




 本文详述了使用Python进行泰坦尼克数据的机器学习分析,包括数据探索、特征工程、多种模型训练及对比。通过数据清洗、新特征生成、统计分析和可视化,揭示了乘客生存的关联因素,如性别、舱位和票价等。最终,通过模型对比,发现决策树和随机森林在该问题上表现出色。
本文详述了使用Python进行泰坦尼克数据的机器学习分析,包括数据探索、特征工程、多种模型训练及对比。通过数据清洗、新特征生成、统计分析和可视化,揭示了乘客生存的关联因素,如性别、舱位和票价等。最终,通过模型对比,发现决策树和随机森林在该问题上表现出色。
目录
大家好,我是吒吒。
Titanic数据是一份经典数据挖掘的数据集,本文介绍的是kaggle排名第一的案例分享。

排名
看下这个案例的排名情况:

第一名和第二名的差距也不是很多,而且第二名的评论远超第一名;有空再一起学习下第二名的思路。
通过自己的整体学习第一名的源码,前期对字段的处理很细致,全面;建模的过程稍微比较浅。
数据探索
导入库
导入整个过程中需要的三类库:
-
数据处理
-
可视化库
-
建模库
# 数据处理
import pandas as pd
import numpy as np
import random as rnd
# 可视化
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 模型
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
导入数据
导入数据后查看数据的大小

字段信息
查看全部的字段:
train.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
下面是字段的具体含义:
-
PassengerId:用户id
-
survival:是否生还,0-否,1-是
-
pclass:舱位,1-头等舱,2-二等,3-三等
-
name:姓名
-
sex:性别
-
Age:年龄
-
sibsp:在船上的兄弟/配偶数
-
parch:在船上父母/孩子数
-
ticket:票号
-
fare:票价
-
cabin:Cabin number;客舱号
-
embarked:登船地点
字段分类
本案例中的数据主要是有两种类型:
-
分类型Categorical: Survived, Sex, and Embarked. Ordinal: Pclass
-
连续型Continous: Age, Fare. Discrete: SibSp, Parch
缺失值
查看训练集和测试集的缺失值情况:

同时也可以通过info函数来查数据的基本信息:

数据假设
作者基于数据的基本信息和常识,给出了自己的一些假设和后面的数据处理和分析方向:
删除字段
-
本项目主要是考察其他字段和Survival字段的关系
-
重点关注字段:Age、Embarked
-
删除字段:对数据分析没有作用,直接删除的字段:Ticket(票号)、Cabin(客舱号)、PassengerId(乘客号)、Name(姓名)
修改、增加字段
-
增加Family:根据Parch(船上的兄弟姐妹个数) 和 SibSp(船上的父母小孩个数)
-
从Name字段中提取Title作为新特征
-
将年龄Age字段转成有序的分类特征
-
创建一个基于票价Fare 范围的特征
猜想
-
女人(Sex=female)更容易生还
-
小孩(Age>?)更容易生还
-
船舱等级高的乘客更容易生还(Pclass=1)
统计分析
主要是对分类的变量Sex、有序变量Pclss、离散型SibSp、Parch进行分析来验证我们的猜想
1、船舱等级(1-头等,2-二等,3-三等)

结论:头等舱的人更容易生还
2、性别

结论:女人更容易生还
3、兄弟姐妹/配偶数
![]()
结论:兄弟姐妹或者配偶数量相对少的乘客更容易生还
4、父母/孩子数
![]()
结论:父母子女在3个的时候,更容易生还
可视化分析
年龄与生还
g = sns.FacetGrid(train, col="Survived")
g.map(plt.hist, 'Age', bins=20)
plt.show()

-
对于未生还的人员,大多数集中在15-25岁(左图)
-
生还人员年龄最大为80;同时4岁以下的小孩生还率很高(右图)
-
乘客的年龄大多数集中在15-35岁(两图)
舱位与生还
grid = sns.FacetGrid(
train,
col="Survived",
row="Pclass",
size=2.2,
aspect=1.6
)
grid.map(plt.hist,"Age",alpha=0.5,bins=20)
grid.add_legend()
plt.show()
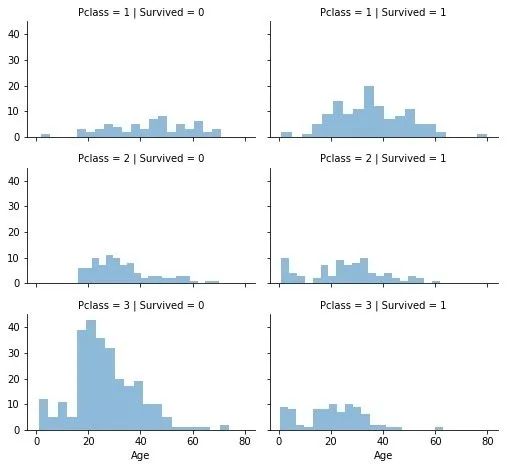
-
舱位等级3的乘客最多;但是很多没有生还
-
舱位等级1的乘客生还最多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









