






Trados对于翻译记忆库,只能支持sdltm格式的,但是这种格式是Trados自有的,我们无法去获得这个格式内部到底长什么样,用vscode打开后是乱码形式,不管用哪种编码打开都是一样的乱码,所以想要往里面添加文件,只能是将excel转成tmx文件
添加tmx入库的步骤
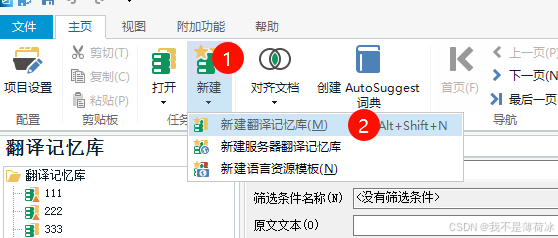
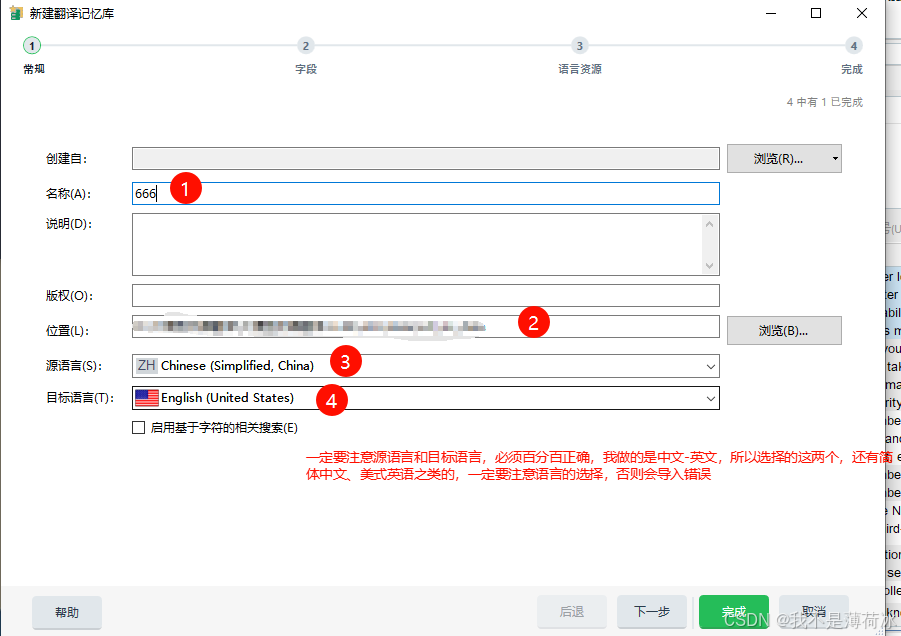

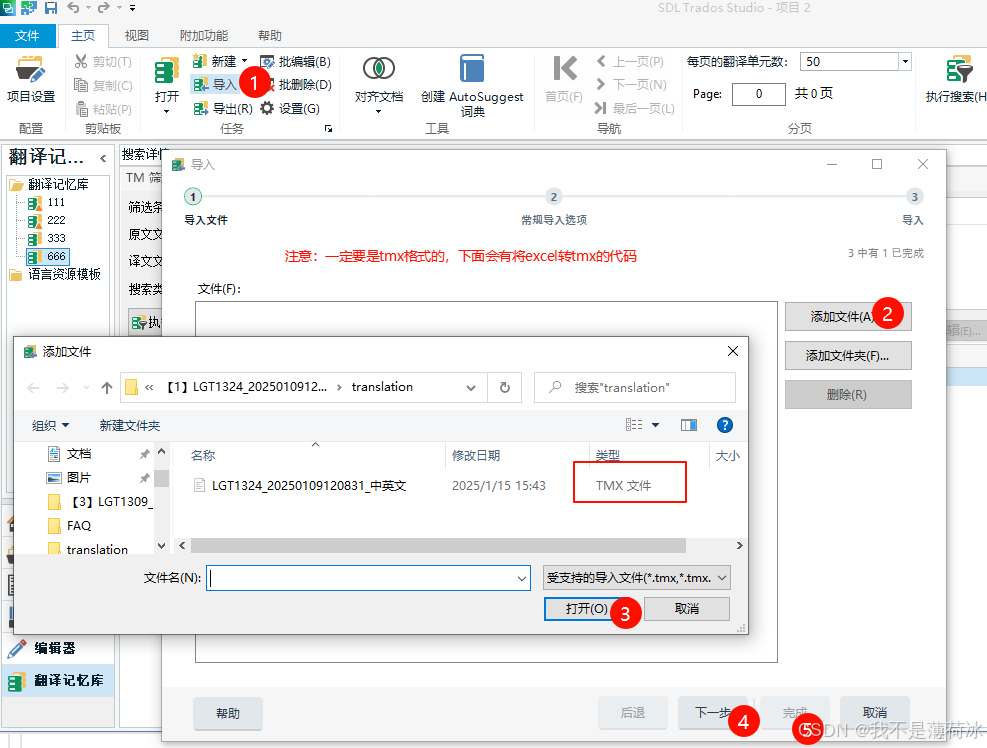
至此我们实现了如何把tmx导入到Trados里
将excel文件转tmx文件代码
import pandas as pd
import xml.etree.ElementTree as ET
def excel_to_tmx(your_file,output):
# 读取 Excel 文件
df = pd.read_excel(your_file) # 替换为你的 Excel 文件名
print('保存tmx文件:',output)
# 创建 TMX 文件
with open(output, 'w', encoding='utf-8') as f:
f.write("<?xml version='1.0' encoding='UTF-8'?>\n")
f.write("<tmx version=\"1.4\">\n")
f.write(" <header creationtool=\"SDL Language Platform\" creationtoolversion=\"8.0\" o-tmf=\"SDL TM8 Format\" datatype=\"xml\" segtype=\"sentence\" adminlang=\"en-US\" srclang=\"en-US\">\n")
f.write(" <prop type=\"x-Recognizers\">RecognizeAll</prop>\n")
f.write(" <prop type=\"x-TMName\">tm</prop>\n")
f.write(" <prop type=\"x-TokenizerFlags\">DefaultFlags</prop>\n")
f.write(" <prop type=\"x-WordCountFlags\">DefaultFlags</prop>\n")
f.write(" </header>\n")
f.write(" <body>\n")
for index, row in df.iterrows():
f.write(" <tu>\n")
f.write(" <tuv xml:lang=\"ZH-CN\">\n")
f.write(f" <seg>\"{row['zh-cn'].replace('<', '<').replace('>', '>')}\"</seg>\n")
f.write(" </tuv>\n")
f.write(" <tuv xml:lang=\"en-US\">\n")
f.write(f" <seg>{row['en-us'].replace('<', '<').replace('>', '>')}</seg>\n")
f.write(" </tuv>\n")
f.write(" </tu>\n")
f.write(" </body>\n")
f.write("</tmx>\n")
if __name__=='__main__':
# 使用示例
excel_to_tmx(r'中英文.xlsx',
r'中英文.tmx')
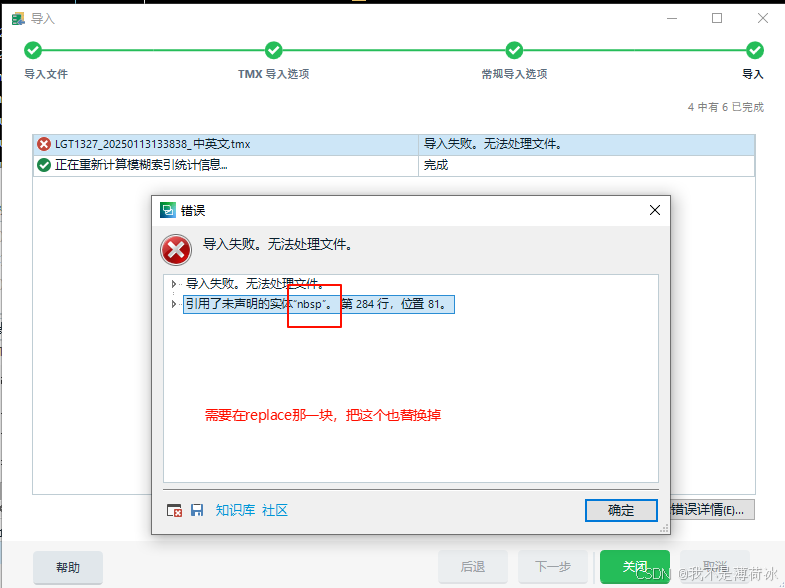
至于为什么要进行replace操作,简直是血与泪的教训,如果你添加的文本中出现了标签,则会导致添加失败
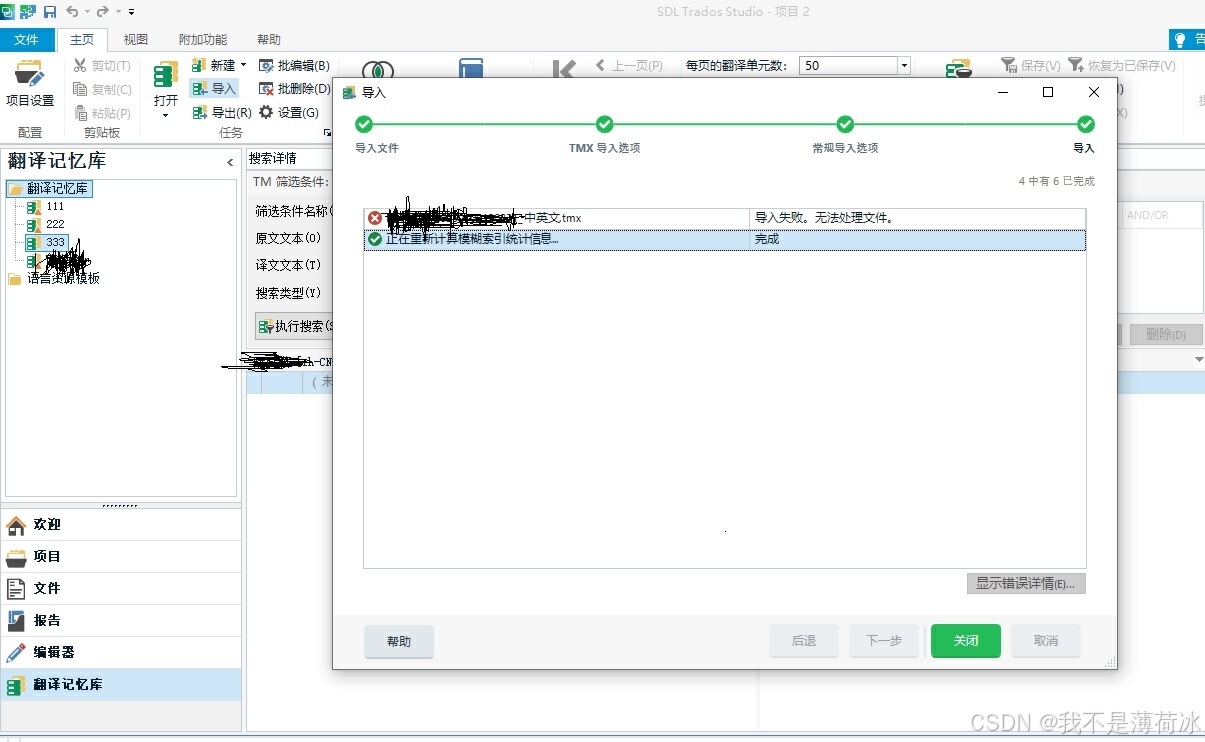 比如:3、公示信息链接:<span><a id="xxx" href="xxx">,就会导入失败,所以需要对这种文本进行一下处理,现在可以实现自动导入了
比如:3、公示信息链接:<span><a id="xxx" href="xxx">,就会导入失败,所以需要对这种文本进行一下处理,现在可以实现自动导入了
后续问题订正:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









