








🏠关于专栏:专栏用于记录LeetCode中Hot100专题的所有题目
🎯每日努力一点点,技术变化看得见
题目转载
题目描述
🔒link->题目跳转链接
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
题目示例
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
题目提示
●
1
1
1 <= strs.length <=
1
0
4
10^4
104
●
0
0
0 <= strs[i].length <=
100
100
100
● strs[i] 仅包含小写字母
解题思路及代码
整理题意
题目中给出了异位字母词的概念,其指的是,如果两个单词的26个英文字母出现的次数相同,但位于的位置不同,则称为异位字母词。如eat和ate就是异位字母词,它们都有1个a、1个e、1个t;如queue和queen就不是异位字母词,因为他们的u和n字母的数量不同。
方法1-排序
从异位字母词的概念我们可以知道,如果对两个互为异位字母词的字母串进行排序,则它们都会得到相同的字符串。如eat和ate排序后均为aet。那么我们可以使用哈希表进行存储,键域(key)保存异位字母词排序后的字符串,值域(value)保存一个vector<string>类型,用于保存所有排序后为键(key)的字符串。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> m;
for(auto str : strs)
{
string tmp = str;
sort(tmp.begin(), tmp.end());
m[tmp].push_back(str);
}
vector<vector<string>> ret;
for(auto member : m)
{
ret.push_back(member.second);
}
return ret;
}
};
方法2-计数
既然互为异位字母词的字符串的各个字母数量相等,我们可不可以将上面哈希表中的键(key)改为26个字母的计数数组呢?在C++中,unordered_map无法直接将数组作为键(key),需要将数组转换为unordered_map支持的类型,如string、int等;或借助于设置哈希散列函数,实现数组到哈希桶的直接映射。
自主定义键(key)
以纯数字字符串为键
从题目的提示可知,每个字母最多出现10000次,如果使用数字字符表示,需要5个;而26个字母,每个用5个数字字符表示,即需要
26
×
5
26×5
26×5,即130个字符表示,由这个字符串作为哈希表的键(key)。

class Solution {
public:
string arrToSting(array<int, 26>& arr)
{
string ret;
for(auto elem : arr)
{
string tmp;
while(elem) {
tmp.insert(tmp.begin(), '0' + elem % 10);
elem /= 10;
}
while(tmp.size() < 5) {
tmp.insert(tmp.begin(), '0');
}
ret.append(tmp);
}
return ret;
}
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> m;
for(auto& str : strs)
{
array<int, 26> count{0};
for(auto e : str) ++count[e - 'a'];
m[arrToSting(count)].push_back(str);
}
vector<vector<string>> ret;
for(auto elem : m)
{
ret.push_back(elem.second);
}
return ret;
}
};
以数字、字母交替字符串为键
除了上面的方式,我们可以使用“字母+字母数量”组合而成的字符串作为键(key),如下图所示。

class Solution {
public:
string arrToSting(array<int, 26>& arr)
{
string ret;
for(int i = 0; i < arr.size(); ++i)
{
ret.push_back('a' + i);
while(arr[i]) {
ret.push_back('0' + arr[i] % 10);
arr[i] /= 10;
}
}
return ret;
}
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> m;
for(auto& str : strs)
{
array<int, 26> count{0};
for(auto e : str) ++count[e - 'a'];
m[arrToSting(count)].push_back(str);
}
vector<vector<string>> ret;
for(auto elem : m)
{
ret.push_back(elem.second);
}
return ret;
}
};
ps:上述代码中,若需要某个字母出现次数为0,则生成的关键字中只包含字母不包含数字
自定义哈希函数

Attention:要使用该方法,需要对哈希散列函数、哈希表映射原理、仿函数、lambda表达式有所了解!
在介绍该方法前,先对一些C++中的操作进行介绍并给出相关示例。首先介绍std::hash,该哈希函数对象位于functional库中,它可用于为不同的类型生成哈希值,下方是关于std::hash的示例:
#include <iostream>
#include <functional>
int main()
{
int num = 666;
std::hash<int> hasher;
size_t hashValue = hasher(num);
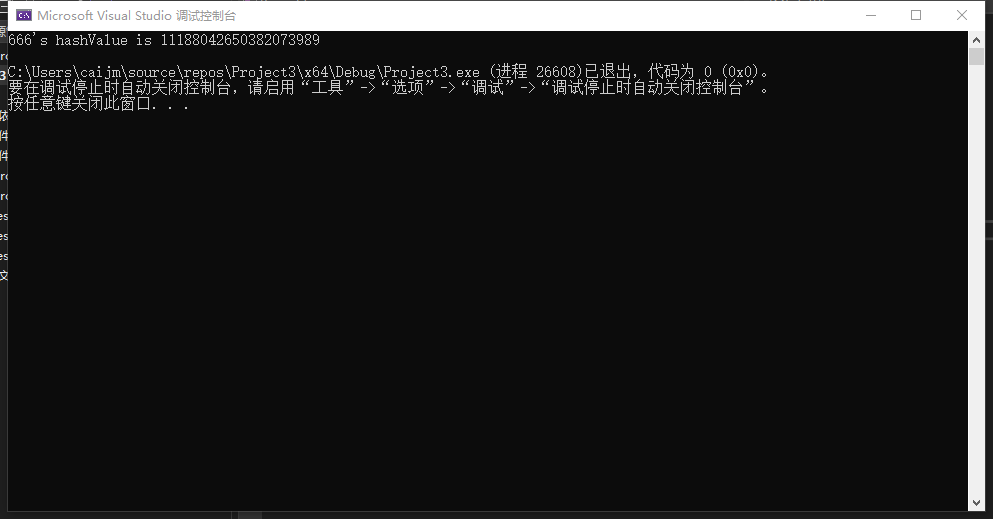
std::cout << num << "'s hashValue is " << hashValue << std::endl;
return 0;
}
🔍注意:C++中规定,哈希值为size_t类型
下面再认识一下std::accumulate,它位于numeric库中,默认情况下,它所实现的就是将数组中的所有数据累加。第一个参数为待计算区间的起始迭代器,第二个参数是待计算区间的终止迭代器,第三个参数是起始值,代码示例如下(下方输出结果为10):
#include <iostream>
#include <vector>
#include <numeric>
int main()
{
std::vector<int> arr = {1, 2, 3, 4};
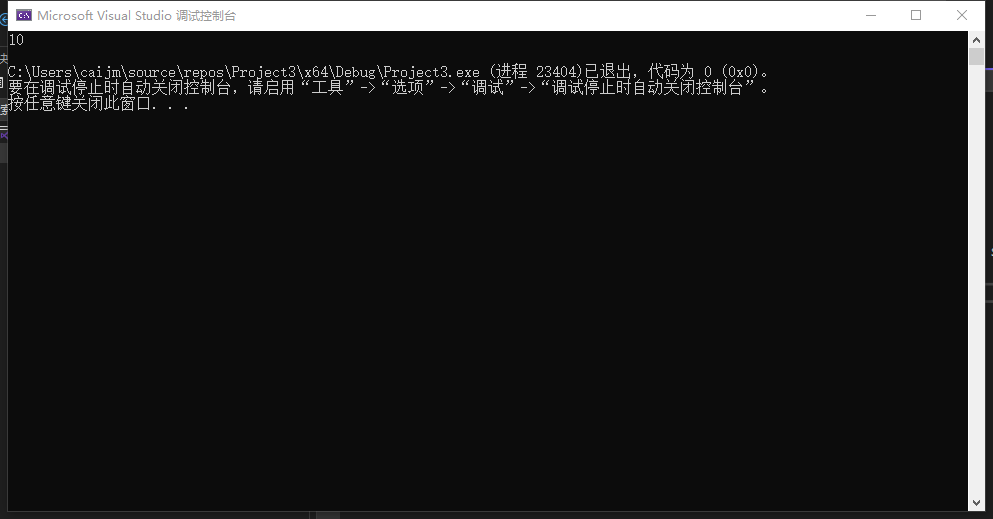
std::cout << std::accumulate(arr.begin(), arr.end(), 0) << std::endl;
return 0;
}
我们可以通过lambda表达式,自定义accumulate的累加操作。下方的acc表示当前所累加的数字综合,num表示当前数字,由accumulate函数自动传入。
#include <iostream>
#include <vector>
#include <numeric>
int main()
{
std::vector<int> arr = {1, 2, 3, 4};
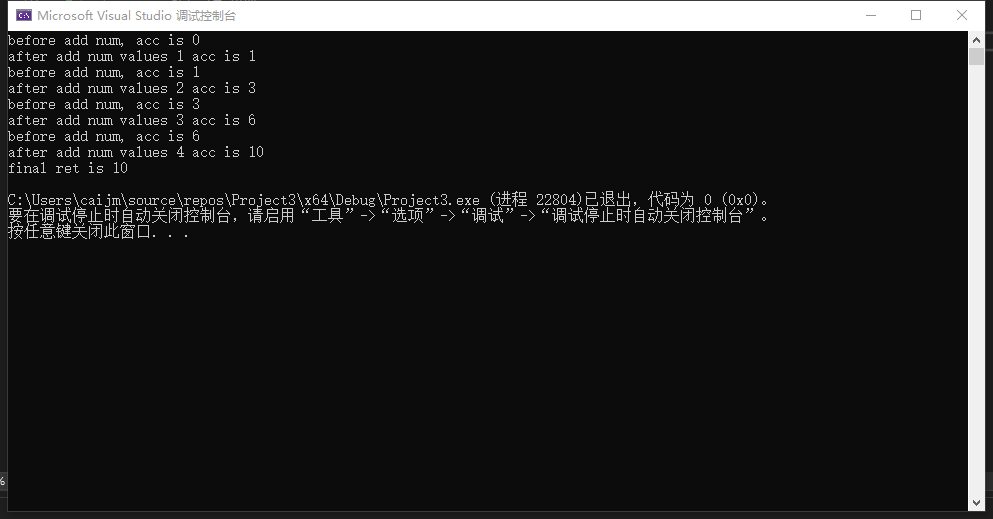
int ret = std::accumulate(arr.begin(), arr.end(), 0, [&](int acc, int num){
std::cout << "before add num, acc is " << acc << std::endl;
acc += num;
std::cout << "after add num values " << num << " acc is " << acc << std::endl;
retrun acc;
});
std::cout << "final ret is " << ret << std::endl;
return 0;
}
介绍完上述的操作后,下面开始介绍自定义哈希函数的方法。unordered_map在存储值域(value)时,先使用哈希函数对键域(key)进行映射操作,找到对应的映射位置后才能存储值(value)。而unordered_map之所以无法使用数组作为键域(key),就是因为缺少对应的哈希映射函数,那我们只要提供对应的哈希映射函数即可。下面提供了一个哈希映射函数。
auto arrayHash = [fn = hash<int>{}](const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num){
return (acc << 1) ^ fn(num);
});
};
这里的哈希映射函数是将累加的数值总和acc<<1,即将acc乘以2,再与生成的哈希值fn(num)做异或运算。下面我们将哈希映射函数提供给unordered_map,它就可以实现对数组作为键域(key)的位置映射。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
auto arrayHash = [fn = hash<int>{}](const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {
return (acc << 1) ^ fn(num);
});
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
for(string& str : strs)
{
array<int, 26> counts{};
int length = str.length();
for(int i = 0; i < length; i++)
{
counts[str[i] - 'a']++;
}
mp[counts].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};
这里的思路和哈希算法均为官方给出的题解,我们可能会有疑惑,这里的哈希映射函数,我们可以修改吗?当然可以,只要我们保证不同的值映射到的位置尽可能不同,尽量避免哈希冲突,这个哈希映射函数就是相对成功的。
对于queen的累次计算结果如下:
| 计算次序/对应字母 | acc原值 | acc<<2后数值 | num原值 | fn(num)值 | acc << 2 ^ fn(num)数值 |
|---|---|---|---|---|---|
| 0/a | 0 | 0 | 0 | 0 | 0 |
| 1/b | 0 | 0 | 0 | 0 | 0 |
| 2/c | 0 | 0 | 0 | 0 | 0 |
| 3/d | 0 | 0 | 0 | 0 | 0 |
| 4/e | 0 | 0 | 2 | 2 | 2 |
| 5/f | 2 | 8 | 0 | 0 | 8 |
| 6/g | 8 | 32 | 0 | 0 | 32 |
| 7/h | 32 | 128 | 0 | 0 | 128 |
| 8/i | 128 | 512 | 0 | 0 | 512 |
| 9/j | 512 | 2048 | 0 | 0 | 2048 |
| 10/k | 2048 | 8192 | 0 | 0 | 8192 |
| 11/l | 8192 | 32768 | 0 | 0 | 32768 |
| 12/m | 32768 | 131072 | 0 | 0 | 131072 |
| 13/n | 131072 | 524288 | 1 | 1 | 524289 |
| 14/o | 524289 | 2097156 | 0 | 0 | 2097156 |
| 15/p | 2097156 | 8388624 | 0 | 0 | 8388624 |
| 16/q | 8388624 | 33554496 | 1 | 1 | 33554497 |
| 17/r | 33554497 | 134217988 | 0 | 0 | 134217988 |
| 18/s | 134217988 | 536871952 | 0 | 0 | 536871952 |
| 19/t | 536871952 | 2147487808 | 0 | 0 | 2147487808 |
| 20/u | 2147487808 | 8589951232 | 1 | 1 | 8589951233 |
| 21/v | 8589951233 | 34359804932 | 0 | 0 | 34359804932 |
| 22/w | 34359804932 | 137439219728 | 0 | 0 | 137439219728 |
| 23/x | 137439219728 | 549756878912 | 0 | 0 | 549756878912 |
| 24/y | 549756878912 | 2199027515648 | 0 | 0 | 2199027515648 |
| 25/z | 2199027515648 | 8796110062592 | 0 | 0 | 8796110062592 |
这里的<<(左移)操作本质是扩大acc的数值。不断扩大结果集有助于降低哈希冲突的概率,但这却并不表明我们可以完全避免哈希冲突。由于每个字母至多出现10000次,10000至多需要14个比特位表示,若对acc每次左移14位,可完全避免哈希冲突。但左移位数越多,键域(key)所占的比特数越大。这里通过^(异或)操作尽量打乱二进制位,而不是增加<<(左移)数量的方式来减少哈希冲突概率,可以避免键(key)占用的二进制位过多,但这个哈希函数设计过于简单,有一定概率会出现哈希冲突。至于如何设计函数需要根据不同题目给出,这里不再讨论。这个方法建议作为了解即可,哈希函数的构造需要的数学理论和难度相对较高,这个方法也不容易想到。
最后给出哈希冲突出现的概率的计算过程:
根据异或的交换律可知:一个数组的任何排列组合,它的异或结果都相同。

从上面的规律中,好像可以判断出,若两个数组异或结果相同,则这两个数组是排列顺序不同的相同数组。 实则不然,1⊕2=5⊕6,1⊕2⊕3=4⊕8⊕12,因而上面的结论不成立。
本质原因是组合数一共有 1 + 2 6 1 + 2 6 2 + . . . + 2 6 99 + 2 6 100 1+26^1+26^2+...+26^{99}+26^{100} 1+261+262+...+2699+26100,根据等比数列求和得到 ( 1 − 2 6 100 ) / ( 1 − 26 ) (1-26^{100})/(1-26) (1−26100)/(1−26) ≈ 2 6 100 26^{100} 26100,而异或的结果集 2 26 2^{26} 226,冲突发生概率为 m i n ( 1 0 4 , 2 6 100 ) / 2 26 min(10^4, 26^{100})/2^{26} min(104,26100)/226。
ps:由于0<=str[i].length<=100,故得到 1 + 2 6 1 + 2 6 2 + . . . + 2 6 99 + 2 6 100 1+26^1+26^2+...+26^{99}+26^{100} 1+261+262+...+2699+26100。由于哈希函数每次左移1位,共左移26位,每个位有1或0两种情况,故为 2 26 2^{26} 226。由于题目中strs<= 1 0 4 10^4 104,即并不是26个字母的所有排列组合均会出现,其至多只出现 1 0 4 10^4 104种。
有什么办法解决呢?
用哈希降低冲突!为了解决冲突我们可以将异或的结果集扩大:将数字哈希成64位无符号整数那么结果集扩大为
2
64
2^{64}
264,
m
i
n
(
1
0
4
,
2
6
100
)
/
2
64
min(10^4, 26^{100})/2^{64}
min(104,26100)/264,冲突发生的概率微乎其微。
若是要完全规避哈希冲突,左移14位是最稳妥的方式,代码如下:
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
auto arrayHash = [](const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {
return (acc < 14) | num;
});
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
for(string& str : strs)
{
array<int, 26> counts{};
int length = str.length();
for(int i = 0; i < length; i++)
{
counts[str[i] - 'a']++;
}
mp[counts].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};
但该算法相较于可能发生哈希冲突的方式,多了13×26个比特位,在空间效率上效率略低。
刷题使我快乐😭
文章如有错误,请私信或在下方留言😀


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









