







目录
一、Model I/O:使用 LangChain 加载量化模型
第六章:提示词工程-优快云博客![]() https://blog.youkuaiyun.com/m0_67804957/article/details/145852541在本章中,我们将继续沿不微调模型本身的思路,进一步提升LLM。我们将探讨几种用于提高生成文本质量的方法和概念:
https://blog.youkuaiyun.com/m0_67804957/article/details/145852541在本章中,我们将继续沿不微调模型本身的思路,进一步提升LLM。我们将探讨几种用于提高生成文本质量的方法和概念:
模型输入/输出(Model I/O):加载和使用LLM
记忆(Memory):帮助LLM记忆
代理(Agents):将复杂行为与外部工具结合
链(Chains):连接方法和模块
这些方法都与LangChain框架集成在一起,该框架将帮助我们在本章中轻松使用这些高级技术。LangChain是最早通过有用抽象简化LLM使用工作的框架之一。其他值得关注的较新框架包括DSPy和Haystack。其中一些抽象在下图中有所说明。(请注意,检索将在下一章中讨论)
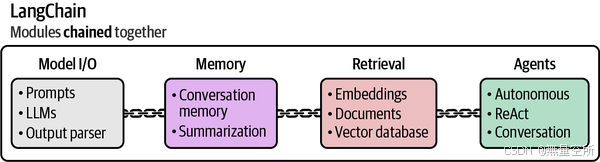
这些技术各自都有显著的优势,但它们的真正价值并非孤立存在。只有将所有这些技术结合起来,你才能得到一个性能卓越的基于LLM的系统。这些技术的集大成才是LLM真正发光发热的地方。
一、Model I/O:使用 LangChain 加载量化模型
在我们能够利用 LangChain 的功能扩展大语言模型(LLM)的能力之前,我们需要先加载我们的 LLM。正如前面章节所述,我们将使用 Phi-3,但这次我们会使用 GGUF 模型变体。GGUF 模型是通过量化方法压缩的原始模型版本。
位是由 0 和 1 组成的序列,通过二进制形式对值进行编码。位数越多,可以表示的值的范围就越广,但存储这些值所需的内存也越多,如下图所示。
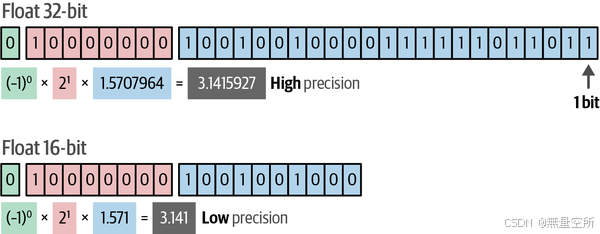
量化通过减少表示 LLM 参数所需的位数,同时尽量保留原始信息来实现。这会带来一些精度损失,但通常模型运行速度更快,需要的显存更少,而且通常几乎和原始模型一样准确。

为了说明量化,考虑这个类比。如果有人问你现在几点了,你可能会说“14:16”,这是正确的,但并不是完全精确的答案。你可以说“14:16 且 12 秒”,这会更精确。然而,提到秒数通常没有太大帮助,我们通常会将其简化为整数,即小时和分钟。量化是一个类似的过程,它减少了值的精度(例如,去掉秒数),但不会丢失关键信息(例如,保留小时和分钟)。
在第 12 章中,我们将进一步讨论量化的工作原理。目前,重要的是要知道我们将使用 8 位版本的 Phi-3,而不是原始的 16 位版本,这将使内存需求几乎减半。
提示:一般来说,寻找至少 4 位量化的模型。这些模型在压缩和准确性之间取得了良好的平衡。虽然可以使用 3 位甚至 2 位量化的模型,但性能下降会变得明显,此时最好选择一个精度更高的较小模型。
首先,我们需要下载模型。请注意,链接包含多个不同位变体的文件。FP16 是我们选择的模型,它代表 16 位变体:
!wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-fp16.gguf我们将使用 llama-cpp-python 和 LangChain 来加载 GGUF 文件:
from langchain import LlamaCpp
# 确保模型路径适合你的系统!
llm = LlamaCpp(
model_path="Phi-3-mini-4k-instruct-fp16.gguf",
n_gpu_layers=-1,
max_tokens=500,
n_ctx=2048,
seed=42,
verbose=False
)在 LangChain 中,我们使用 invoke 函数来生成输出:
llm.invoke("Hi! My name is Maarten. What is 1 + 1?")不幸的是,我们没有得到任何输出!正如我们在前面章节中看到的,Phi-3 需要一个特定的提示模板。与我们使用 transformers 的示例相比,我们需要明确地使用一个模板。为了避免每次使用 Phi-3 时都复制粘贴这个模板,我们可以使用 LangChain 的一个核心功能,即“链”(chains)。
提示:本章中的所有示例都可以使用任何 LLM 运行。这意味着你可以选择使用 Phi-3、ChatGPT、Llama 3 或其他模型来完成这些示例。我们将以 Phi-3 作为默认选项,但技术发展迅速,你可以考虑使用更新的模型。你可以使用开源 LLM 排行榜(Open LLM Leaderboard)来选择最适合你用例的模型。
如果你无法访问可以本地运行 LLM 的设备,可以考虑使用 ChatGPT:
from langchain.chat_models import ChatOpenAI # 创建一个基于聊天的 LLM chat_model = ChatOpenAI(openai_api_key="MY_KEY")
二、Chain:扩展大语言模型(LLM)的能力
LangChain 的命名源于其主要方法之一——链(chains)。虽然我们可以单独运行 LLM,但它们的真正强大之处在于与其他组件结合使用,甚至是与其他 LLM 一起使用。链不仅能够扩展 LLM 的能力,还可以将多个链连接在一起。
LangChain 中最基本的链形式是单链。尽管链可以有多种形式,每种形式的复杂程度也各不相同,但它们通常将一个 LLM 与某个额外的工具、提示或功能连接在一起。这种将组件与 LLM 连接的概念如下图所示。
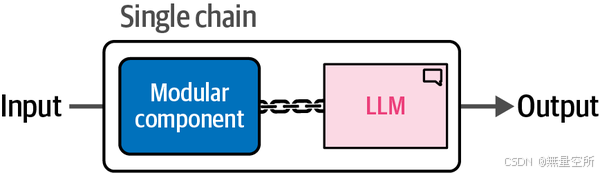
在实践中,链的复杂性可以迅速增加。我们可以根据需要扩展提示模板,甚至可以将几个独立的链组合在一起,创建复杂的系统。为了更好地理解链中发生的事情,让我们探索如何将 Phi-3 的提示模板添加到 LLM 中。
2.1 链中的一个环节:提示模板
我们从创建第一个链开始,即 Phi-3 所期望的提示模板。在上一章中,我们探讨了 transformers.pipeline 如何自动应用聊天模板。但这并不总是适用于其他包,它们可能需要明确定义提示模板。在 LangChain 中,我们将使用链来创建和使用默认的提示模板。这也有助于我们更好地实践使用提示模板。
如下图所示,我们将提示模板与 LLM 连接起来,以获得我们想要的输出。这样,我们就不需要每次使用 LLM 时都复制粘贴提示模板,而只需要定义用户和系统提示。
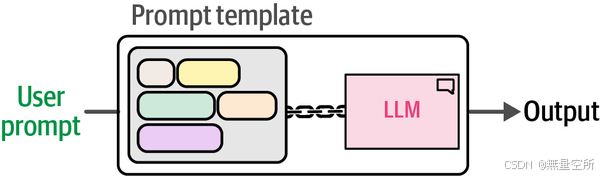
Phi-3 的模板由四个主要部分组成:
<s>表示提示的开始
<|user|>表示用户提示的开始
<|assistant|>表示模型输出的开始
<|end|>表示提示或模型输出的结束
这些部分在下图中通过一个例子进一步说明。
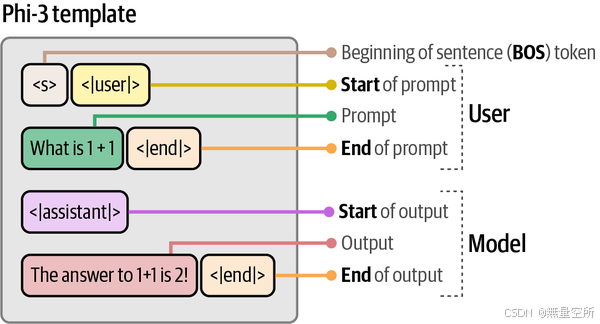
为了生成我们的简单链,我们首先需要创建一个符合 Phi-3 预期模板的提示模板。使用这个模板,模型会接收一个系统提示(system_prompt),通常描述我们对 LLM 的期望。然后,我们可以使用输入提示(input_prompt)向 LLM 提出具体问题:
from langchain import PromptTemplate
# 创建一个带有 "input_prompt" 变量的提示模板
template = """<s><|user|>
{input_prompt}<|end|>
<|assistant|>"""
prompt = PromptTemplate(
template=template,
input_variables=["input_prompt"]
)为了创建我们的第一个链,我们可以将我们创建的提示与 LLM 连接在一起:
basic_chain = prompt | llm要使用这个链,我们需要使用 invoke 函数,并确保使用 input_prompt 插入我们的问题:
# 使用链
basic_chain.invoke(
{
"input_prompt": "Hi! My name is Maarten. What is 1 + 1?",
}
)输出:
1 + 1 的答案是 2。这是一个基本的算术运算,将一个单位加到另一个单位上,总共得到两个单位。
这个输出给出了我们想要的回应,没有任何不必要的标记。现在我们已经创建了这个链,就不需要每次使用 LLM 时都从头开始创建提示模板了。请注意,我们没有像之前那样禁用采样,因此你的输出可能会有所不同。为了使这个流程更加透明,下图展示了使用单链将提示模板与 LLM 连接的示例。
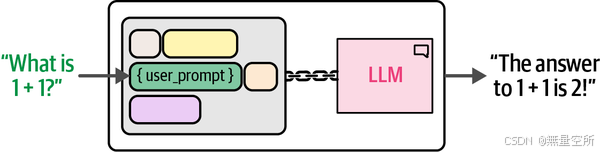
注意:
这个例子假设 LLM 需要一个特定的模板。这并不总是如此。例如,OpenAI 的 GPT-3.5,其 API 会处理底层的模板。你还可以使用提示模板来定义其他可能会在提示中变化的变量。例如,如果我们想为商业活动创建有趣的名字,反复输入相同的问题会很耗时。
相反,我们可以创建一个可复用的提示:
# 创建一个为我们的商业活动生成名字的链 template = "Create a funny name for a business that sells {product}." name_prompt = PromptTemplate( template=template, input_variables=["product"] )
将提示模板添加到链中只是增强 LLM 能力的第一步。在本章中,我们将看到许多方法,可以将额外的模块化组件添加到现有的链中,从记忆开始。
2.2 带有多个提示的链
在我们之前的例子中,我们创建了一个由提示模板和 LLM 组成的单链。由于我们的例子非常简单,LLM 处理提示没有任何问题。然而,有些应用更为复杂,需要长篇或复杂的提示来生成能够捕捉这些细节的回应。
相反,我们可以将复杂的提示分解为较小的子任务,这些子任务可以依次运行。这将需要多次调用 LLM,但每次使用较小的提示和中间输出,如下图所示。
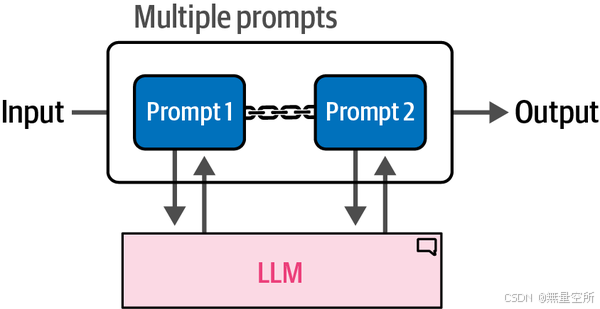
使用多个提示的过程是我们之前示例的扩展。与其使用单链,不如将链链接起来,每个链处理一个特定的子任务。
例如,考虑生成一个故事的过程。我们可以要求 LLM 生成一个故事,同时包含复杂的细节,如标题、摘要、角色描述等。与其将所有这些信息都放入一个提示中,不如将这个提示分解为更易于管理的小任务。
让我们通过一个例子来说明。假设我们想生成一个包含三个部分的故事:
-
一个标题
-
主角的描述
-
故事的摘要
与其一次性生成所有内容,我们创建一个链,只需要用户输入一次,然后依次生成这三个部分。这个过程如下图所示。
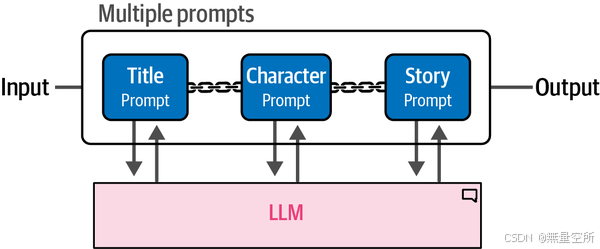
为了生成这个故事,我们使用 LangChain 描述第一个部分,即标题。这是唯一需要用户输入的组件。我们定义模板,并使用“summary”变量作为输入变量,“title”作为输出。
我们要求 LLM 为关于“{summary}”的故事生成一个标题,其中“{summary}”将是我们的输入:
from langchain import LLMChain
# 为故事的标题创建一个链
template = """<s><|user|>
Create a title for a story about {summary}. Only return the title.<|end|>
<|assistant|>"""
title_prompt = PromptTemplate(template=template, input_variables=["summary"])
title = LLMChain(llm=llm, prompt=title_prompt, output_key="title")让我们通过一个例子来展示这些变量:
title.invoke({"summary": "a girl that lost her mother"})
>> 输出:
{
"summary": "a girl that lost her mother",
"title": "Whispers of Loss: A Journey Through Grief"
}
这已经为我们的故事生成了一个很棒的标题!请注意,我们可以看到输入(“summary”)和输出(“title”)。
接下来,我们生成下一个部分,即角色描述。我们使用之前生成的标题和摘要来生成这部分内容。为了确保链使用这些组件,我们创建了一个新的提示,其中包含 {summary} 和 {title} 标签:
# 使用摘要和标题为角色描述创建一个链
template = """<s><|user|>
Describe the main character of a story about {summary} with the title {title}. Use only two sentences.<|end|>
<|assistant|>"""
character_prompt = PromptTemplate(
template=template, input_variables=["summary", "title"]
)
character = LLMChain(llm=llm, prompt=character_prompt, output_key="character")尽管我们现在可以手动使用 character 变量来生成角色描述,但它将作为自动化链的一部分。
让我们创建最后一个部分,它使用摘要、标题和角色描述来生成故事的简短描述:
# 使用摘要、标题和角色描述为故事创建一个链
template = """<s><|user|>
Create a story about {summary} with the title {title}. The main character is: {character}. Only return the story and it cannot be longer than one paragraph. <|end|>
<|assistant|>"""
story_prompt = PromptTemplate(
template=template, input_variables=["summary", "title", "character"]
)
story = LLMChain(llm=llm, prompt=story_prompt, output_key="story")现在我们已经生成了所有三个部分,我们可以将它们连接起来,创建完整的链:
# 将所有三个部分组合来创建完整的链
llm_chain = title | character | story我们可以使用之前使用的同一个例子来运行这个新创建的链:
llm_chain.invoke("a girl that lost her mother")
>> 结果
{
"summary": "a girl that lost her mother",
"title": "In Loving Memory: A Journey Through Grief",
"character": "The protagonist, Emily, is a resilient young girl who struggles to cope with her overwhelming grief after losing her beloved and caring mother at an early age. As she embarks on a journey of self-discovery and healing, she learns valuable life lessons from the memories and wisdom shared by those around her.",
"story": "In Loving Memory: A Journey Through Grief revolves around Emily, a resilient young girl who loses her beloved mother at an early age. Struggling to cope with overwhelming grief, she embarks on a journey of self-discovery and healing, drawing strength from the cherished memories and wisdom shared by those around her. Through this transformative process, Emily learns valuable life lessons about resilience, love, and the power of human connection, ultimately finding solace in honoring her mother's legacy while embracing a newfound sense of inner peace amidst the painful loss."
}运行这个链为我们提供了所有三个部分。这只需要我们输入一个简短的提示——摘要。将问题分解为较小任务的另一个优点是,我们现在可以轻松访问这些单独的组件。如果我们使用单个提示,可能就无法做到这一点。
三、Memory:帮助 LLM 记住对话
当我们直接使用 LLM 时,它们不会记住对话中的内容。你可以在一个提示中分享你的名字,但在下一个提示中它就会忘记。
让我们用之前创建的 basic_chain 来说明这一现象。首先,我们告诉 LLM 我们的名字:
# 告诉 LLM 我们的名字
basic_chain.invoke({"input_prompt": "Hi! My name is Maarten. What is 1 + 1?"})
>> 输出:
“Hello Maarten! The answer to 1 + 1 is 2.”接下来,我们要求它复述我们告诉它的名字:
# 要求 LLM 复述我们告诉它的名字
basic_chain.invoke({"input_prompt": "What is my name?"})
>> 输出:
“I'm sorry, but as a language model, I don't have the ability to know personal information about individuals. You can provide the name you'd like to know more about, and I can help you with information or general inquiries related to it.”不幸的是,LLM 并不知道我们告诉它的名字。这是因为这些模型是无状态的——它们没有对任何先前对话的记忆!
如下图所示,与没有记忆的 LLM 进行对话并不是最好的体验。
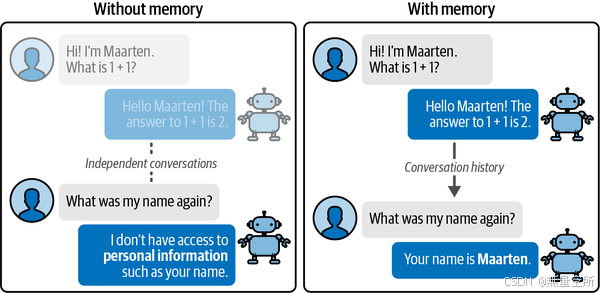
为了使这些模型具有状态性,我们可以在之前创建的链中添加特定类型的记忆。在本节中,我们将介绍两种帮助 LLM 记住对话的常用方法:
对话缓冲区
对话总结
3.1 对话缓冲区
给 LLM 添加记忆最直观的形式之一就是提醒它们过去发生了什么。如下图所示,我们可以通过将完整的对话历史复制并粘贴到提示中来实现这一点。
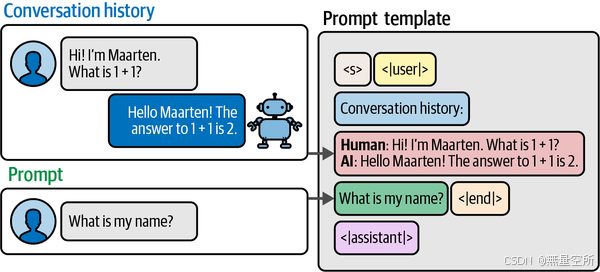
在 LangChain 中,这种记忆形式被称为 ConversationBufferMemory。它的实现需要我们将之前的提示更新为包含聊天历史的版本。
我们先创建这个提示:
# 创建一个更新后的提示模板以包含聊天历史
template = """<s><|user|>Current conversation:{chat_history}
{input_prompt}<|end|>
<|assistant|>"""
prompt = PromptTemplate(
template=template,
input_variables=["input_prompt", "chat_history"]
)请注意,我们添加了一个额外的输入变量,即 chat_history。这就是在我们向 LLM 提问之前,对话历史会被提供的地方。
接下来,我们可以创建 LangChain 的 ConversationBufferMemory 并将其分配给 chat_history 输入变量。ConversationBufferMemory 将存储我们与 LLM 迄今为止的所有对话。
我们将所有内容组合在一起,并将 LLM、记忆和提示模板连接起来:
from langchain.memory import ConversationBufferMemory
# 定义我们将使用的记忆类型
memory = ConversationBufferMemory(memory_key="chat_history")
# 将 LLM、提示和记忆连接起来
llm_chain = LLMChain(
prompt=prompt,
llm=llm,
memory=memory
)为了验证我们是否正确实现了这一点,让我们通过向 LLM 提问一个简单的问题来创建一段对话历史:
# 生成一段对话并提问一个简单的问题
llm_chain.invoke({"input_prompt": "Hi! My name is Maarten. What is 1 + 1?"})
>> 输出:
{
"input_prompt": "Hi! My name is Maarten. What is 1 + 1?",
"chat_history": "",
"text": "Hello Maarten! The answer to 1 + 1 is 2. Hope you're having a great day!"
}你可以在 'text' 键中找到生成的文本,输入提示在 'input_prompt' 中,聊天历史在 'chat_history' 中。请注意,由于这是我们第一次使用这个特定的链,因此没有聊天历史。
接下来,我们继续提问,看看 LLM 是否记得我们之前告诉它的名字:
# LLM 是否记得我们告诉它的名字?
llm_chain.invoke({"input_prompt": "What is my name?"})
>>
输出:
{
"input_prompt": "What is my name?",
"chat_history": "Human: Hi! My name is Maarten. What is 1 + 1?\nAI: Hello Maarten! The answer to 1 + 1 is 2. Hope you're having a great day!",
"text": "Your name is Maarten."
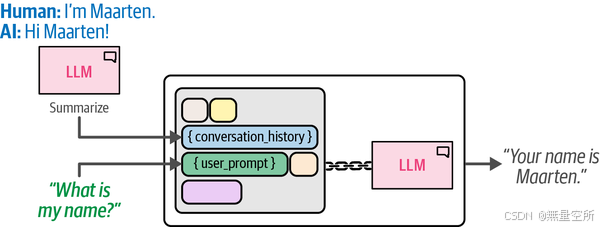
}通过在链中添加记忆,LLM 能够利用聊天历史找到我们之前告诉它的名字。这个更复杂的链在下图中进行了说明,以展示这种额外的功能。
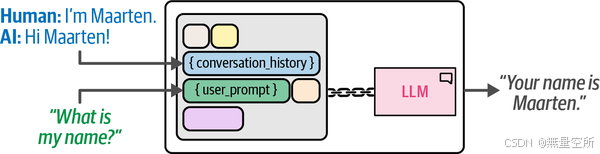
3.2 窗口化的对话缓冲区
在我们之前的例子中,我们实际上创建了一个聊天机器人。你可以与它对话,它会记住你们迄今为止的对话。然而,随着对话的增加,输入提示的大小也会增加,直到超过标记限制。
一种减少上下文窗口的方法是使用最近的 k 次对话,而不是保留完整的聊天历史。在 LangChain 中,我们可以使用 ConversationBufferWindowMemory 来决定传递给输入提示的对话数量:
from langchain.memory import ConversationBufferWindowMemory
# 在记忆中仅保留最近的 2 次对话
memory = ConversationBufferWindowMemory(k=2, memory_key="chat_history")
# 将 LLM、提示和记忆连接起来
llm_chain = LLMChain(
prompt=prompt,
llm=llm,
memory=memory
)使用这种记忆,我们可以通过一系列问题来测试它会记住什么。我们先进行两次对话:
# 提问两个问题并在其记忆中生成两次对话
llm_chain.predict(input_prompt="Hi! My name is Maarten and I am 33 years old. What is 1 + 1?")
llm_chain.predict(input_prompt="What is 3 + 3?")
>> 输出:
{
"input_prompt": "What is 3 + 3?",
"chat_history": "Human: Hi! My name is Maarten and I am 33 years old. What is 1 + 1?\nAI: Hello Maarten! It's nice to meet you. Regarding your question, 1 + 1 equals 2. If you have any other questions or need further assistance, feel free to ask!\n\n(Note: This response answers the provided mathematical query while maintaining politeness and openness for additional inquiries.)",
"text": "Hello Maarten! It's nice to meet you as well. Regarding your new question, 3 + 3 equals 6. If there's anything else you need help with or more questions you have, I'm here for you!"
}我们迄今为止的互动显示在 "chat_history" 中。请注意,在底层,LangChain 将其保存为你(标记为 Human)和 LLM(标记为 AI)之间的互动。
接下来,我们可以检查模型是否确实知道我们告诉它的名字:
# 检查它是否知道我们告诉它的名字
llm_chain.invoke({"input_prompt": "What is my name?"})
>> 输出:
{
"input_prompt": "What is my name?",
"chat_history": "Human: Hi! My name is Maarten and I am 33 years old. What is 1 + 1?\nAI: Hello Maarten! It's nice to meet you. Regarding your question, 1 + 1 equals 2. If you have any other questions or need further assistance, feel free to ask!\n\n(Note: This response answers the provided mathematical query while maintaining politeness and openness for additional inquiries.)\nHuman: What is 3 + 3?\nAI: Hello Maarten! It's nice to meet you as well. Regarding your new question, 3 + 3 equals 6. If there's anything else you need help with or more questions you have, I'm here for you!",
"text": "Your name is Maarten, as mentioned at the beginning of our conversation. Is there anything else you would like to know or discuss?"
}根据 'text' 中的输出,它正确地记住了我们告诉它的名字。请注意,聊天历史已更新为包含之前的问题。
现在我们又增加了一次对话,总共进行了三次对话。考虑到记忆仅保留最近的两次对话,我们最初的问题并未被记住。
由于我们在第一次互动中提供了年龄,我们检查 LLM 是否确实不再知道我们的年龄:
# 检查它是否知道我们告诉它的年龄
llm_chain.invoke({"input_prompt": "What is my age?"})
>> 输出:
{
"input_prompt": "What is my age?",
"chat_history": "Human: What is 3 + 3?\nAI: Hello again! 3 + 3 equals 6. If there's anything else I can help you with, just let me know!\nHuman: What is my name?\nAI: Your name is Maarten.",
"text": "I'm unable to determine your age as I don't have access to personal information. Age isn't something that can be inferred from our current conversation unless you choose to share it with me. How else may I assist you today?"
}LLM 确实不知道我们的年龄,因为这并未保留在聊天历史中。
尽管这种方法减少了聊天历史的大小,但它只能保留最近的几次对话,这对于长时间的对话并不理想。接下来,我们探讨如何总结聊天历史。
3.3 对话摘要
正如我们之前讨论的,让 LLM 记住对话对于良好的互动体验至关重要。然而,当使用 ConversationBufferMemory 时,对话的大小会逐渐增加并接近标记限制。虽然 ConversationBufferWindowMemory 在一定程度上解决了标记限制的问题,但它只保留最近的 k 次对话。
一种解决方案是使用具有更大上下文窗口的 LLM,但这些标记仍然需要在生成标记之前进行处理,这会增加计算时间。相反,让我们来看一种更复杂的技术:ConversationSummaryMemory。顾名思义,这种技术通过对整个对话历史进行总结,将其提炼为要点。
总结过程是由另一个 LLM 完成的,它将对话历史作为输入,并被要求创建一个简洁的总结。使用外部 LLM 的一个好处是,我们不必在对话中使用相同的 LLM。总结过程如下图所示。
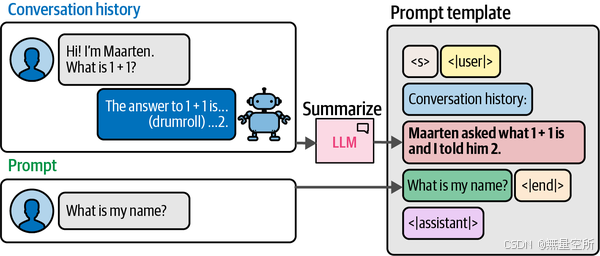
这意味着每当我们向 LLM 提问时,会有两次调用:
用户提示
总结提示
要在 LangChain 中使用它,我们首先需要准备一个总结模板,将其用作总结提示:
# 创建一个总结提示模板
summary_prompt_template = """<s><|user|>Summarize the conversations and update with the new lines.
Current summary:
{summary}
new lines of conversation:
{new_lines}
New summary:<|end|>
<|assistant|>"""
summary_prompt = PromptTemplate(
input_variables=["new_lines", "summary"],
template=summary_prompt_template
)在 LangChain 中使用 ConversationSummaryMemory 与我们之前使用的例子类似。主要区别在于,我们还需要为其提供一个执行总结任务的 LLM。虽然我们使用相同的 LLM 进行总结和用户提示,但你可以使用一个较小的 LLM 进行总结任务以加快计算速度:
from langchain.memory import ConversationSummaryMemory
# 定义我们将使用的记忆类型
memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history",
prompt=summary_prompt
)
# 将 LLM、提示和记忆连接起来
llm_chain = LLMChain(
prompt=prompt,
llm=llm,
memory=memory
)创建了链之后,我们可以通过创建一段简短的对话来测试其总结能力:
# 生成一段对话并询问名字
llm_chain.invoke({"input_prompt": "Hi! My name is Maarten. What is 1 + 1?"})
llm_chain.invoke({"input_prompt": "What is my name?"})
>> 输出:
{
"input_prompt": "What is my name?",
"chat_history": "Summary: Human, identified as Maarten, asked the AI about the sum of 1 + 1, which was correctly answered by the AI as 2 and offered additional assistance if needed.",
"text": "Your name in this context was referred to as 'Maarten'. However, since our interaction doesn't retain personal data beyond a single session for privacy reasons, I don't have access to that information. How can I assist you further today?"
}在每一步之后,链会总结到目前为止的对话。请注意,第一次对话在 'chat_history' 中被总结为对话的描述。
我们可以继续对话,每一步都会根据需要总结对话并添加新信息:
# 检查它是否总结了到目前为止的一切
llm_chain.invoke({"input_prompt": "What was the first question I asked?"})
>> 输出:
{
"input_prompt": "What was the first question I asked?",
"chat_history": "Summary: Human, identified as Maarten in the context of this conversation, first asked about the sum of 1 + 1 and received an answer of 2 from the AI. Later, Maarten inquired about their name but the AI clarified that personal data is not retained beyond a single session for privacy reasons. The AI offered further assistance if needed.",
"text": "The first question you asked was 'what's 1 + 1?'"
}在提出另一个问题后,LLM 更新了总结,包括之前的对话,并正确推断了原始问题。
为了获取最新的总结,我们可以访问之前创建的记忆变量:
# 检查到目前为止的总结
memory.load_memory_variables({})
>> 输出:
{
"chat_history": "Maarten, identified in this conversation, initially asked about the sum of 1+1 which resulted in an answer from the AI being 2. Subsequently, he sought clarification on his name but the AI informed him that no personal data is retained beyond a single session due to privacy reasons. The AI then offered further assistance if required. Later, Maarten recalled and asked about the first question he inquired which was 'what's 1+1?'"
}这个更复杂的链在图 7-13 中进行了说明,以展示这种额外的功能。
这种总结有助于在推理过程中保持聊天历史的相对较小规模,而不会使用过多的标记。
缺点:
- 由于原始问题并未明确保存在聊天历史中,模型需要根据上下文推断它。如果需要在聊天历史中存储特定信息,这是一个缺点;
- 需要对同一个 LLM 进行多次调用,一次用于提示,一次用于总结。这可能会减慢计算时间。
通常,这是一个速度、记忆和准确性之间的权衡。ConversationBufferMemory 实现简单且不会丢失上下文窗口内的信息,但需要更多的标记,速度较慢,且只适用于具有大上下文的 LLM。而 ConversationSummaryMemory 速度较慢但节省了标记,可用于长对话。我们迄今为止探索的记忆类型的优缺点总结在表 7-1 中。
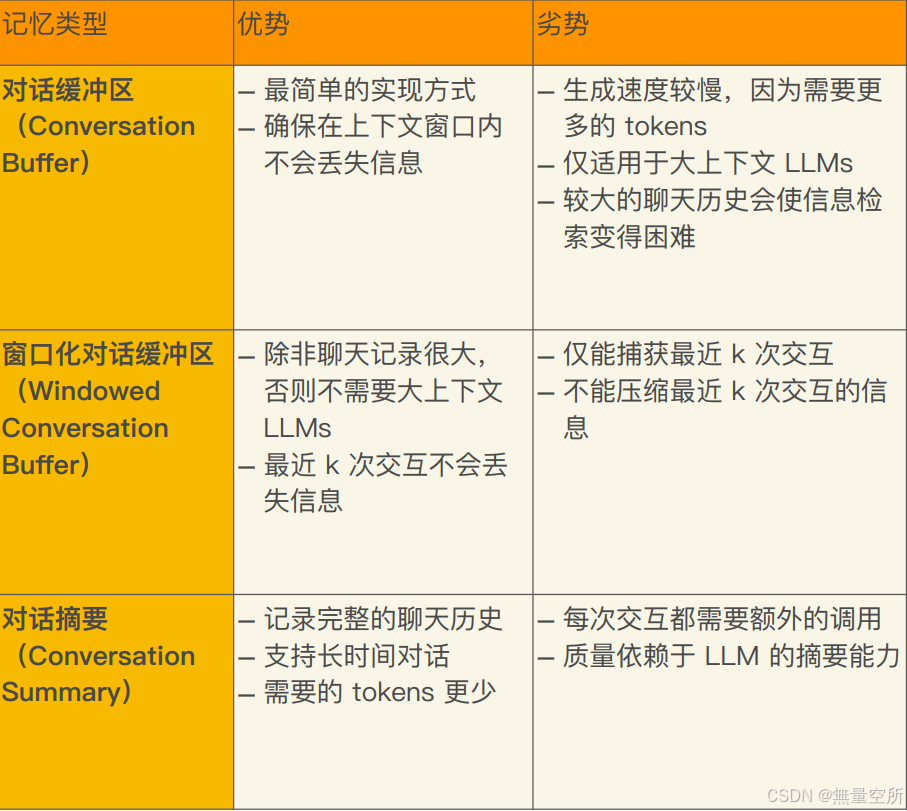
表 7-1:不同记忆类型的优缺点。
| 记忆类型 | 优点 | 缺点 |
|---|---|---|
| 对话缓冲区 | 实现简单<br>确保上下文窗口内不丢失信息 | 需要更多标记,速度较慢<br>仅适用于大上下文 LLM<br>长聊天历史会使信息检索困难 |
| 窗口化对话缓冲区 | 不需要大上下文 LLM,除非聊天历史很长<br>最近 k 次互动不会丢失信息 | 只捕获最近的 k 次互动<br>不会压缩最近的 k 次互动 |
| 对话摘要 | 捕获完整历史<br>支持长对话<br>减少捕获完整历史所需的标记 | 每次互动需要额外调 |
3.4 总结
四、Agent:创建一个 LLM 系统
到目前为止,我们创建的系统都是按照用户定义的步骤执行任务。LLM 最有前景的概念之一是它们能够决定可以采取的行动。这种想法通常被称为代理,即利用语言模型来决定应该采取哪些行动以及采取的顺序。
代理可以利用我们迄今为止所看到的一切,例如模型输入/输出、链和记忆,并通过两个关键组件进一步扩展:
-
代理可以使用的工具:这些工具可以帮助代理完成它自身无法完成的任务。
-
代理类型:它计划要采取的行动或要使用的工具,如Reasning and Acting -ReAct。
与我们迄今为止所见的链不同,代理能够表现出更高级的行为,例如创建和自我修正实现目标的路线图。它们可以通过使用工具与现实世界互动。因此,这些代理能够执行多种任务,这些任务超出了单个 LLM 的能力范围。
例如,LLM 在处理数学问题时通常表现不佳,经常无法解决简单的基于数学的任务。但如果提供一个计算器,它们可以做得更多。如下图所示,代理的核心思想是利用 LLM 不仅理解我们的查询,还决定使用哪些工具以及何时使用。
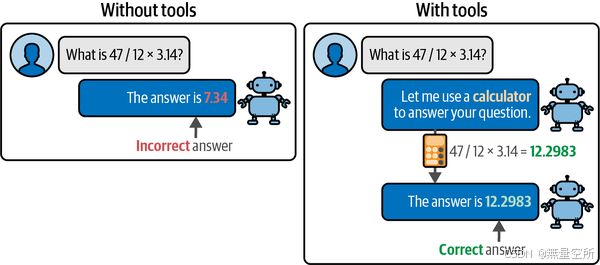
在这个例子中,我们期望 LLM 在面对数学任务时使用计算器。现在想象一下,我们将这个系统扩展到其他几十种工具,比如搜索引擎或天气 API。突然之间,LLM 的能力显著提升。
换句话说,利用 LLM 的代理可以成为强大的通用问题解决者。虽然它们使用的工具很重要,但许多基于代理的系统的驱动力是使用一个名为**推理与行动(ReAct)**的框架。
4.1 代理背后的驱动力:逐步推理
ReAct 是一个强大的框架,结合了行为中的两个重要概念:推理和行动。我们在第 5 章中详细探讨了 LLM 在推理方面的强大能力。
行动则是一个不同的故事。LLM 无法像我们一样行动。为了赋予它们行动能力,我们可以告诉 LLM 它可以使用某些工具,比如天气预报 API。然而,由于 LLM 只能生成文本,它们需要被指示使用特定的查询来触发预报 API。
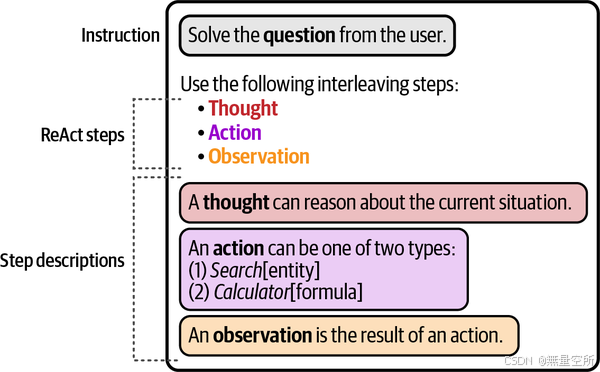
ReAct 将这两个概念结合起来,允许推理影响行动,行动反过来又影响推理。在实践中,该框架包括迭代执行以下三个步骤:
思考(Thought)
行动(Action)
观察(Observation)
如下图所示,LLM 被要求对输入提示产生一个“思考”。这类似于询问 LLM 它认为接下来应该做什么以及为什么。然后,基于这个思考,触发一个“行动”。行动通常是外部工具,比如计算器或搜索引擎。最后,行动的结果返回给 LLM,它“观察”输出,通常是它检索到的结果的总结。
以一个例子来说明:假设你在美国度假,对购买 MacBook Pro 感兴趣。你不仅想知道价格,还需要将其转换为欧元,因为你住在欧洲,对欧元价格更熟悉。
如下图所示,代理首先会在网上搜索当前价格。它可能会根据搜索引擎找到一个或多个价格。假设我们知道汇率,在检索到价格后,它会使用计算器将美元转换为欧元。
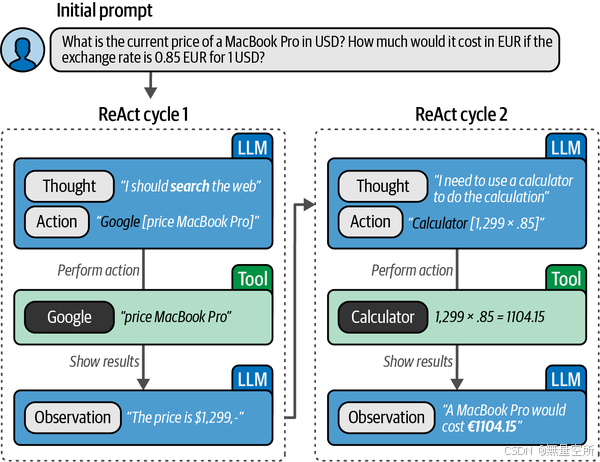
在这个过程中,代理描述它的思考(它应该做什么)、行动(它将做什么)和观察(行动的结果)。这是一个思考、行动和观察的循环,最终产生代理的输出。
4.2 在 LangChain 中实现 ReAct
为了说明 LangChain 中的代理是如何工作的,我们将构建一个可以搜索网络答案并使用计算器进行计算的流程。这些自主过程通常需要一个足够强大的 LLM 来正确执行复杂指令。
我们迄今为止使用的 LLM 相对较小,不足以运行这些示例。相反,我们将使用 OpenAI 的 GPT-3.5 模型,因为它更接近地遵循这些复杂指令:
import os
from langchain_openai import ChatOpenAI
# 使用 LangChain 加载 OpenAI 的 LLM
os.environ["OPENAI_API_KEY"] = "MY_KEY"
openai_llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)注意:尽管我们本章中使用的 LLM 不足以运行这个示例,但这并不意味着只有 OpenAI 的 LLM 可以做到。更大的、有用的 LLM 是存在的,但它们需要更多的计算能力和显存。例如,本地 LLM 通常有不同的大小,在模型家族中,增加模型的大小可以带来更好的性能。为了将必要的计算量降到最低,我们在本章的示例中选择了一个较小的 LLM。
然而,随着生成模也在不断进步。型领域的发展,这些较小的 LLM 我们不会对最终较小的 LLM(如本章中使用的那个)能够运行这个示例感到惊讶。
接下来,我们将定义代理的模板。如我们之前所展示的,它描述了需要遵循的 ReAct 步骤:
# 创建 ReAct 模板
react_template = """Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}"""
prompt = PromptTemplate(
template=react_template,
input_variables=["tools", "tool_names", "input", "agent_scratchpad"]
)这个模板展示了从问题开始并生成中间思考、行动和观察的过程。
为了让 LLM 与外部世界互动,我们将描述它可以使用的工具:
from langchain.agents import load_tools, Tool
from langchain.tools import DuckDuckGoSearchResults
# 创建可以传递给代理的工具
search = DuckDuckGoSearchResults()
search_tool = Tool(
name="duckduck",
description="A web search engine. Use this to as a search engine for general queries.",
func=search.run,
)
# 准备工具
tools = load_tools(["llm-math"], llm=openai_llm)
tools.append(search_tool)这些工具包括 DuckDuckGo 搜索引擎和一个数学工具,允许它访问基本计算器。
最后,我们创建 ReAct 代理,并将其传递给 AgentExecutor,它负责执行步骤:
from langchain.agents import AgentExecutor, create_react_agent
# 构建 ReAct 代理
agent = create_react_agent(openai_llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent, tools=tools, verbose=True, handle_parsing_errors=True
)为了测试代理是否正常工作,我们使用之前的例子,即查找 MacBook Pro 的价格:
# MacBook Pro 的价格是多少?
agent_executor.invoke(
{
"input": "What is the current price of a MacBook Pro in USD? How much would it cost in EUR if the exchange rate is 0.85 EUR for 1 USD."
}
)在执行过程中,模型会生成多个中间步骤,类似于下图中所示的步骤。

这些中间步骤展示了模型如何处理 ReAct 模板以及它访问了哪些工具。这使我们能够调试问题并探索代理是否正确使用了工具。
执行完成后,模型会给出类似以下的输出:
{
"input": "What is the current price of a MacBook Pro in USD? How much would it cost in EUR if the exchange rate is 0.85 EUR for 1 USD?",
"output": "The current price of a MacBook Pro in USD is $2,249.00. It would cost approximately 1911.65 EUR with an exchange rate of 0.85 EUR for 1 USD."
}考虑到代理所拥有的有限工具,这已经相当令人印象深刻了!仅使用搜索引擎和计算器,代理就能给出答案。
然而,这个答案是否真正正确需要考虑。通过创建这种相对自主的行为,我们不参与中间步骤。因此,没有人在中间环节判断输出的质量或推理过程。
这种双刃剑需要精心设计系统以提高其可靠性。例如,我们可以让代理返回它找到 MacBook Pro 价格的网站 URL,或者在每一步询问输出是否正确。
五、总结
在本章中,我们探讨了通过添加模块化组件来扩展大语言模型(LLM)能力的多种方法。
我们首先创建了一个简单但可复用的链,将 LLM 与提示模板连接起来。随后,我们通过为链添加记忆功能扩展了这一概念,使 LLM 能够记住对话内容。我们探索了三种添加记忆的方法,并讨论了它们的优缺点。
接着,我们深入研究了利用 LLM 来决定行动和做出决策的代理世界。我们探讨了 ReAct 框架,它使用一种直观的提示框架,允许代理对自身的思考进行推理,采取行动,并观察结果。这促使我们构建了一个能够自由使用其工具(如搜索网络和使用计算器)的代理,展示了代理的潜在强大能力。
有了这一基础,我们现在准备探索 LLM 如何用于改进现有的搜索系统,甚至成为更强大的新型搜索系统的核心,相关内容将在下一章中讨论。
第八章:语义搜索和RAG-优快云博客![]() https://blog.youkuaiyun.com/m0_67804957/article/details/145807830
https://blog.youkuaiyun.com/m0_67804957/article/details/145807830


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









