







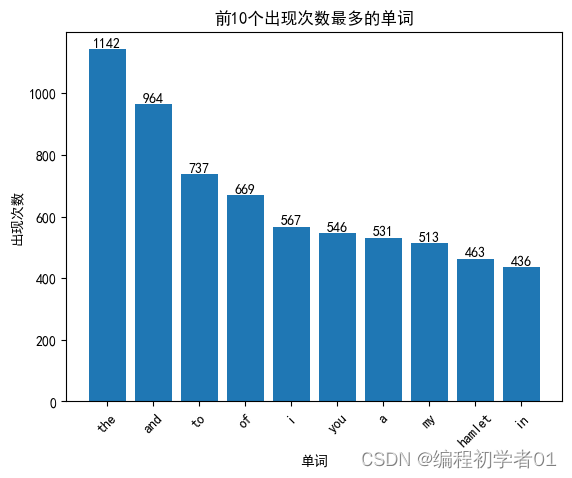
 本文展示了如何使用Python中的re模块和matplotlib库对《哈姆雷特》文本进行单词频率分析,提取并可视化了最常见的10个单词及其出现次数。
本文展示了如何使用Python中的re模块和matplotlib库对《哈姆雷特》文本进行单词频率分析,提取并可视化了最常见的10个单词及其出现次数。
import re
import matplotlib.pyplot as plt
from collections import Counter
word_counts = {}
with open('E:\自然语言处理\Hamlet(2).txt') as f:
for line in f:
words = line.strip().lower().split()
for word in words:
word = re.sub(r'[^a-zA-Z]+','',word)
if word in word_counts:
word_counts[word] += 1
else:
word_counts[word] = 1
top_words = Counter(word_counts).most_common(10)
top_words_list = [word[0] for word in top_words]
top_words_counts = [word[1] for word in top_words]
plt.bar(top_words_list, top_words_counts)
plt.xlabel('单词')
plt.ylabel('出现次数')
plt.title('前10个出现次数最多的单词')
plt.xticks(rotation=45)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定使用中文字体
for i, count in enumerate(top_words_counts):
plt.text(i, count, str(count), ha='center', va='bottom')
plt.show()
print(word_counts)我们假设我们获取了一个哈姆雷特文本,要进行每个单词的统计



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











