







一、约束的概念和分类
约束是作用于表中列上的规则,用于限制加入表的数据,约束的存在保证了数据库中数据的正确性、有效性和完整性。
1.1、单表约束

利用约束创建表

需要注意的是:
1、主键是一行数据的唯一标识,要求非空且唯一。一张表只能有一个主键。
2、默认约束只有在不给值时才会采用默认值。如果给了null,那值就是null值。
3、auto_increment一般和主键用在一起,当主键类型为int类型时,不给主键赋值时,主键的值会自动增长。
1.2、多表约束

外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性。
利用外键约束创建表,添加外键 dep_id,关联 dept 表的id主键。
创建一个员工表,并使用外键约束和部门表关联到一起。

创建一个部门表

往员工表和部门表中添加元素:


员工表中的dep_id字段是部门表的id字段关联,也就是说1号员工张三属于1号部门研发部的员工。现在我要删除1号部门,会发现无法删除。
所以使用了外键约束,可以保证数据的一致性和完整性。因为如果此时可以删除1号部门,那么属于1号部门的员工这些数据全部都是错误数据,因为他们的部门没有了。
需要注意的是Mysql中innodb是支持外键的,而myisam是不支持外键的。
二、多表查询
多表查询顾名思义就是从多张表中一次性的查询出我们想要的数据。多表查询分为:内连接查询、外连接查询、子查询。

2.1、内连接查询
内连接查询相当于查询 A B 交集数据。内连接查询又分为隐式内连接和显示内连接。
隐示内连接:(平常工作中最常用的)
SELECT 字段列表 FROM 表1,表2… WHERE 条件;
SELECT * FROM emp,dept
WHERE emp.dep_id = dept.did;
显示内连接:
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;
select * from emp inner join dept on emp.dep_id = dept.did;
两种连接方式在查询结果的功能上是等效的,它们都可以实现相同的连接操作。然而在性能和可读性方面存在一些差异。
2.2、外连接查询
左外连接:相当于查询A表所有数据和交集部分数据
右外连接:相当于查询B表所有数据和交集部分数据
查询emp表所有数据和对应的部门信息(左外连接)
select * from emp left join dept on emp.dep_id = dept.did;
查询dept表所有数据和对应的员工信息(右外连接)
select * from emp right join dept on emp.dep_id = dept.did;
2.3、内连接和外连接的区别
创建员工表并插入数据

创建部门表并插入数据

2.3.1、隐示内连接
select *
from tb_dept dp,tb_emp ep
where dp.id=ep.dep_id;得到的结果:

我们发现将拥有部门的员工都查询了出来,并查询了员工所在的部门。也就是满足where条件的都查询了出来, 这里查询的字段是“ * ”,所以查询出来的结果是两张表所有的字段。
2.3.2、外连接查询
部门表左外连接查询员工表
select *
from tb_dept dp
left join tb_emp ep on dp.id = ep.dep_id;得到的结果:

我们发现将部门表中的所有数据都查询了出来,包括不满足on条件的数据,例如:java产品部和java审核部,这两个部门没有员工,所以不满足on条件,但是使用外连接查询依然能查询出来,员工表中不存在的数据用null进行填充。
2.3.3、总结
1、内连接查询只能查出满足where条件的数据。
2、外连接查询能查出主表中的所有数据,不满足on条件的数据主表正常展示,副表用null填充
3、如果是左外连接多张表,也是展示左表的所有字段,右表1、右表2没有的字段还是展示为null
2.4、子查询
查询中嵌套查询,称嵌套查询为子查询。
查询工资高于猪八戒的员工信息。
select * from emp where salary > (select salary from emp where name = '猪八戒');
括号里面的是子查询,用来查询猪八戒的工资,再把这条查询结果当做条件,就形成了嵌套查询。
2.5、union和union all关键字
假设有员工表emp和部门表dept
现在使用union关键字左连接查询两张表的所有结果
select *
from emp e left join dept d on e.dep_id=d.did
union
select *
from emp e right join dept d on e.dep_id=d.did; 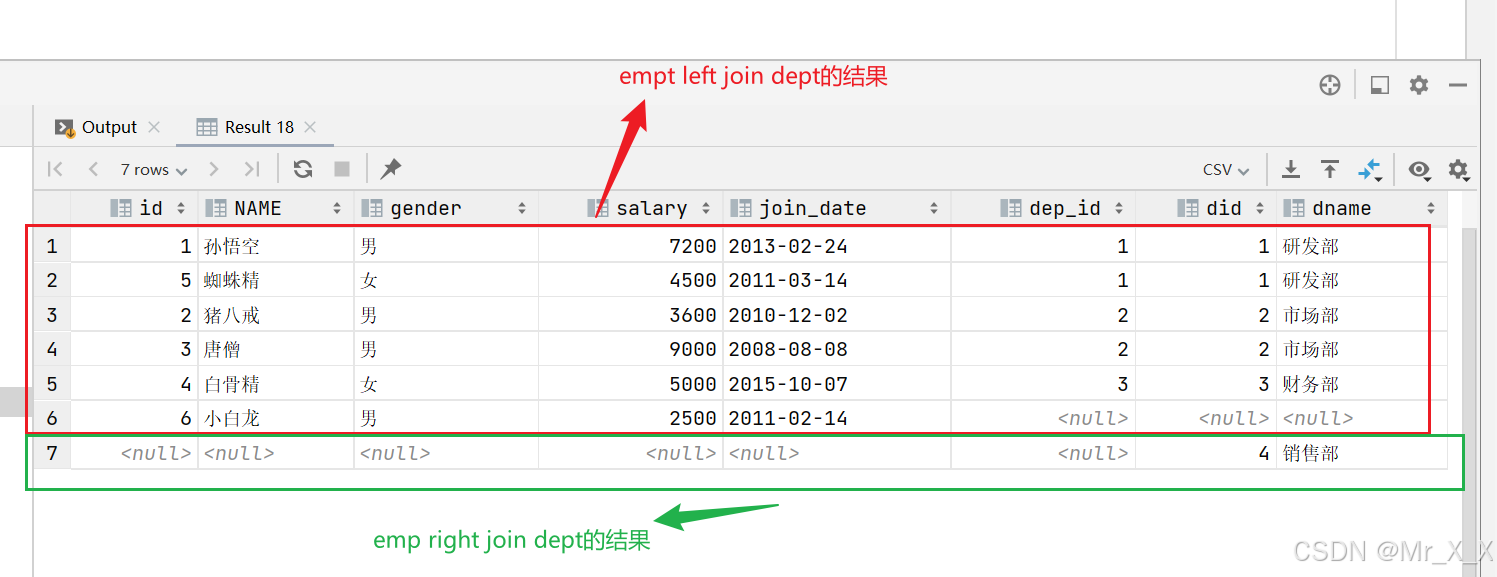
union关键字会把两个查询语句的结果作为并集,并且去重。
现在使用union all关键字左连接查询两张表的所有结果
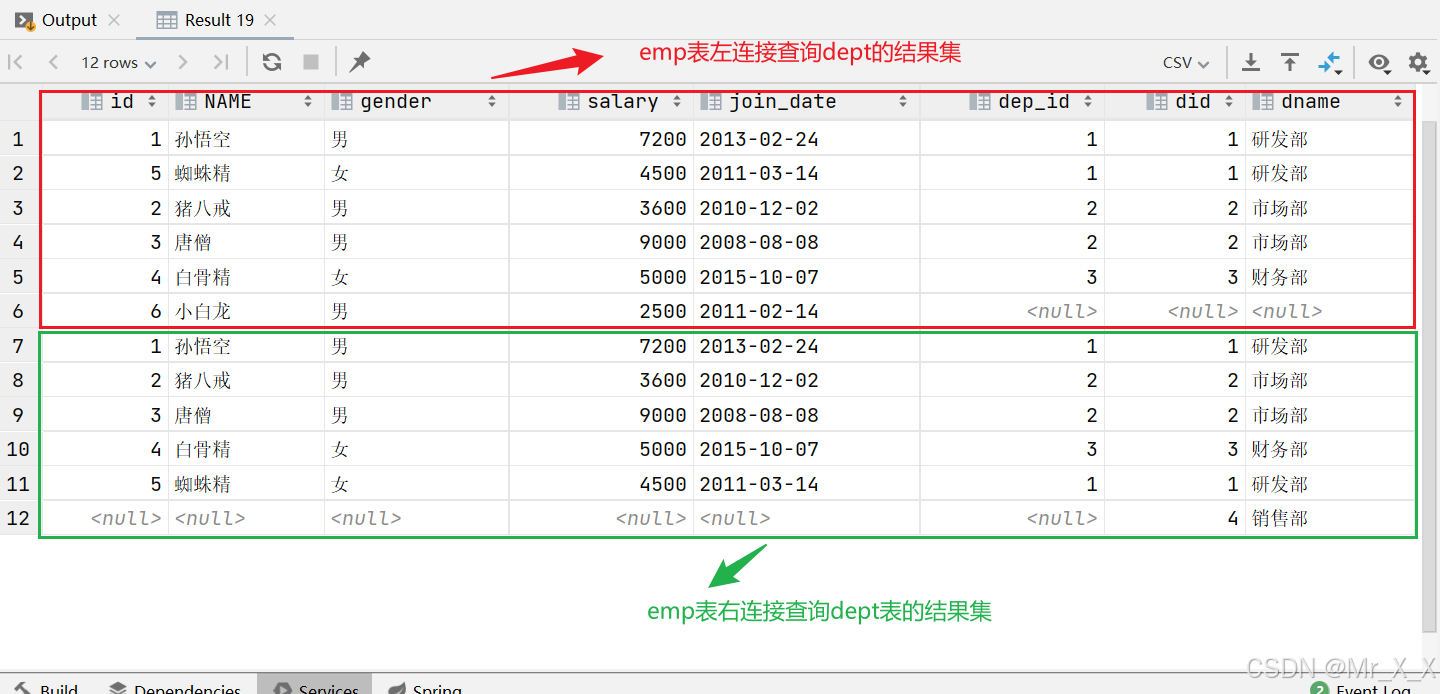
union all关键字会把两个查询语句的结果作为并集,不会去重。
2.6、exists关键字
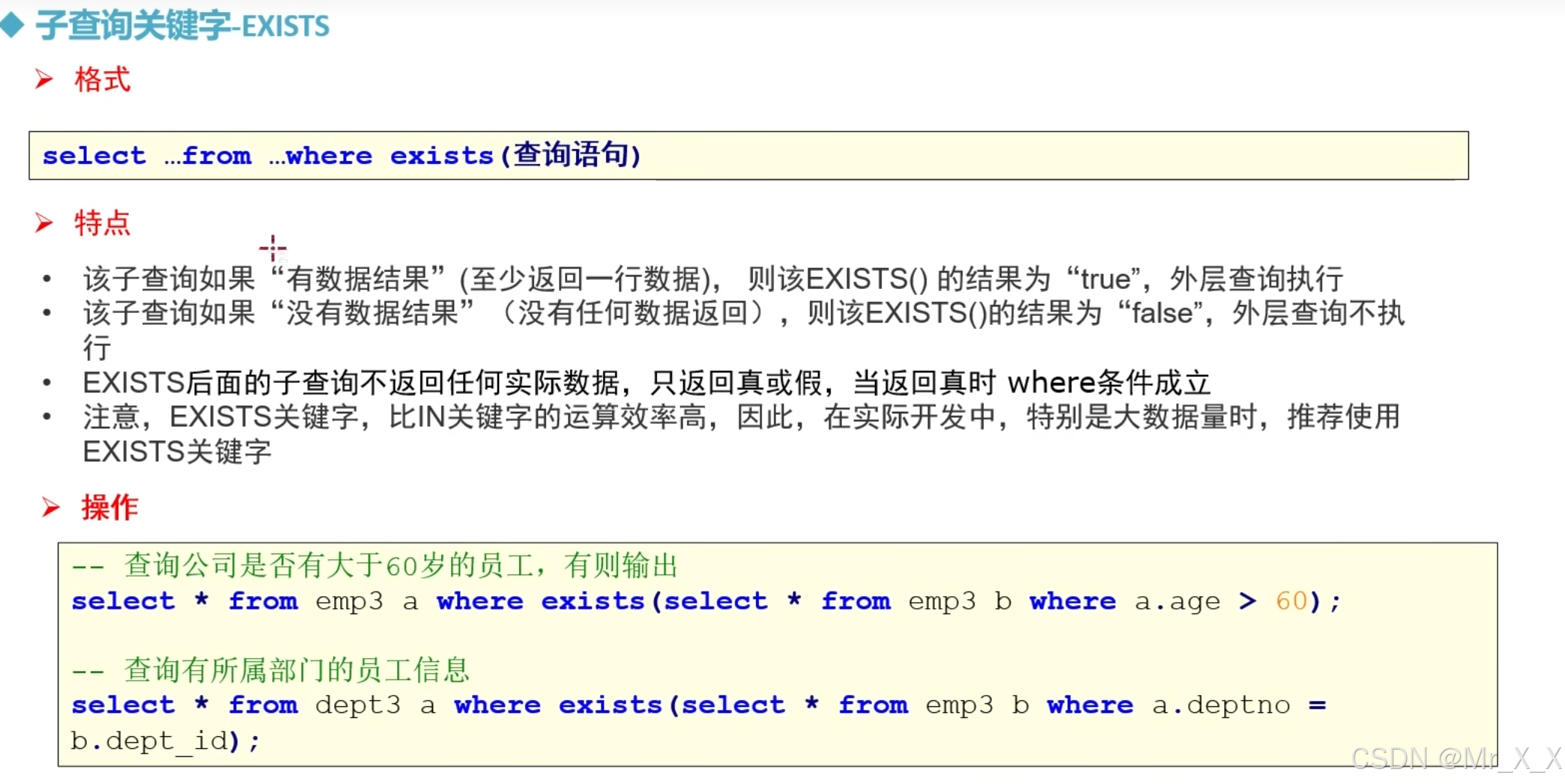
exists关键字里面的查询语句为true才会去执行前面select * from t_mem_info_601 a里面的逻辑,前面select * from t_mem_info_601 a,这里a表一定要在exists表里出现,进行条件判断,exists关键字很多情况下都能被in关键字替换掉
例如此时用户信息表是t_mem_info_601,借款信息表是t_loan_application,此时需要查询已经注册但未申请借款的用户:
方法一:使用exists关键字
select *
from t_mem_info_601 t
where not exists(
select 1 from t_loan_application la
where t.CUSTOMER_NO=la.USER_NO
)首先会去判断exists关键字里面的
select 1 from t_loan_application la
where t.CUSTOMER_NO=la.USER_NO
查询语句为true还是false,如果为true才会去执行外面的
select *
from t_mem_info_601 t
去查询用户信息
注意exists关键字里面的查询语句一定要带上外面 t_mem_info_601 t表中的条件

方法二、使用左连接查询
select *
from t_mem_info_601 t left join t_loan_application la on t.CUSTOMER_NO=la.USER_NO
where la.USER_NO is null;2.7、mapper.xml中使用where1=1,以及select(1)的意义
2.7.1、where1=1的作用
避免拼接动态条件时,出现 SQL 语法错误。
假设我们要查询用户表,根据条件是否传入来拼接查询:
SELECT * FROM t_user WHERE username = 'Tom' AND age = 20;这里的 username 和 age 是查询条件。如果你用 MyBatis 动态 SQL,条件可能是这样:
<select id="selectUsers" parameterType="map" resultType="User">
SELECT * FROM t_user
<where>
<if test="username != null">
username = #{username}
</if>
<if test="age != null">
AND age = #{age}
</if>
</where>
</select>如果 username 是空,只有 age 有值,那拼出来的 SQL 可能是:
SELECT * FROM t_user WHERE AND age = 20;这会导致语法错误,因为 WHERE 后面直接接了 AND
加上 WHERE 1=1 后,条件拼接就更安全
<select id="selectUsers" parameterType="map" resultType="User">
SELECT * FROM t_user
WHERE 1=1
<if test="username != null">
AND username = #{username}
</if>
<if test="age != null">
AND age = #{age}
</if>
</select>
如果只有 age 有值,拼出来的 SQL 会是:
SELECT * FROM t_user WHERE 1=1 AND age = 20;
这样写就 不会出错,因为 WHERE 1=1 本身是一个永远成立的条件
2.7.1、select(1)的作用
select *
from t_mem_info_601 t
where not exists(
select 1 from t_loan_application la
where t.CUSTOMER_NO=la.USER_NO
)exists关键字后面只用判断有没有返回的数据,并不关心查询的字段是什么,如果把select1改成
select * 可能还会造成歧义,认为需要对查询的字段进行处理。
2.8、case when的用法
基本语法:
select
case 6
when 1 then '你好'
when 2 then '新年快乐'
when 6 then '我会发财'
else '既快乐又健康'
end as result;case when的语法和java中的switch case类似,只要其中一个when满足条件,就返回后面的then,不会再执行后面的条件。
case后面的值可以省略,else可以直接省略:
select *,
case
when type=1 then '我会发财'
when type=2 then '我要发财'
when type=3 then '我会成功'
when type=4 then '我要成功'
end as typeStr
from t_user_communication_flow tcase when可以直接在聚合函数count中使用
SELECT
COUNT(CASE WHEN status = 1 THEN 1 END) / COUNT(*) * 100 AS 回填率
FROM
t_user_communication_flow
WHERE
type = 1;三、事务
数据库的事务(Transaction)是一种机制、指的是把一组SQL操作看成一个整体,在执行的过程中要么同时成功,要么同时失败。
具体的例子:
张三和李四的账户中各有1000块钱,现李四需要转500块钱给张三,模拟的转账操作为:
第一步:查询李四账户余额
第二步:从李四账户金额 -500
第三步:给张三账户金额 +500
现在假设在转账过程中第二步完成后出现了异常第三步没有执行,就会造成李四账户金额少了500,而张三金额并没有多500。下图就是出现的错误结果。

使用事务可以解决上述问题

从上图可以看到在转账前开启事务,如果出现了异常回滚事务,三步正常执行就提交事务,这样就可以完美解决问题。
3.1、数据库中事务的语法

将上述案例添加事务后的sql:

上面sql中执行成功则选择执行提交事务,而出现问题则执行回滚事务。但是在实际工作中我们肯定不会这样操作,而是在java代码中进行操作,在java中可以抓取异常,没出现异常提交事务,出现异常回滚事务。
3.2、Mysql和Oracle中关于事务的区别
mysql中的事务是自动提交的。也就是说我们不需要添加3.1中的事务执行sql语句,语句执行完毕会自动的提交事务。
Oracle中的事务是手动提交的,执行完sql语句需要我们手动Commit(提交)或者rollback(回滚)。
3.3、查询数据库中事务的提交方式
可以通过下面语句查询默认提交方式:
SELECT @@autocommit;
查询到的结果是1 则表示自动提交,结果是0表示手动提交。
3.3、事务的四大特征
原子性(Atomicity): 事务是不可分割的最小操作单位,要么同时成功,要么同时失败
一致性(Consistency) :事务完成时,必须使所有的数据都保持一致状态
隔离性(Isolation) :多个事务之间,操作的可见性
持久性(Durability) :事务一旦提交或回滚,它对数据库中的数据的改变就是永久的

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









