







目录
第十一章:微调表示模型用于分类-优快云博客![]() https://blog.youkuaiyun.com/m0_67804957/article/details/145923600在本章中,我们将介绍如何对一个预训练的文本生成模型进行微调。微调步骤是生成高质量模型的关键,也是我们工具箱中适应模型特定行为的重要工具。微调可以帮助我们将模型调整到特定的数据集或领域。
https://blog.youkuaiyun.com/m0_67804957/article/details/145923600在本章中,我们将介绍如何对一个预训练的文本生成模型进行微调。微调步骤是生成高质量模型的关键,也是我们工具箱中适应模型特定行为的重要工具。微调可以帮助我们将模型调整到特定的数据集或领域。
在本章中,我们将指导您了解两种最常见的微调方法:监督微调和偏好微调。我们将探索微调预训练文本生成模型的变革性潜力,使其成为您应用中更有效的工具。
一、三步LLM训练过程:预训练、监督微调和偏好微调
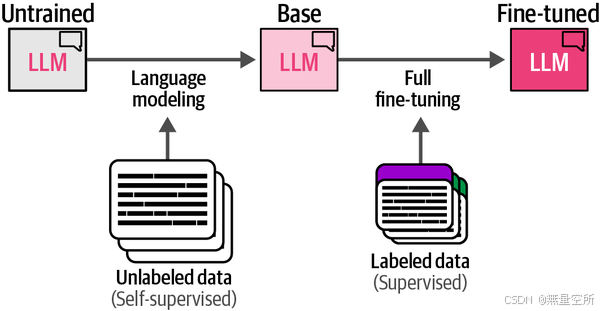
创建高质量LLM的过程通常包括三个常见的步骤:
1、语言建模
创建高质量LLM的第一步是对其进行预训练,通常是在一个或多个庞大的文本数据集上进行(见图12-1)。

在训练过程中,模型尝试预测下一个标记,以准确地学习文本中出现的语言学和语义表示。正如我们在第3章和第11章中看到的,这个过程叫做语言建模,是一种自监督的方法。
这一步产生了一个基础模型,通常也称为预训练模型或基础模型。基础模型是训练过程中的一个重要产物,但对最终用户来说,它的使用较为困难。这也是下一步微调变得尤为重要的原因。
2、微调 1(监督微调)
如果LLM能够很好地响应指令并尽量遵循它们,它就会变得更有用。当人们要求模型写一篇文章时,他们希望模型生成文章内容,而不是列出其他指令(例如基础模型可能会做的事)。
通过监督微调(SFT),我们可以使基础模型更好地遵循指令。在这个微调过程中,基础模型的参数被更新,以更符合我们的目标任务,比如遵循指令。与预训练模型类似,SFT使用下一个标记预测进行训练,但与其不同的是,模型的预测是基于用户输入的(见图12-2)。

SFT也可以用于其他任务,如分类,但通常用于将基础生成模型转变为指令生成模型(或聊天生成模型)。
3、微调 2(偏好微调)
最后一步进一步提高模型质量,使其更符合AI安全或人类偏好的预期行为。这就是所谓的偏好微调。
偏好微调是一种微调形式,正如其名称所示,它将模型的输出调整为我们的偏好,而这些偏好是由我们提供的数据定义的。与SFT类似,偏好微调可以改进原始模型,但其额外的好处是,在训练过程中它能够提炼输出的偏好。
这三步过程在图12-3中得到了说明,展示了从未训练的架构开始,到偏好微调的LLM结束的过程。

在本章中,我们使用一个已经在庞大数据集上训练过的基础模型,并探索如何使用这两种微调策略对其进行微调。对于每种方法,我们首先介绍其理论基础,然后再在实践中应用。
二、监督微调(SFT)
预训练模型在大数据集上的目的是使其能够再现语言及其含义。在这个过程中,模型会学习根据输入来完成短语,如图12-4所示。
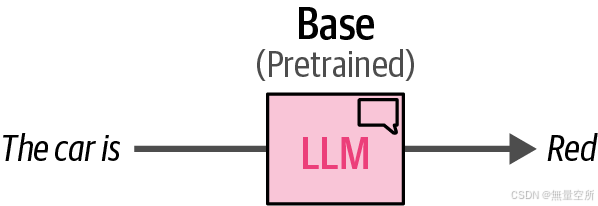
这个例子也说明了,模型并没有被训练来遵循指令,而是会尝试完成一个问题,而不是回答它(见图12-5)。
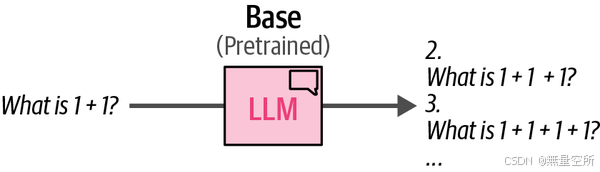
我们可以利用这个基础模型,并通过微调使其适应特定的应用场景,比如遵循指令。
2.1 完全微调
最常见的微调过程是完全微调。与LLM的预训练类似,这个过程涉及更新模型的所有参数,使其符合目标任务。主要的区别在于,这次我们使用的是一个较小但有标签的数据集,而预训练过程则是在没有标签的大数据集上完成的(见图12-6)。
任何有标签的数据都可以用于完全微调,这使得它成为学习领域特定表示的好方法。为了使我们的LLM遵循指令,我们需要问答数据。这个数据,如图12-7所示,是用户提出的问题和对应的答案。

在完全微调过程中,模型接受输入(指令),并对输出(回答)应用下一个标记预测。反过来,模型将不再生成新的问题,而是会遵循指令。
2.2 参数高效微调(PEFT)
更新模型的所有参数有很大的潜力可以提高性能,但也伴随着一些缺点。训练成本高、训练时间慢且需要大量存储。为了解决这些问题,越来越多的注意力转向了参数高效微调(PEFT)技术,它聚焦于以更高的计算效率微调预训练模型。
适配器
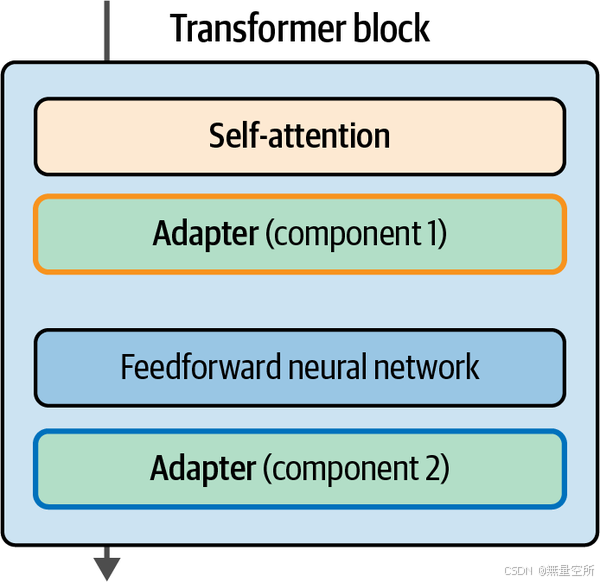
适配器是许多PEFT技术的核心组成部分。该方法提出在Transformer内部添加一组额外的模块化组件,可以微调这些组件以提高模型在特定任务上的表现,而无需微调所有模型权重。这样可以节省大量时间和计算资源。
适配器在《Parameter-efficient transfer learning for NLP》论文中进行了描述,论文表明,微调BERT 3.6%的参数就能在任务上达到与微调所有模型权重相当的表现。1 在GLUE基准测试中,作者们展示了它们的表现仅比完全微调低0.4%。在单个Transformer块中,论文提出的架构在注意力层和前馈神经网络后添加了适配器,如图12-8所示。
然而,仅仅改变一个Transformer块是不够的,因此这些组件是模型中每个块的一部分,如图12-9所示。
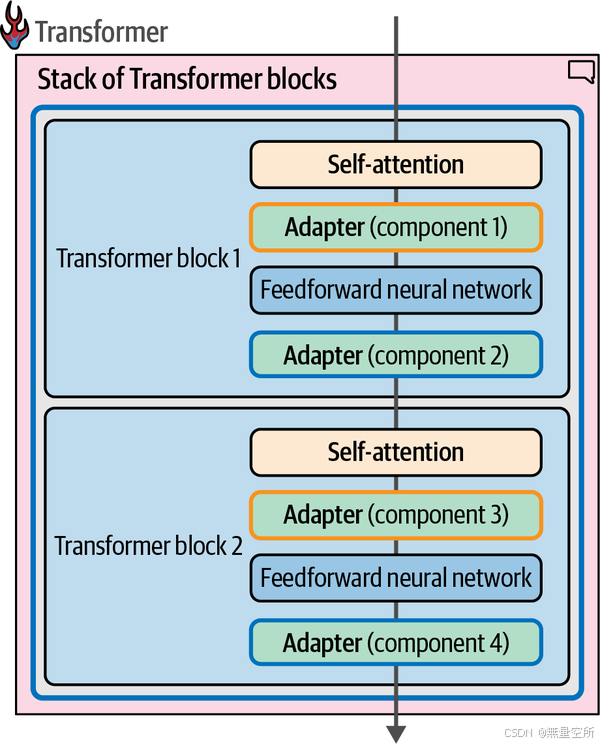
看到整个模型中的适配器组件后,我们可以看到个别适配器,如图12-10所示,这些适配器跨越模型的所有块。适配器1可以专门用于医学文本分类,适配器2则可以专门用于命名实体识别(NER)。你可以从这里下载专门的适配器。
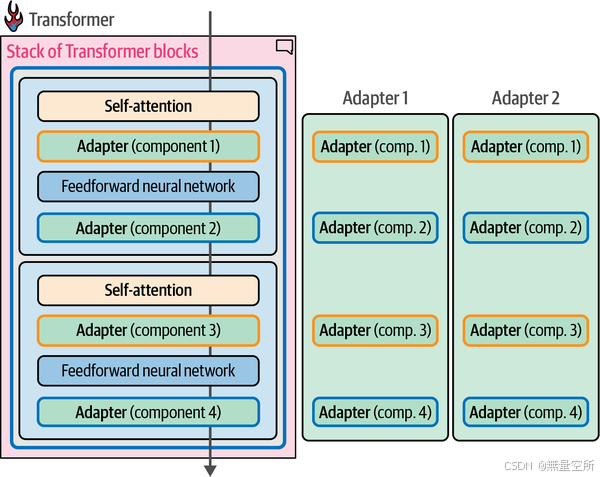
《AdapterHub: A framework for adapting transformers》论文介绍了Adapter Hub,它是一个中央存储库,用于共享适配器。2 这些早期的适配器更多地关注BERT架构。最近,这一概念已被应用于文本生成Transformer,如论文《LLaMA-Adapter: Efficient fine-tuning of language models with zero-init attention》所示。3
低秩适配(LoRA)
作为适配器的替代方法,低秩适配(LoRA)被提出,并且在写作时已经成为PEFT中广泛使用且有效的技术。LoRA是一种技术,它(像适配器一样)仅需要更新一小部分参数。如图12-11所示,它通过创建基础模型的一小部分来进行微调,而不是向模型中添加新的层。
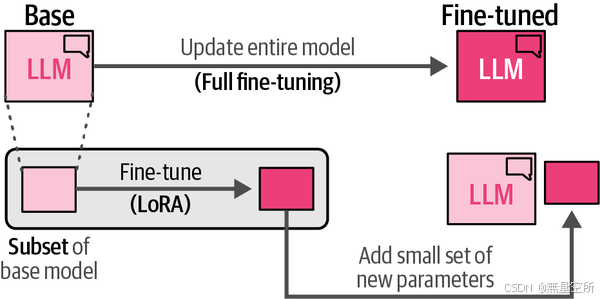
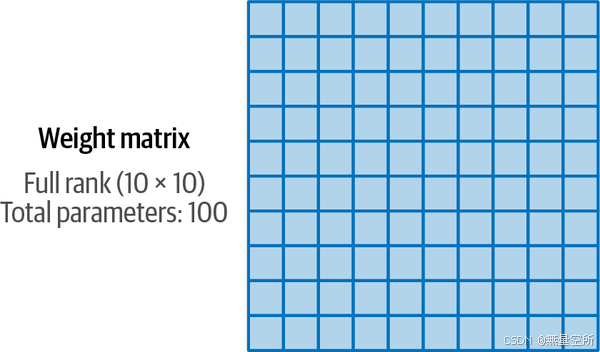
与适配器一样,这个子集允许更快的微调,因为我们只需要更新基础模型的一小部分。我们通过用更小的矩阵来逼近原始LLM所附带的大矩阵,从而创建这个参数子集。然后,我们可以使用这些较小的矩阵来替代原始的大矩阵进行微调。例如,在图12-12中,我们看到一个10 × 10的矩阵。
我们可以创建两个较小的矩阵,通过相乘重建一个10 × 10的矩阵。这是一个效率上的大幅提升,因为我们不再使用100个权重(10乘10),而是只使用20个权重(10加10),如图12-13所示。
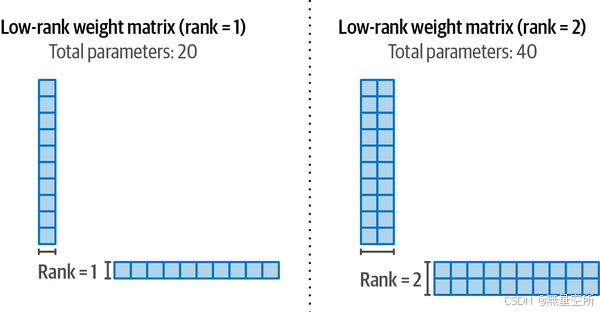
在训练过程中,我们只需要更新这些较小的矩阵,而不是整个权重的变化。更新后的矩阵(较小的矩阵)将与完整的(冻结的)权重结合,如图12-14所示。
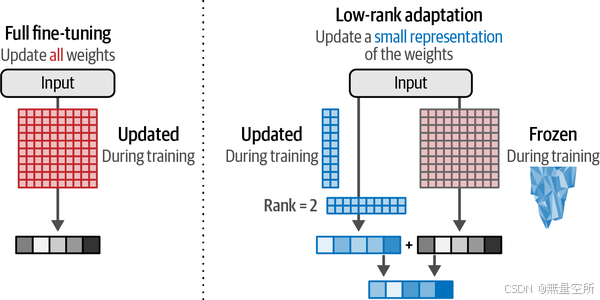
但你可能会怀疑,性能是否会下降。你是对的。那么,在哪些情况下这种权衡是有意义的呢?
《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》一文表明,语言模型“具有非常低的内在维度”。5 这意味着我们可以找到小的秩来逼近即使是LLM的庞大矩阵。例如,一个像GPT-3这样的175B模型,其每个Transformer块中的权重矩阵是12,288 × 12,288,拥有1.5亿个参数。如果我们能够将该矩阵适配成秩为8的矩阵,这样只需要两个12,288 × 2的矩阵,每个块的参数量为197K。这为速度、存储和计算带来了巨大的节省,正如前文所述的LoRA论文中进一步阐述的那样。
这种较小的表示非常灵活,你可以选择微调基础模型的哪些部分。例如,我们只微调每个Transformer层中的Query和Value权重矩阵。
压缩模型以提高训练效率
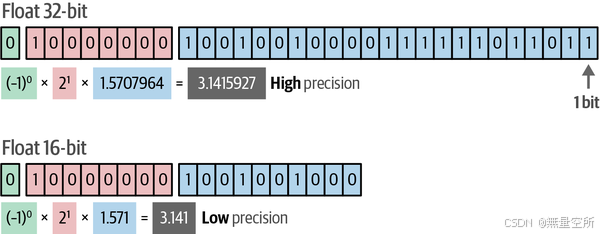
我们可以通过减少模型原始权重的内存需求,进一步提高LoRA的效率。在LLM中,权重是具有特定精度的数值,可以用位数如float64或float32表示。如图12-15所示,如果我们降低表示值的位数,就会得到较不准确的结果。然而,降低位数的同时也降低了模型的内存需求。
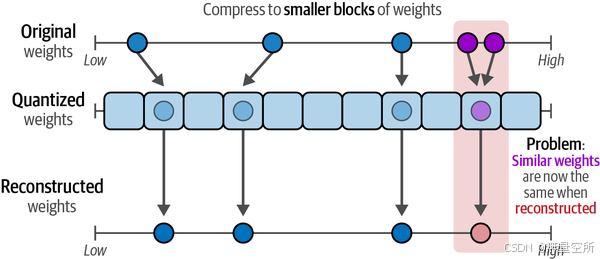
通过量化,我们的目标是降低位数,同时仍能准确地表示原始权重值。然而,如图12-16所示,当直接将高精度值映射到低精度值时,多个高精度值可能最终被表示为相同的低精度值。
不过,《QLoRA: A quantized version of LoRA》一文的作者们找到了一种方法,可以在不与原始权重区分过多的情况下,将较高位数的权重转换为较低位数的权重,反之亦然。6
他们采用了块式量化的方法,将高精度值的某些块映射到低精度值。这样,不是直接将高精度值映射为低精度值,而是创建了额外的块,使得相似的权重可以一起量化。如图12-17所示,这可以通过量化块准确表示权重。
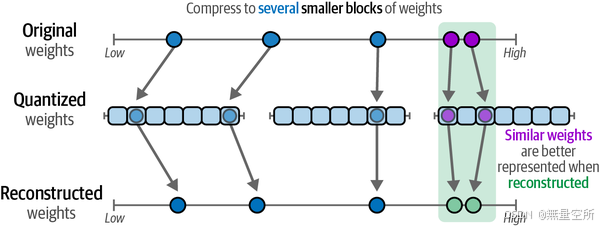
神经网络的一个优点是它们的值通常在-1和1之间正态分布。这个特性使得我们可以根据权重的相对频率将原始权重映射到较低位数,如图12-18所示。量化权重的映射效率更高,因为它考虑了权重的相对密度,也减少了异常值的问题。
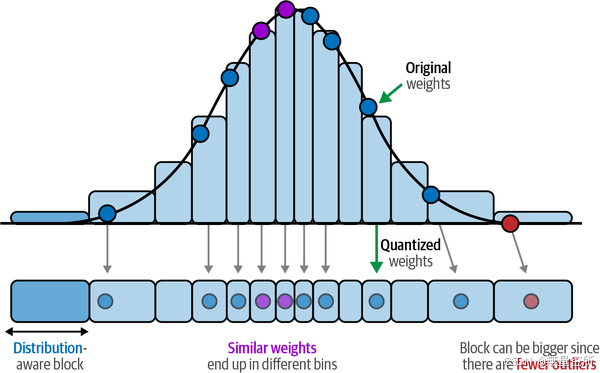
结合块式量化,这种归一化过程可以使低精度值准确表示高精度值,同时性能的下降非常小。因此,我们可以将16位浮点表示降低到4位浮点表示。4位表示显著减少了LLM在训练期间的内存需求。值得注意的是,LLM的量化通常对推理也有帮助,因为量化后的LLM体积较小,因此需要更少的VRAM。
有更多优雅的方法可以进一步优化这一点,比如双重量化和分页优化器,你可以在前述的QLoRA论文中阅读更多内容。关于量化的完整且高度可视化的指南,请参阅这篇博客文章。
三、使用QLoRA进行指令微调
现在我们已经探讨了QLoRA的工作原理,接下来我们将把这些知识付诸实践!在本节中,我们将使用QLoRA程序对完全开源的较小版本Llama,TinyLlama,进行微调,使其能够遵循指令。把这个模型看作一个基础或预训练模型,它是用语言建模训练的,但还不能遵循指令。
3.1 模板化指令数据
为了让LLM遵循指令,我们需要准备遵循聊天模板的指令数据。这个聊天模板,如图12-19所示,区分了LLM生成的内容和用户生成的内容。
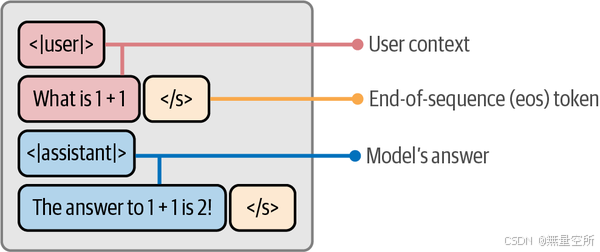
我们选择这个聊天模板是因为TinyLlama的聊天版本使用相同的格式。我们使用的数据是UltraChat数据集的一个小子集。该数据集是原始UltraChat数据集的过滤版本,包含了近20万条用户与LLM之间的对话。
我们创建一个函数format_prompt,确保这些对话遵循这个模板:
from transformers import AutoTokenizer
from datasets import load_dataset
# 加载用于模板的分词器
template_tokenizer = AutoTokenizer.from_pretrained(
"TinyLlama/TinyLlama-1.1BChat-v1.0"
)
def format_prompt(example):
"""根据TinyLlama使用的模板格式化提示"""
# 格式化答案
chat = example["messages"]
prompt = template_tokenizer.apply_chat_template(chat, tokenize=False)
return {"text": prompt}
# 加载并格式化数据,使用TinyLlama的模板
dataset = (
load_dataset("HuggingFaceH4/ultrachat_200k", split="test_sft")
.shuffle(seed=42)
.select(range(3_000))
)
dataset = dataset.map(format_prompt)
我们选择了3000个文档的子集来减少训练时间,但你可以增加这个值,以获得更准确的结果。
使用“text”列,我们可以查看这些格式化后的提示:
# 格式化后的示例提示
print(dataset["text"][2576])
输出:
<|user|>
Given the text: Knock, knock. Who's there? Hike.
Can you continue the joke based on the given text material "Knock, knock. Who's there? Hike"?</s>
<|assistant|>
Sure! Knock, knock. Who's there? Hike. Hike who? Hike up your pants, it's cold outside!</s>
<|user|>
Can you tell me another knock-knock joke based on the same text material "Knock, knock. Who's there? Hike"?</s>
<|assistant|>
Of course! Knock, knock. Who's there? Hike. Hike who? Hike your way over here and let's go for a walk!</s>
3.2 模型量化
现在我们已经准备好数据,可以开始加载我们的模型。这时,我们将应用QLoRA中的Q,即量化。我们使用bitsandbytes库将预训练模型压缩为4位表示。
在BitsAndBytesConfig中,我们可以定义量化方案。我们遵循原始QLoRA论文中的步骤,并以4位(load_in_4bit)的精度加载模型,使用标准化的浮点表示(bnb_4bit_quant_type)和双重量化(bnb_4bit_use_double_quant):
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T"
# 4位量化配置 - QLoRA中的Q
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 使用4位精度加载模型
bnb_4bit_quant_type="nf4", # 量化类型
bnb_4bit_compute_dtype="float16", # 计算数据类型
bnb_4bit_use_double_quant=True, # 应用嵌套量化
)
# 加载模型以在GPU上进行训练
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
# 如果进行常规SFT,可以省略这个
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# 加载LLaMA分词器
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = "<PAD>"
tokenizer.padding_side = "left"
这个量化过程允许我们在减少模型大小的同时保持大部分原始权重的精度。现在加载模型只需约1 GB的VRAM,而未经量化时则需要大约4 GB的VRAM。请注意,在微调过程中,可能会需要更多的VRAM,所以训练时可能会超出大约1 GB VRAM的限制。
3.3 LoRA配置
接下来,我们需要使用peft库定义LoRA配置,这表示微调过程的超参数:
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
# 准备LoRA配置
peft_config = LoraConfig(
lora_alpha=32, # LoRA缩放因子
lora_dropout=0.1, # LoRA层的Dropout
r=64, # 秩
bias="none",
task_type="CAUSAL_LM",
target_modules= # 目标层
["k_proj", "gate_proj", "v_proj", "up_proj", "q_proj", "o_proj", "down_proj"]
)
# 准备模型进行k位训练
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
这里有几个参数值得注意:
- r:这是压缩矩阵的秩(参考图12-13)。增加此值会增加压缩矩阵的大小,从而减少压缩效果,但可以提高表示能力。通常值在4到64之间。
- lora_alpha:控制原始权重中添加的变化量。实际上,它平衡了原始模型和新任务的知识。经验法则是选择
r的两倍作为lora_alpha的值。 - target_modules:控制要调整的层。LoRA过程可以选择忽略特定层,例如特定的投影层。这可以加速训练,但可能会降低性能,反之亦然。
通过调整这些参数,可以进行一系列实验,从而获得对不同值的直观理解。
3.4 训练配置
最后,我们需要配置训练参数,如同第11章所做的:
from transformers import TrainingArguments
output_dir = "./results"
# 训练参数
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
learning_rate=2e-4,
lr_scheduler_type="cosine",
num_train_epochs=1,
logging_steps=10,
fp16=True,
gradient_checkpointing=True
)
这里有几个参数值得关注:
- num_train_epochs:训练轮数。较高的值可能会导致性能下降,因此通常保持较低。
- learning_rate:每次权重更新的步长。QLoRA的作者发现,对于较大的模型(>33B参数),较高的学习率效果更好。
- lr_scheduler_type:基于余弦的调度器,可以动态调整学习率。它会从零开始线性增加学习率,直到达到设定值,然后按余弦函数的值衰减。
- optim:在原始QLoRA论文中使用的分页优化器。
优化这些参数是一个困难的任务,并且没有固定的指南可以遵循。需要通过实验找到适合特定数据集、模型大小和目标任务的配置。
注意
虽然本节描述的是指令微调,但我们也可以使用QLoRA来微调指令模型。例如,我们可以微调一个聊天模型,使其生成特定的SQL代码或创建符合特定格式的JSON输出。只要你有合适的数据(包括适当的查询-响应项),QLoRA就是一个非常有效的技术,可以让现有的聊天模型更适应你的使用场景。
3.5 训练
现在我们已经准备好所有模型和参数,可以开始微调模型了。我们加载SFTTrainer并简单地运行trainer.train():
from trl import SFTTrainer
# 设置监督微调参数
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
max_seq_length=512,
# 如果是常规SFT,可以省略此项
peft_config=peft_config,
)
# 训练模型
trainer.train()
# 保存QLoRA权重
trainer.model.save_pretrained("TinyLlama-1.1B-qlora")
在训练过程中,损失将在每10步打印一次,具体由logging_steps参数控制。如果你使用的是Google Colab提供的免费GPU(目前为Tesla T4),训练可能需要一个小时。正好可以休息一下!
3.6 合并权重
训练完成并保存QLoRA权重后,我们仍然需要将它们与原始权重合并,以便使用。我们重新加载模型为16位,而不是量化后的4位,然后合并权重。虽然训练期间分词器没有更新,但我们会将其保存在与模型相同的文件夹中,以便于访问:
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
"TinyLlama-1.1B-qlora",
low_cpu_mem_usage=True,
device_map="auto",
)
# 合并LoRA和基础模型
merged_model = model.merge_and_unload()
在将适配器与基础模型合并后,我们可以使用我们之前定义的提示模板:
from transformers import pipeline
# 使用我们预定义的提示模板
prompt = """<|user|>
Tell me something about Large Language Models.</s>
<|assistant|>
"""
# 运行我们指令微调后的模型
pipe = pipeline(task="text-generation", model=merged_model, tokenizer=tokenizer)
print(pipe(prompt)[0]["generated_text"])
输出结果将展示模型如何遵循我们给定的指令,这在原始模型中是无法实现的。
四、生成模型评估
评估生成模型是一项具有挑战性的任务。生成模型广泛应用于多种用例,这使得依赖单一度量标准进行评估变得困难。与更为专业化的模型不同,一个生成模型在解决数学问题的能力并不意味着它能成功地解决编码问题。
与此同时,评估这些模型在生产环境中至关重要,尤其是当一致性非常重要时。由于生成模型的概率性质,它们未必能够生成一致的输出,因此需要一种稳健的评估方法。
在本节中,我们将探讨几种常见的评估方法,但我们要强调的是,目前缺乏黄金标准。没有一种度量标准适用于所有用例。
4.1 词汇级别的评估指标
用于比较生成模型的常见指标之一是词汇级评估。这些经典技术通过比较参考数据集与生成的标记(令牌)来评估模型。常见的词汇级指标包括困惑度(perplexity)、ROUGE、BLEU 和 BERTScore。
特别需要注意的是困惑度,它衡量语言模型预测文本的效果。给定输入文本,模型预测下一个标记的可能性。对于困惑度而言,我们假设模型表现更好,如果它对下一个标记给予较高的概率。换句话说,当模型面对一篇写得很好的文章时,它不应该“困惑”。
如图12-20所示,当输入是“当一个度量变成...”,模型需要预测“target”作为下一个词的可能性。

尽管困惑度等词汇级别的指标对理解模型的信心水平有帮助,但它们并不是完美的衡量标准。它们没有考虑生成文本的一致性、流畅性、创造性甚至正确性。
基准(Benchmarks)
评估生成模型在语言生成和理解任务中的常用方法是使用一些知名且公开的基准数据集,如MMLU、GLUE、TruthfulQA、GSM8k 和 HellaSwag。这些基准能够为我们提供有关基础语言理解的有用信息,也涉及复杂的分析性回答,如数学问题。
除了自然语言任务外,一些模型还专门处理其他领域,如编程。这些模型通常在不同的基准上进行评估,例如HumanEval,它包含挑战性的编程任务供模型解决。表12-1列出了常见的生成模型公开基准。
表12-1. 生成模型常见公开基准
| 基准 | 描述 | 资源 |
|---|---|---|
| MMLU | 大型多任务语言理解(MMLU)基准测试模型在57个不同任务上的表现,包括分类、问答和情感分析。 | 链接 |
| GLUE | 通用语言理解评估(GLUE)基准包括涵盖各种难度的语言理解任务。 | 链接 |
| TruthfulQA | TruthfulQA 衡量模型生成文本的真实性。 | 链接 |
| GSM8k | GSM8k 数据集包含适合学龄儿童的数学文字问题。它在语言上具有多样性,由人工问题作者创建。 | 链接 |
| HellaSwag | HellaSwag 是评估常识推理的挑战数据集。它包含多项选择题,模型需要回答每个问题并从四个选项中选择一个。 | 链接 |
| HumanEval | HumanEval 基准用于评估生成代码,包含164个编程问题。 | 链接 |
基准是评估模型在各种任务上的表现的好方法。基准的缺点是,模型可能会对这些基准进行过拟合,以生成最佳的回答。此外,这些仍然是广泛的基准,可能没有覆盖非常特定的用例。最后,另一个缺点是某些基准需要强大的GPU和长时间的计算(超过数小时),这使得快速迭代变得困难。
排行榜
由于基准种类繁多,选择哪个基准最适合你的模型是很难的。每当发布一个模型时,通常会在多个基准上进行评估,以展示其全面表现。
因此,排行榜应运而生,包含多个基准。一个常见的排行榜是Open LLM排行榜,在撰写时,它包括六个基准,其中包括HellaSwag、MMLU、TruthfulQA和GSM8k。通常,在排行榜中名列前茅的模型(假设它们没有对数据进行过拟合)通常被认为是“最佳”模型。然而,由于这些排行榜通常包含公开的基准数据集,因此存在对排行榜过拟合的风险。
4.2 自动评估
评估生成输出的一部分是其文本质量。例如,即使两个模型给出了相同的正确答案,它们得出该答案的方式可能不同。评估时,往往不仅仅关乎最终答案,还关乎答案的构建方式。类似地,尽管两个摘要可能相似,其中一个可能比另一个显著简短,这在好的摘要中通常很重要。
为了评估生成文本的质量(而不仅仅是最终答案的正确性),引入了“LLM作为评估者”方法。基本上,会要求一个单独的LLM来评估待评估的LLM的质量。这个方法的一个有趣变种是配对比较。两个不同的LLM会生成对一个问题的回答,然后由第三个LLM来评判哪一个更好。
因此,这种方法允许对开放性问题进行自动化评估。一个主要的优势是,随着LLM的改进,它们评估输出质量的能力也在提高。换句话说,这种评估方法随着领域的进步而发展。
4.3 人工评估
尽管基准很重要,人工评估通常被认为是黄金标准。即使一个LLM在广泛的基准上得分很高,它仍然可能在特定领域的任务上表现不佳。此外,基准并不能完全捕捉人类偏好,前面讨论的所有方法都只是这些偏好的代理。
人工评估技术的一个很好的例子是聊天机器人竞技场。当你进入这个排行榜时,你会看到两个(匿名的)LLM,你可以与它们互动。你问的任何问题或提示都会被发送到两个模型,并且你将获得它们的输出。然后,你可以选择你更喜欢的输出。这个过程允许社区对模型进行投票,评判它们的表现,且在投票前你并不知道是哪一个模型生成了哪些文本。
截至撰写时,这种方法已经生成了超过800,000个以上的人工投票,这些投票被用来计算排行榜。这些投票用于根据模型的胜率计算相对的技能水平。例如,如果一个排名较低的LLM击败了排名较高的LLM,它的排名会发生显著变化。这个方法类似于国际象棋中的Elo评分系统。
因此,这种方法利用了众包投票,帮助我们了解LLM的质量。然而,它仍然是广泛用户的聚合意见,可能与您的用例无关。
因此,没有一种完美的评估LLM的方法。所有提到的方法和基准提供了一个重要但有限的评估视角。我们的建议是根据预期的使用案例来评估LLM。对于编码任务,HumanEval比GSM8k更为合适。
但最重要的是,我们相信你是最好的评估者。人工评估仍然是黄金标准,因为最终由你决定LLM是否适合你的预期用途。正如本章中的示例所示,我们强烈建议你亲自尝试这些模型,并可能自己设计一些问题。例如,本书的作者是阿拉伯人(Jay Alammar)和荷兰人(Maarten Grootendorst),我们在接触新模型时,常常会用我们自己的母语提出问题。
关于这个话题的最后一条备注是我们所珍视的一个引言:
当一个度量成为目标时,它就不再是一个好的度量。
——古德哈特法则
在LLM的上下文中,当使用特定的基准时,我们往往会为该基准进行优化,而不顾其后果。例如,如果我们纯粹关注优化生成语法正确的句子,模型可能会学会只输出一句话:“这是一个句子。”这句话是语法正确的,但它并没有告诉我们模型的语言理解能力。因此,模型可能在某个特定基准上表现出色,但可能会牺牲其他有用的能力。
五、偏好调优/对齐/RLHF
尽管我们的模型现在可以遵循指令,但我们可以通过最终的训练阶段进一步改进其行为,使其与我们期望其在不同场景中的行为保持一致。例如,当询问“什么是LLM?”时,我们可能更倾向于一个详细的回答,描述LLM的内部结构,而不是简单的回答“它是一个大型语言模型”而没有进一步的解释。我们如何将对一个回答的偏好与LLM的输出对齐呢?
首先,回顾一下,LLM接收一个提示并输出一个生成,如图12-21所示。

我们可以请一个人(偏好评估者)来评估该模型生成的质量。假设他们给它打一个分数,例如图12-22。
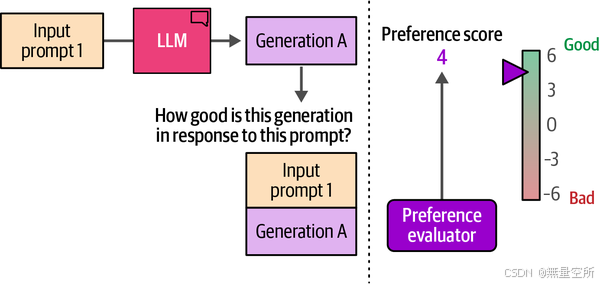
如图12-23所示,偏好调优步骤根据该评分更新模型:
- 如果评分较高,模型会进行调整,以鼓励它生成更多类似的输出。
- 如果评分较低,模型会进行调整,以减少此类生成。
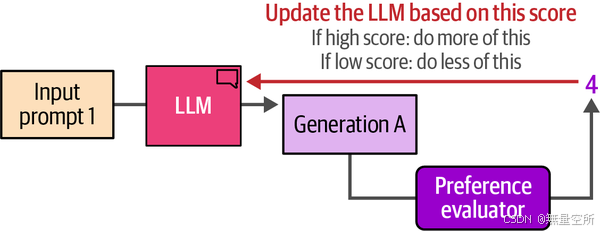
与往常一样,我们需要许多训练样本。那么,我们能否自动化偏好评估呢?是的,我们可以通过训练一个不同的模型,称为奖励模型,来实现。
六、使用奖励模型自动化偏好评估
为了自动化偏好评估,我们需要在偏好调优步骤之前进行一步,即训练一个奖励模型,如图12-24所示。

图12-25显示了为了创建奖励模型,我们复制一个指令调优的模型,并稍微改变它,使其不再生成文本,而是输出一个单一的评分。

6.1 奖励模型的输入和输出
我们期望奖励模型的工作方式是,给它一个提示和一个生成,它输出一个单一的数字,表示该生成在回应该提示时的偏好/质量。如图12-26所示,奖励模型生成这个单一数字。
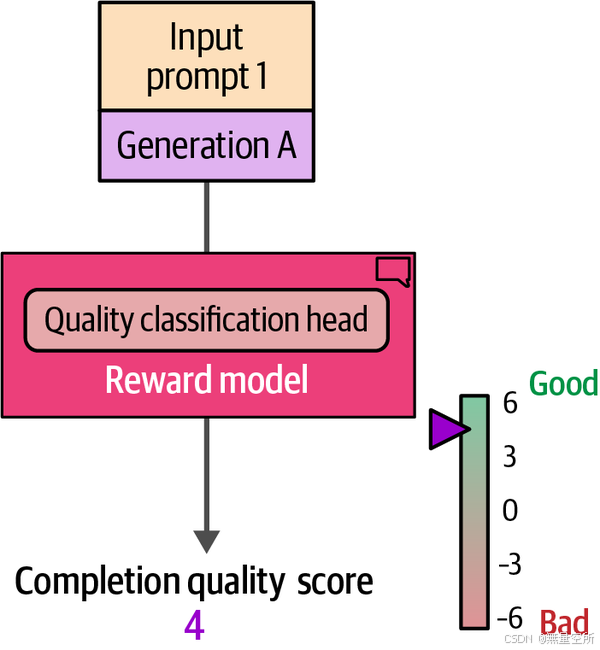
6.2 训练奖励模型
我们不能直接使用奖励模型。它首先需要进行训练,以便能够正确评分生成结果。那么我们来获取一个偏好数据集,让模型从中学习。
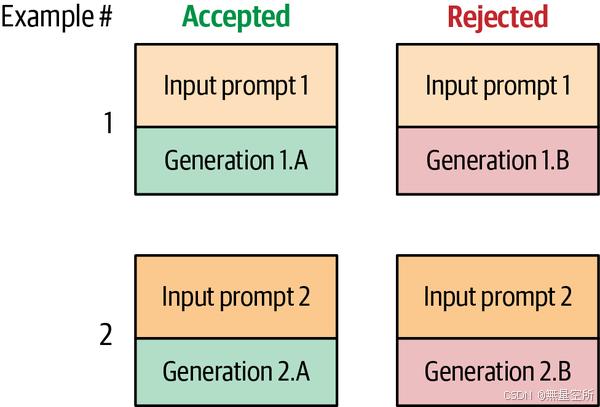
6.2.1 奖励模型训练数据集
一个常见的偏好数据集形式是,每个训练样本包括一个提示,其中有一个接受的生成和一个拒绝的生成。(细微差别:并非总是好与坏的生成;有时两个生成都很好,但一个比另一个更好)。图12-27展示了一个包含两个训练样本的偏好训练集。
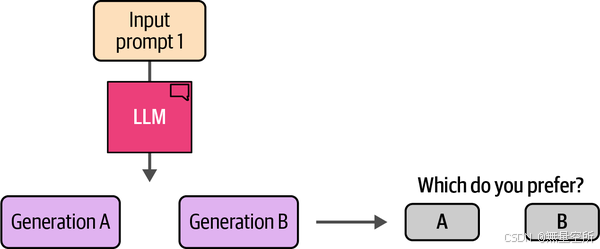
生成偏好数据的一种方法是,向LLM提供一个提示,并让它生成两个不同的结果。如图12-28所示,我们可以请人工标签者选择他们更喜欢哪个。
6.2.2 奖励模型训练步骤
现在我们有了偏好训练数据集,可以进行奖励模型的训练。
一个简单的步骤是,我们使用奖励模型来:
- 评分接受的生成结果
- 评分拒绝的生成结果
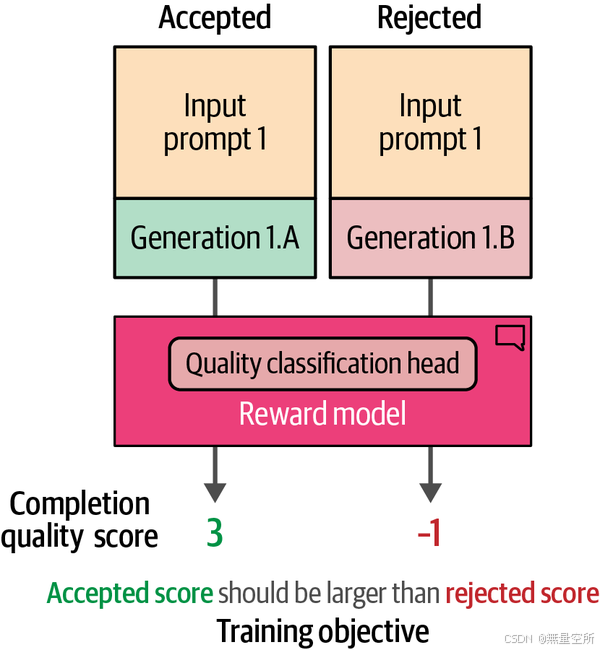
图12-29展示了训练目标:确保接受的生成结果比拒绝的生成结果有更高的分数。
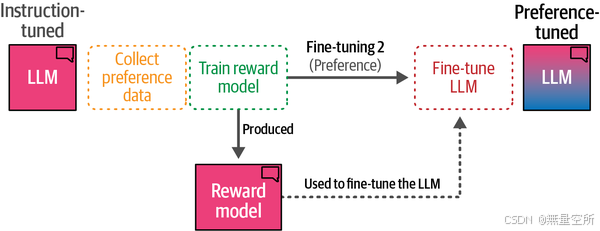
当我们将所有内容整合在一起时,如图12-30所示,我们得到偏好调优的三个阶段:
- 收集偏好数据
- 训练奖励模型
- 使用奖励模型微调LLM(作为偏好评估者)
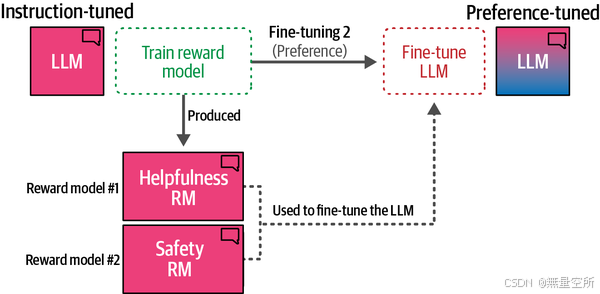
奖励模型是一个很好的想法,可以进一步扩展和开发。例如,Llama 2训练了两个奖励模型:一个评分有用性,另一个评分安全性(图12-31)。
用训练好的奖励模型微调LLM的一个常见方法是使用近端策略优化(PPO)。PPO是一种流行的强化学习技术,通过确保LLM不会偏离预期的奖励太多,来优化指令调优的LLM。它甚至用于训练2022年11月发布的原始ChatGPT。
6.3 训练没有奖励模型
PPO的一个缺点是它是一种复杂的方法,需要训练至少两个模型:奖励模型和LLM,这可能比必要的更为昂贵。
直接偏好优化(DPO)是PPO的替代方案,它省去了基于强化学习的程序。22与其使用奖励模型来评判生成结果的质量,我们让LLM自己来判断。如图12-32所示,我们使用LLM的副本作为参考模型,来比较参考模型与可训练模型之间在接受的生成和拒绝的生成质量上的差异。
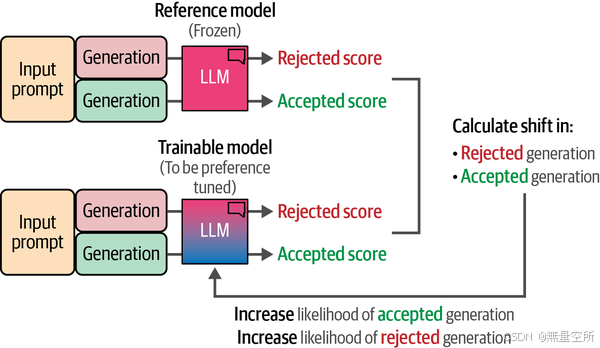
通过在训练过程中计算这种偏移,我们可以通过跟踪参考模型和可训练模型之间的差异来优化接受生成结果的可能性,而减少生成拒绝结果的可能性。
为了计算这种偏移及其相关分数,我们从两个模型中提取拒绝生成结果和接受生成结果的对数概率。如图12-33所示,这一过程是在标记级别进行的,其中这些概率被组合在一起以计算参考模型和可训练模型之间的偏移。接受的生成结果遵循相同的程序。
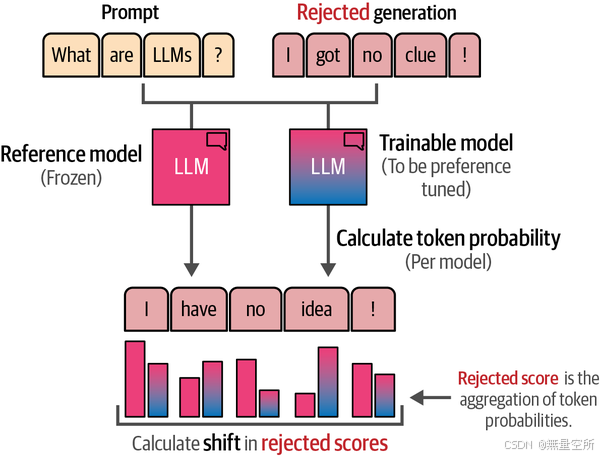
使用这些分数,我们可以优化可训练模型的参数,使其在生成接受的结果时更加自信,而在生成拒绝的结果时更加不自信。与PPO相比,作者发现DPO在训练过程中更加稳定,且更为准确。由于其稳定性,我们将使用DPO作为我们偏好调优的主要方法,来微调我们之前的指令调优模型。
七、使用DPO进行偏好调优
当我们使用Hugging Face的堆栈时,偏好调优与我们之前介绍的指令调优非常相似,但有一些细微的差别。我们仍然会使用TinyLlama,但这次是一个经过指令调优的版本,首先使用全量微调进行训练,然后通过DPO进一步对齐。与最初的指令调优模型相比,这个LLM是用更大的数据集进行训练的。
在本节中,我们将演示如何使用DPO和基于奖励的数据集进一步对齐这个模型。
7.1 模板化对齐数据
我们将使用一个数据集,对于每个提示包含一个接受的生成和一个拒绝的生成。这个数据集部分是由ChatGPT生成的,并附有关于应该接受哪个输出、应该拒绝哪个输出的评分:
from datasets import load_dataset
def format_prompt(example):
"""使用TinyLLama模板格式化提示"""
# 格式化回答
system = "<|system|>\n" + example["system"] + "</s>\n"
prompt = "<|user|>\n" + example["input"] + "</s>\n<|assistant|>\n"
chosen = example["chosen"] + "</s>\n"
rejected = example["rejected"] + "</s>\n"
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
# 对数据集进行格式化并选择相对较短的回答
dpo_dataset = load_dataset(
"argilla/distilabel-intel-orca-dpo-pairs", split="train"
)
dpo_dataset = dpo_dataset.filter(
lambda r:
r["status"] != "tie" and
r["chosen_score"] >= 8 and
not r["in_gsm8k_train"]
)
dpo_dataset = dpo_dataset.map(
format_prompt, remove_columns=dpo_dataset.column_names
)
dpo_dataset
注意,我们进行了额外的过滤,以进一步减少数据集的大小,从原始的13,000个示例减少到大约6,000个示例。
7.2 模型量化
我们加载我们的基础模型,并加载之前创建的LoRA配置。与之前一样,我们对模型进行量化,以减少训练时所需的VRAM:
from peft import AutoPeftModelForCausalLM
from transformers import BitsAndBytesConfig, AutoTokenizer
# 4位量化配置 - QLoRA中的Q
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 使用4位精度加载模型
bnb_4bit_quant_type="nf4", # 量化类型
bnb_4bit_compute_dtype="float16", # 计算数据类型
bnb_4bit_use_double_quant=True, # 应用嵌套量化
)
# 合并LoRA和基础模型
model = AutoPeftModelForCausalLM.from_pretrained(
"TinyLlama-1.1B-qlora",
low_cpu_mem_usage=True,
device_map="auto",
quantization_config=bnb_config,
)
merged_model = model.merge_and_unload()
# 加载LLaMA的tokenizer
model_name = "TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = "<PAD>"
tokenizer.padding_side = "left"
接下来,我们使用之前相同的LoRA配置来进行DPO训练:
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
# 准备LoRA配置
peft_config = LoraConfig(
lora_alpha=32, # LoRA缩放因子
lora_dropout=0.1, # LoRA层的dropout
r=64, # 秩
bias="none",
task_type="CAUSAL_LM",
target_modules= # 目标层
["k_proj", "gate_proj", "v_proj", "up_proj", "q_proj", "o_proj", "down_proj"]
)
# 准备模型进行训练
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
7.3 训练配置
为了简化起见,我们将使用与之前相同的训练参数,但有一个不同之处。我们将训练200步(而不是一个周期,这可能需要长达两小时),用于演示目的。此外,我们添加了warmup_ratio参数,它将在前10%的步骤中将学习率从0逐渐增加到我们设置的learning_rate值。通过在开始时保持较小的学习率(即热身期),我们允许模型在应用较大学习率之前调整数据,从而避免有害的发散:
from trl import DPOConfig
output_dir = "./results"
# 训练参数
training_arguments = DPOConfig(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
learning_rate=1e-5,
lr_scheduler_type="cosine",
max_steps=200,
logging_steps=10,
fp16=True,
gradient_checkpointing=True,
warmup_ratio=0.1
)
7.4 训练
现在我们已经准备好了所有模型和参数,可以开始微调我们的模型:
from trl import DPOTrainer
# 创建DPO训练器
dpo_trainer = DPOTrainer(
model,
args=training_arguments,
train_dataset=dpo_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1,
max_prompt_length=512,
max_length=512,
)
# 使用DPO微调模型
dpo_trainer.train()
# 保存适配器
dpo_trainer.model.save_pretrained("TinyLlama-1.1B-dpo-qlora")
我们创建了第二个适配器。为了合并这两个适配器,我们通过迭代将适配器与基础模型进行合并:
from peft import PeftModel
# 合并LoRA和基础模型
model = AutoPeftModelForCausalLM.from_pretrained(
"TinyLlama-1.1B-qlora",
low_cpu_mem_usage=True,
device_map="auto",
)
sft_model = model.merge_and_unload()
# 合并DPO LoRA和SFT模型
dpo_model = PeftModel.from_pretrained(
sft_model,
"TinyLlama-1.1B-dpo-qlora",
device_map="auto",
)
dpo_model = dpo_model.merge_and_unload()
SFT+DPO的这种组合是一个很好的方式,首先通过指令调优微调模型,以便执行基本的聊天功能,然后通过偏好调优对齐其回答与人类的偏好。然而,它也有一定的代价,因为我们需要执行两个训练循环,并且可能需要在两个过程中调整参数。
自DPO发布以来,已经开发出了一些新的对齐偏好的方法。值得注意的是,赔率比偏好优化(ORPO),这一过程将SFT和DPO结合成一个单一的训练过程。它消除了执行两个独立训练循环的需要,从而简化了训练过程,同时允许使用QLoRA。
八、总结
在本章中,我们探讨了微调预训练LLM的不同步骤。我们通过低秩适应(LoRA)技术利用参数高效微调(PEFT)进行微调。我们解释了如何通过量化扩展LoRA,这是一种减少表示模型和适配器参数时内存约束的技术。
我们探讨的微调过程分为两个步骤。在第一步中,我们使用指令数据对预训练的LLM进行监督微调,通常称为指令调优。这样得到了一个具有聊天行为且能紧密遵循指令的模型。
在第二步中,我们通过在对齐数据上进一步微调模型,数据表示了哪些类型的回答优于其他回答。这个过程被称为偏好调优,它将人类的偏好提炼到先前的指令调优模型中。
总体来说,本章展示了微调预训练LLM的两个主要步骤,并且解释了如何通过这些步骤使输出更准确且更具信息性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









