我们知道,上面页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。
- 但是,我们也可以看到,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
- 如果有1千万条数据,一定需要多个Page来保存1千万条数据,多个Page彼此使用双链表链接起来,而且每个Page内部的数据也是基于链表的。那么,查找特定一条记录,也一定是线性查找。这效率也太低了。
针对上面的单页Page,我们能否也引入目录呢?当然可以
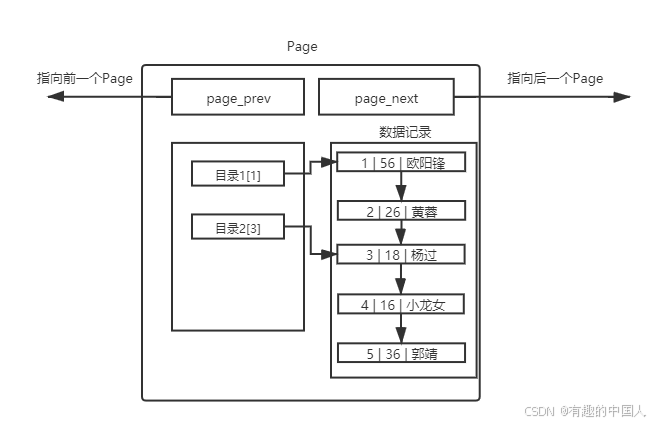
- 那么当前,在一个Page内部,我们引入了目录。比如,我们要查找
id=4记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录2[3],直接进行定位新的起始位置,提高了效率。
4.3 多页情况
- MySQL 中每一页的大小只有 16KB ,单个Page大小固定,所以随着数据量不断增大,
16KB不可能存下所有的数据,那么必定会有多个页来存储数据。
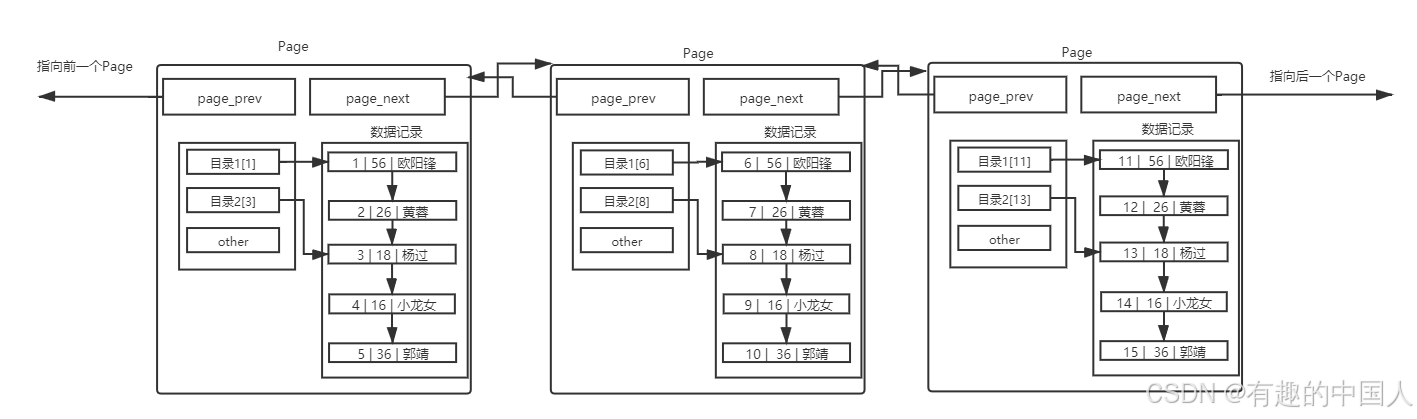
- 这样,我们就可以通过多个Page遍历,Page内部通过目录来快速定位数据。
- 可是,貌似这样也有效率问题,在Page之间,也是需要 MySQL 遍历的,遍历意味着依旧需要进行大量的IO,将下一个Page加载到内存,进行线性检测。
那么如何解决呢?解决方案,其实就是我们之前的思路,给Page也带上目录。
- 使用一个目录项来指向某一页,而这个目录项存放的就是将要指向的页中存放的最小数据的键值。
- 和页内目录不同的地方在于,这种目录管理的级别是页,而页内目录管理的级别是行。
- 其中,每个目录项的构成是:键值+指针。图中没有画全。
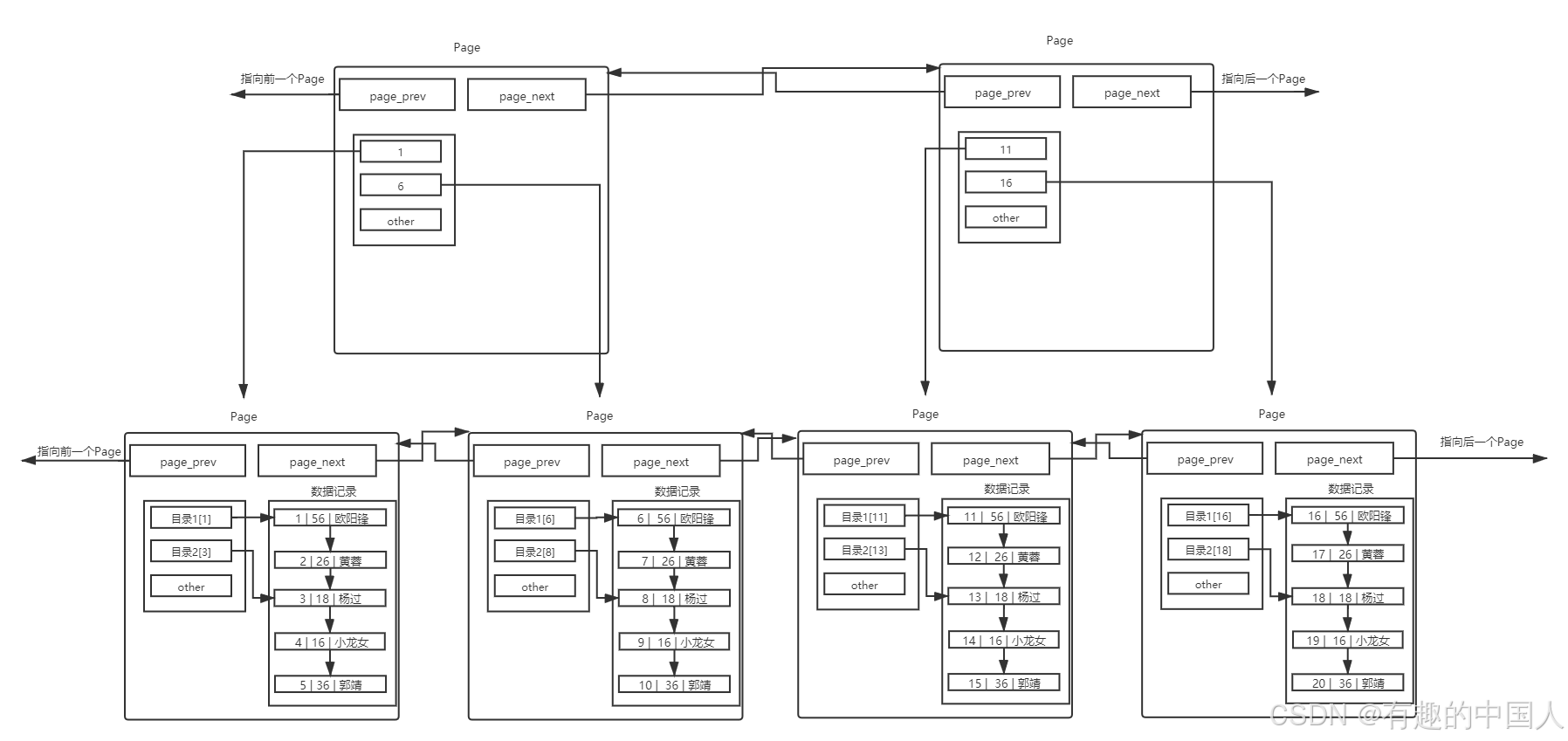
- 存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据。有数据,就可通过比较,找到该访问那个Page,进而通过指针,找到下一个Page。
- 其实目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址。
- 可是,我们每次检索数据的时候,该从哪里开始呢?虽然顶层的目录页少了,但是还要遍历啊?不用担心,可以在加目录页。
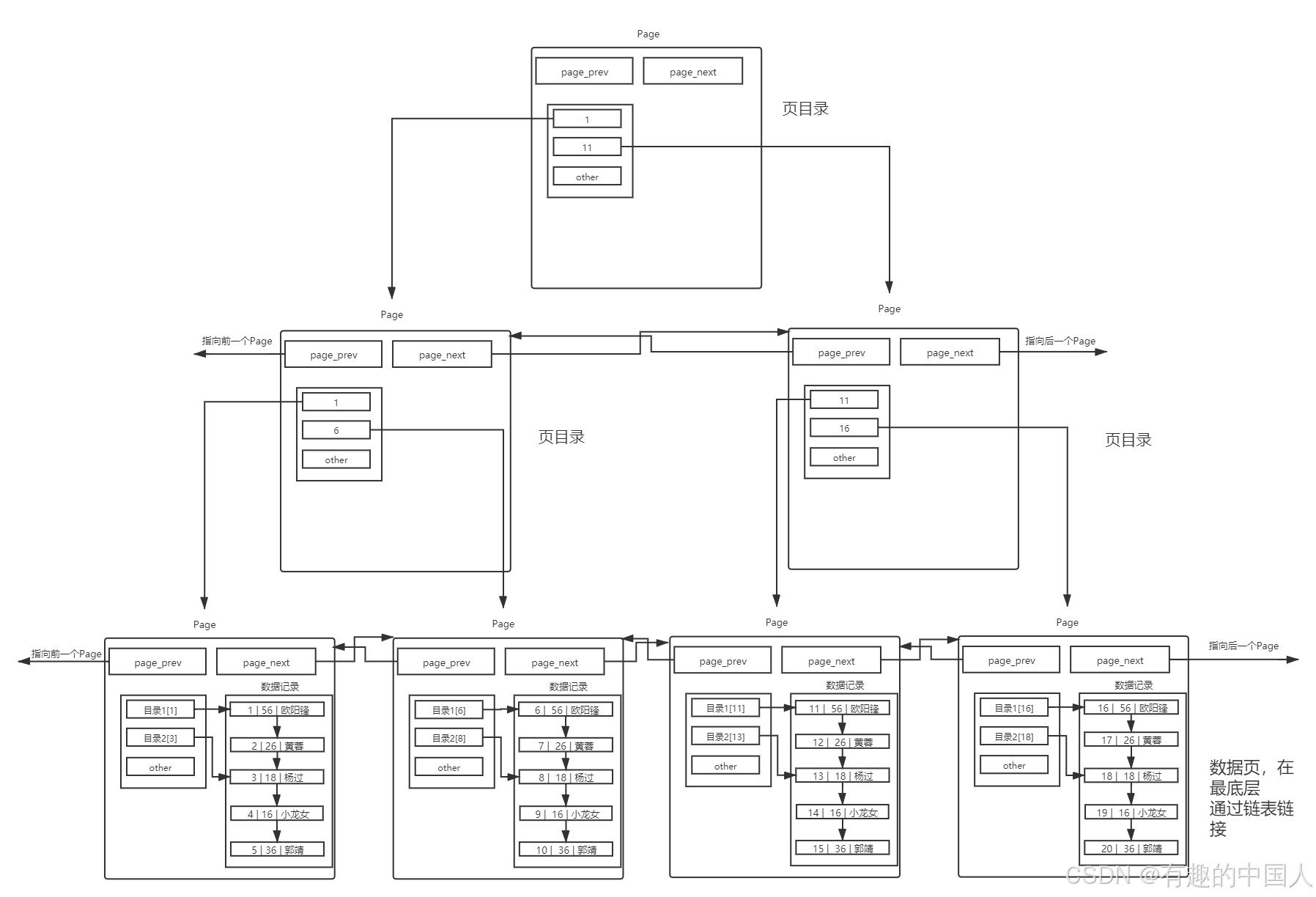
- 这就是传说中的
B+树啊!没错,至此,我们已经给我们的表user构建完了主键索引。 - 随便找一个
id=?我们发现,现在查找的Page数一定减少了,也就意味着IO次数减少了,那么效率也就提高了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









