







一、MySQL架构
authentication 认证身份认证账号密码验证->token
authorisation 授权-分配权限菜单
1.1连接层
在mysql服务中,负责客户端连接,进行身份认证,授权
1.2服务层
在服务层进行sql分析,优化,各种逻辑的处理等
1.3引擎层
引擎层是实际负责数据存储和提取操作.mysq提供了不同的引擎(处理方式),可以根据需要进行选择
1.4物理文件存储层
数据存储层,主要是将数据存储在设备的文件系统之上,并完成与存储引擎 的交互。
二、MySQL引擎(数据的存取操作)
2.1.概念:
引擎就是实际负责数据的存储和提取操作的一种实现方式,不同的引擎,实际处理方式是不同的
2.2.mysql引擎

2.2.1.mysq中有以下引擎:
(1)InnoDB:
支持事务(安全可靠),支持行级锁(锁的粒度小,并发量高,类似hashTable和currentHashMap),支持外键约束(删除时有关联关系),支持全文索引,支持数据缓存,提高了查询效率,
不存储总行数(select count(*) from table 统计总行数 逐行统计,效率低)
(2)MyISAM:
myisam不支持事务,不支持外检,不支持行级锁,支持表锁(并发量低),适合写少,查询多的场景
支持全文索引,存储表的总行数
三、索引
3.1什么是索引?
索引是帮助 MySQL 高效获取数据的数据结构。
如果数据库中的数据量非常大那么逐页,逐行查询效率就很低,
索引类似于书的目录,可以帮助我们快速的定位到具体的页数
3.2为什么要有索引?
100 万条数据逐 页查询的时间是无法被用户接受的
(1)优点?
可以快速的定位到数据,减少于硬盘的IO成本
由于索引已经排好序了,减少排序成本,
(2)缺点?
实际上,索引也是一张表,索引信息也是需要占用空间的,当数据发生改变时(新增,删除)那索引信息也要发生改变
3.3索引创建原则(面试)
哪些情况需要创建索引?
主键自动建立唯一(主键)索引工
作为查询条件的列 列如姓名,电话
尽量使用联合索引(几个列添加一个索引) 减少单列索引
数据量较大的表,如果数据量很小,没必要加索引(例如新闻类型 数据量很少)
排序和分组的字段
哪些情况不要创建索引?
如果数据量很小,没必须加索引(例如新闻类型,数据量很少)
频繁修改的表,不仅要修改数据,还要修改索引
不是查询条件的列就不要加索引了
重复出现很多的数据,例如性别
3.4索引的分类
如何在表中加索引
1.主键索引: 把某个列设置成主键后,自动创建主键索引

2.唯一索引

3.单值索引:
一般的列多数添加的都是单值索引,用的最多的.
即一个索引只包含单个列,一个表可以有多个单列索引
创建单值索引 CREATE INDEX 索引名 ON 表名(列名);
删除索引: DROP INDEX 索引名;

4.组合索引(复合索引)
一个索引中包含多个列,降低索引开销(推荐)
创建复合索引 CREATE INDEX 索引名 ON 表名(列 1,列 2...);
删除索引: DROP INDEX 索引名 ON 表名;
组合索引最左前缀原则
组合索引使用时,需要满足组合索引最左前缀原则,否则索引失效

5.前缀索引(解决列内容比较长的问题)
有的列中的内容比较长(新闻摘要,内容),如果给该列建立索引,对索引开销就很大,
给指定长度的区间内容建立索引
create index idx_xxxx on table_name(column(length))
6.全文索引(比like %j% 快)
解决了mysql中模糊查询索引失效的问题
CREATE FULLTEXT INDEX 索引名 ON 表名(字段名) WITH PARSER ngram;
SELECT 结果 FROM 表名 WHERE MATCH(列名) AGAINST(‘搜索词')

3.5索引数据结构(面试高频)
索引结构使用的是B+树 (有序,叶子节点-数据,非叶子节点-索引数据)
首先b+树也是有序的而且一个节点可以存储多个数据,非叶子节点只存储索引数据,
所以每个节点可以存储更多的索引数据,数据记录都存放在叶子节点中.
数据存储在叶子节点,叶子节点直接还有指针指向,更方便范围查询 例如 id>2
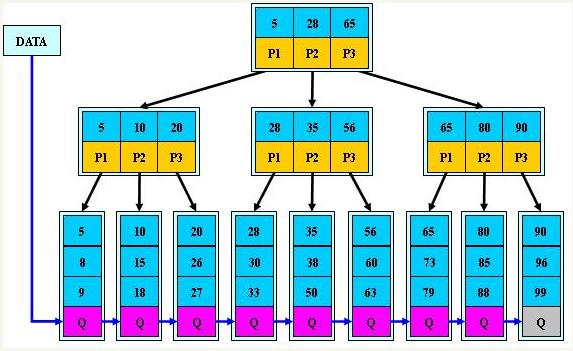
3.6索引的数据结构分为:
(1)聚簇索引(找到索引就找到数据)
找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,
所以 innodb 中的主键索引就是聚簇索引(一级索引),
因为数据和索引都在一个文件中存储,主键索引树直接与数据绑定。
(2)非聚簇索引:(找到索引,还得回表到主键索引,找数据)
找打了索引但是还没找到数据,需要再次回表查询,才能找到数据
myisam中索引和数据分别存储在不同的文件中,所以是非聚簇索引
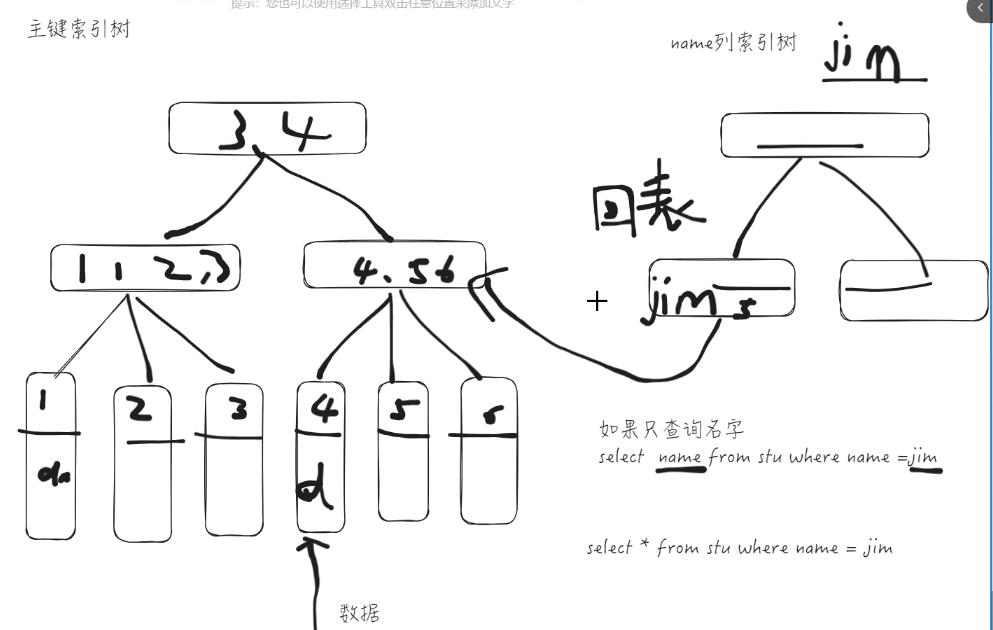
例如为 name 列添加索引(二级索引),我们通过 name 找到后并不能找到数据, 而是需要再找到主键索引,通过主键索引找到数据,这种索引也称为非聚簇索引.
3.7回表查询
三种情况:
1、通过主键索引找数据 2、通过二级索引找数据(回表) 3、通过学号查学号
回表查询就,是查询时,一次并没有查询到我们需要的数据,而是需要再次进行查询.
例如学生信息有id(主键),学号(唯一索引二级索引),姓名(没有加任何索引),
1.如果我们通过主键查询学生所有信息,那么是直接可以找到数据的,不需要回表查询
2.如果我们通过学号查询学生所有信息,先在学号索引树上找到学号,以及主键,然后再二次上主键索引树上查找,才能找到数据,就是发生了两次查询称为回表查询了
3.如果我们通过学号只查询学号,可以直接在学号索引树上找到数据,不会二次回表
3.8索引下推
索引下推是mysql中的一项优化技术,尽量在条件查询时,减少回表查询次数
将部分条件(有索引的条件)查询下推到索引扫描阶段
如果我们查询条件添加了索引,使用索引下推,可以直接在索引树上进行条件筛选,把满足条件的数据进行回表查询,减少了回表查询条数
注意:索引下推,查询条件必须是有索引的.
四、数据库事务
4.1什么是事务
数据库事务就是对一次数据库操作过程的管理,保证一次与数据库交互过程中执行的多条sql要么都成功执行,要么都不执行,保证原子性.
例如:转账
例如:ATM取钱(余额扣了,没取出来)
4.2事务的特征(acid)
原子性(Atom):保证一次操作中的多条$q在没有问题时,提交事务,多条$q都执行,一旦有问题,事 务回滚,回滚到事务开始前
隔离性(isolation):数据库为提高读写的并发性(这里指的是同时),提供4中隔离级别: 读 未提交,读 已提交,可重复 读,串行化(一个个来)
持久性(duration):当事务一旦提交后,保证数据的持久性
一致性(consistent):是事务的终极目标,以上三点都是为了保证一致性,当多个事务同时对一条数据多次操作,最终结果与我们预期结果一致
4.3隔离级别
(1)读 未提交:A事务可以读取到B事务还未提交的数据,并发访问量是最高的
产生的问题:脏读,不可重复读,幻读
脏读:读到的是垃圾数据,A查询到了B事务还未提交的数据,
此时一旦B事务撤销回滚,则数据无效
(2)读 已提交:A事务只能读到B事务已提交的数据,
解决了脏读问题,但是还存在不可重复读问题,
不可重复读:A事务在同一个事务中,读取相同的内容两次,而两次的结果不一样
原因例如 :B事务第一次读A事务还没有提交的数据
第二次读A事务已经提交的数据,导致结果不同
(3)可重复 读(面试重点):A事务在同一个事务中,读取相同的数据两次,两次读取的数据是一致的,即使,
期间其他的事务修改了数据,并提交了,同一个事务读到的同一个数据的结果是一致的
解决了 不可重复读问题,一般的查询也解决了幻读问题。
在查询语句后面,如果添加了for update(查到最新的)这样查询语句,拥有了与新增,修改,删除同等的权利
幻读问题:同一个事务中,读取了两次,而两次读到数量不一致
(4)串行化:和加锁一样,不管增删改查,一次只能允许一个事务进行操作,
两个事务都是读,不互斥
读写,写写都是互斥的
保证数据安全可靠,但效率也是最低的。
4.4事务的实现原理
持久性:在事务提交后,先把数据写到rdo|og日志文件中,再向库中去持久化,一且期间断电宕机,那么服务恢复后,会将redo log文件中的数据再次写入到库中.
原子性:当执行insert操作时,在undo log日志文件中存储一个相反的delete操作,当事务回滚撤销时,执行相反操作。
隔离性(重点):
MVCC(多版本并发控制Multi-Version Concurrent Control)
实现不同的事务在写-读,读写操作时,可以同时进行,提高并发访问能力
每次事务在对数据操作后,都会在表中的隐式字段中记录当前操作者的d,和上一个记录的回滚指针,从而形成一个版本链,
读视图(readView),从版本链上进行的一个快照。
读 已提交:称为当前读,每次读取时,都会获取一个最新的快照。
可重复读:称为快照读,在同一个事务中,第一次查询时,生成一个版本快照(readview),下一次再读取时,还是从快照中读,这样就保证可重复读(每次读取同一个快照)
一致性:有其他三个特性来保障
五、锁机制
锁机制保证了进行数据操作时,保证写操作安全可靠
5.1锁按粒度分为(全局锁,表级锁,行级锁-排它锁):
(1)全局锁:
全局锁就是对整个数据库实例加锁,只能读不能写
例如:其典型的使用场景是做全库的逻辑备份,对所有的表进行锁定,从而获取一 致性视图,保证数据的完整性。
添加全局锁 FLUSH TABLES WITH READ LOCK
释放全局锁 UNLOCK TABLES;

(2)表级锁:
对当前操作的整张表加 锁,被大部分 MySQL 引擎支持。最常使用的 MYISAM.
myisami引擎支持表锁myiam适合读多写少的场景
(3)行级锁:
行级锁是 Mysql 中锁定粒度最细的一种锁,加锁的开销最大
行级锁又分为以下两类(行锁,间隙锁):
行锁
间隙锁:对与范围操作的id>1 and id<10对此区间间隙进行加锁,但对id>10可以操作
行锁有分为:
排它锁:(写锁)新增,修改,删除操作时默认加的就是排他锁,锁住操作的那行数据
查询语句如果执行时,需要添加排他锁,需要在查询语句末尾添加for update
共享锁:(读锁),用于查询语句,事务1加了共享锁,则其他事务只能加共享锁,不能加排它锁(增,删,改默认)。
如果需要为查询语句添加共享锁,可在查询语句后面添加 lock in share mode
如果需要为查询语句添加排他锁,可在查询语句后面添加 for update

六、Sql 优化
6.1 为什么要对 SQL 进行优化
业务数据量的增多,SQL 的执行效率对程序的运行效率的影响逐渐增大,此时对 SQL 的优化
就很有必要。
6.2 Sql优化方法(真假,3,4,9,10)
目前讲的只是写sql基本的一些注意事项,
物理删除(真删),delete操作
逻辑删除(假删),update操作在表中会有一个列,表示删除状态0-未删除,1-已删除
1.查询时,只查询需要的列
尽量不使用select*
2.能使用整数的列,不要使用字符----------字符会降低查询和连接的性能,并会增加存储开销;
例如mysql主键使用int自增
性别,可以用0/1表示
还有各种状态0.1
3.varchar和char区别
varchar:变长字符串varchar(5)表示最大上限个字符,实际存储2字符,只占两个字符大小
char:定长char(5)固定存储5个字符,实际存储2个字符,还是占用5个空间
char一般存储的长度固定的内容
4.清空表数据
truncate table比delete速度快,且使用的系统和事务日志资源少
delete语句每次删除一行,并在事务日志中为所删除的每行记录一项。dml
truncate table通过释放存储表数据所用的数据页来删除数据.----快 ddl
5.建立索引
where order by group by涉及的列添加索引,提高效率避免全表扫描
注意创建索引原则
6.避免索引失效
模糊查询,在条件上使用函数,in,not in or这些语句导致索引失效
7.order by.写法
先条件筛选,再分组,切勿先分组再条件筛选
8.减少表关联查询的数量
阿里建议3张表,索引也不宜过多
9.避免深度分页问题
分页是为了减少每次查询过多数据
selelct*from table limit1000000,10深度分页
select id,name FROM account where id>100000 order by id limit 10;先条件过滤,然后再取值
10.使用explain关键字查看sql执行计划
![]()
explain select from test where a 10
possible_keys:查询中可以使用的索引
key:本次查询实际使用到的索引(可以查看索引是否有效)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









