







 本文介绍如何使用Python爬虫获取tieba的公开数据,包括判断页面类型、寻找URL规律、编写爬虫程序及其组成部分:请求、解析、保存数据函数。还讨论了爬虫程序的结构和随机休眠的必要性。
本文介绍如何使用Python爬虫获取tieba的公开数据,包括判断页面类型、寻找URL规律、编写爬虫程序及其组成部分:请求、解析、保存数据函数。还讨论了爬虫程序的结构和随机休眠的必要性。
提示:文末有福利!最新Python资料/学习指南>>戳我直达
文章目录
前言
本节继续讲解 Python 爬虫实战案例

本节我们将使用面向对象的编程方法来编写程序。
话不多说,开练!
Python爬虫获取tieba公开数据
判断页面类型
通过简单的分析可以得知,待获取的tieba页面属于静态网页,分析方法非常简单:
打开tieba,搜索“Python爬虫”,在出现的页面中复制任意一段信息,比如“爬虫需要 http 代理的原因”,然后点击右键选择查看源码,并使用 Ctrl+F 快捷键在源码页面搜索刚刚复制的数据,如下所示:
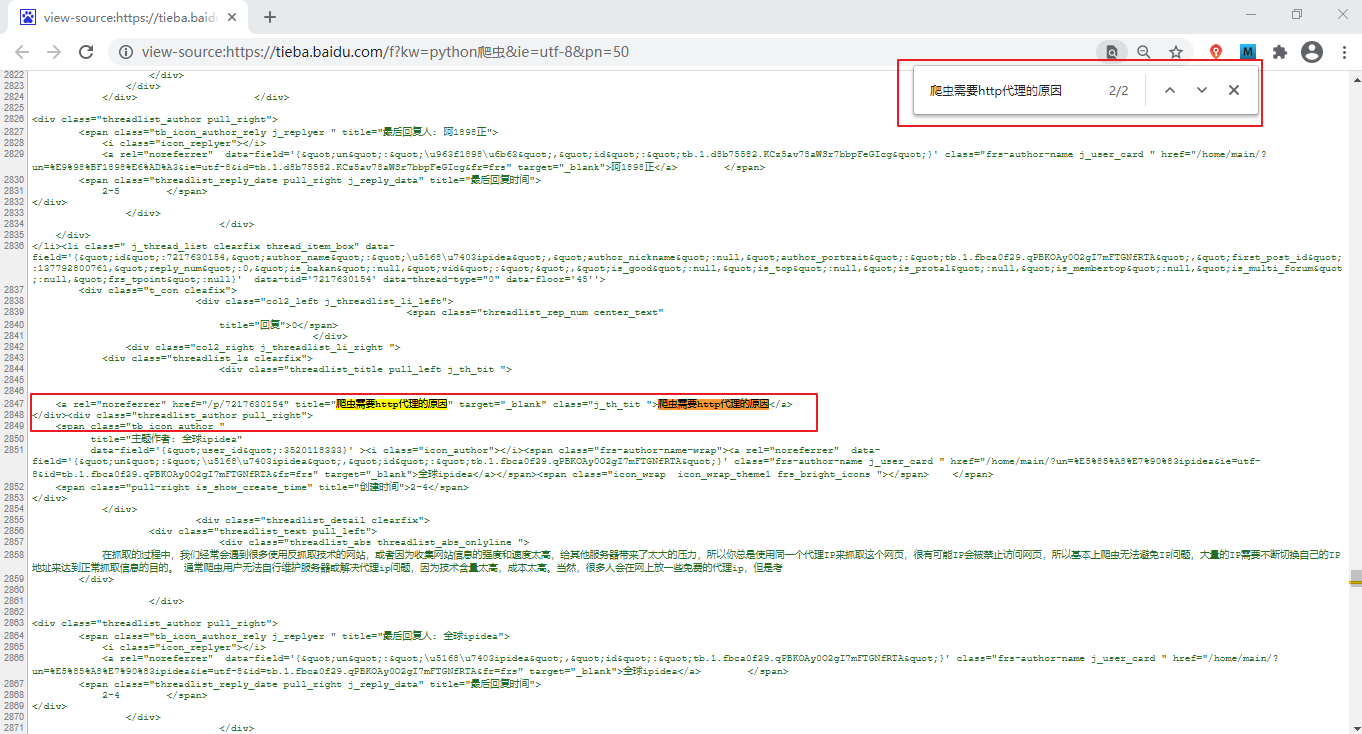
图1:静态网页分析判断
由上图可知,页面内的所有信息都包含在源码页中,数据并不需要从数据库另行加载,因此该页面属于静态页面。
寻找URL变化规律
接下来寻找要爬取页面的 URL 规律,搜索“Python爬虫”后,此时tieba第一页的的 url 如下所示:

点击第二页,其 url 信息如下:

点击第三页,url 信息如下:
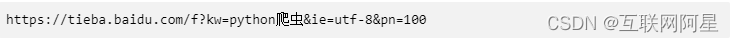
重新点击第一页,url 信息如下:

如果还不确定,您可以继续多浏览几页。最后您发现 url 具有两个查询参数,分别是 kw 和 pn,并且 pn 参数具有规律性,如下所示:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url 地址可以简写为:

编写爬虫程序
下面以类的形式编写爬虫程序,并在类下编写不同的功能函数,代码如下所示:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









