






DeepSeek-V3-0324 版本改进之处
模型参数与部署优化
- 参数略有放大:新发布的 V3 - 0324 模型参数从之前的 671B 提升到 685B,虽然增幅不大,但也反映了模型在规模上的进一步发展。
- MaC 部署优化与开源:V3 - 0324 具有 700GB 和 MIT 许可证的特点,意味着 MaC 部署得到优化,并且更加开源。MIT 许可证允许任何人出于任何目的使用、修改和分发模型,甚至用于商业目的。

知识截止日期更新
在 DeepSeek 官网提问可知,V3 - 0324 的知识截止日期更新为 2024 年 7 月,而之前的 DeepSeek - V3 是 2023 年 12 月,说明训练数据得到了更新。
Function call 优化
V3 的文档重要变动显示其优化了 Function call,此前版本提示 Function call 会有调用问题,但目前已经支持调用函数。
性能对比优势
与 Claude 系列对比
在数学推理和前端开发方面,网友实测显示 DeepSeek - V3 - 0324 表现优于 Claude3.5 和 Claude3.7 Sonnet。它可轻松免费地创建漂亮的 HTML5、CSS 和前端,而 Claude 不仅有被封号的风险,且每月需 20 美元的使用费用,相比之下 DeepSeek - V3 - 0324 性价比极高12。
与 OpenAI 对比
与 OpenAIo1 - pro 相比,DeepSeek - V3 - 0324 在性能上约可实现 70%,但价格便宜 50 倍,在成本效益方面具有显著优势。
基准测试对比
在 aider 的多语言基准测试中,DeepSeek - V3 - 0324 得分为 55%,比上一版本有显著提升,并且与 DeepSeek - R1 和 OpenAIo3 - mini 等思考模型相比具有竞争力,在官方 API 价格上,它仍旧是最便宜的。
开源特性优势
此前版本是自定义许可证,而 V3 - 0324 彻底支持 MIT 协议。这意味着该模型更加开源,任何人都可以出于任何目的使用、修改和分发它,甚至用于商业目的,还支持模型蒸馏、商业化应用。大家很少将这种尺寸的模型直接全部开源,所以其开源特性具有重要意义,国外有网友提到 DeepSeek 正在实现 Meta 承诺做到的事。
消费级设备运行优势
模型文件总计 641GB,主要以 model - 00035 - of - 000163.safetensors 形式存在,参数量 685B 虽大,但也能在消费级设备上跑起来,例如苹果机器学习工程师 Awni Hannun 就基于 MLX 框架和 4 - bit 量在相关设备上进行操作,这扩大了模型的使用范围和场景。
能力提升
- 前端编程能力显著增强:有用户测试让其生成一个电商网站,不到 3 分钟就写完了 750 行代码,还设置了动态产品卡片悬停效果,以及支持手机端的动态响应式布局,甚至能直接采购。网友实测新模型直接干翻了 DeepSeek R1,与 Claude3.7 相匹敌。在 Aider 的多语言基准测试中,DeepSeek - V3 - 0324 拿下 55%成绩,较前代版本显著提升,成为仅次于 Sonnet3.7 的非推理类模型第二名,其表现可媲美 R1 和 o3 - mini 等具备推理能力的模型。
- 解锁更多玩法:能解锁 Claude3.7 Sonnet 很多玩法,代码可以与之正面较量。从一个球在超立方体弹跳的 Python 脚本,即可看出 V3 代码性能相较上一版的改善。
- 解决特定问题能力增强:在 MisguidedAttention 基准上,跃居非推理类模型榜首,甚至超越了 Claude Sonnet3.7(非推理模型),还能解决一些此前只有推理模型才能处理的提示,比如「4 升水壶问题」,似乎学会了识别推理循环并跳出循环,这种能力是许多专业推理模型都不具备的。
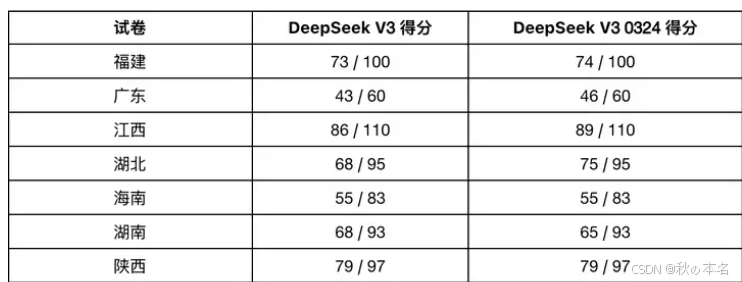
数学能力
有测试找了一个年初大模型都还在做错的小学生数学题,V3 - 0324 能直接回答正确,而 ChatGPT 在 1 月份还在出错,说明其数学能力有明显提升。
首先,可以推知,V3新版使用了R1的数据,V3的输出平均长度来到了5030字符,远高于其他基础模型,甚至部分题目输出达到了12000~13000这种推理模型才有的规模。看内容也确实是复刻先前R1的推导过程,有些题目还保留了R1推理到一半切成英文的“习惯”。
其次,V3虽然很强,但小问题也很多。V3的指令遵循能力与R1接近,都存在较多缺陷。比如#10水果热量问题,V3尽然强行修改题目要求。#22连续计算,上来第一步就忽略题目要求。
对于复杂难题部分,如#4拧魔方,#23解密,#24找数字符规律,V3的智力不够,找不到解法,但这不怪V3,他的先辈R1也是错的。
也有部分字符类问题,R1是稳定正确,如#9数字缩写,#11岛屿计数。R1是接近满分,V3幻觉严重,基本不得分。
在宣称的数学,程序改进方面,确实比V3初版进步显著,但最大问题还是不稳定,编程题可能在全对和全错之间随机。这一点在其中位分比最高分低17%中也能反应出来。
如果是”死对头GPT4.5“对比,二者虽然分数接近。但细节差异很多。
4.5保留了许多来自o1/o3的推理特点,擅长字符类,前面V3丢分的字符类问题,4.5这边得分都较高。而V3可以在数学问题上拿到更多分。
此外,4.5的输出稳定性也稍好。
上下文理解能力
具备更精准的上下文理解能力,从用户测试生成内容时对提示词“a horse riding on top of an astronaut, by grok 3”呈现出不同的理解可以体现。
参考网址:
- ^更新日志 | DeepSeek API Docs
- ^https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
- ^https://huggingface.co/deepseek-ai/DeepSeek-V3
仅供参考!!!


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











