







欢迎来到我的:世界
希望作者的文章对你有所帮助,有不足的地方还请指正,大家一起学习交流 !
前言
在C语言中,文件操作是一项基本而重要的技能。无论是读取配置文件、写入日志还是处理数据,文件操作都是不可或缺的。本文将介绍C语言中文件操作的基本概念、常用函数以及一些实践技巧。
内容
- 首先我们要知道:我们写的程序的数据是存储在电脑的内存中,而内存所指的就是随机存储器(RAM),
性质:当程序结束并且系统断电时,这些数据通常会丢失。即使不停电,一旦程序结束,操作系统可能会回收该程序使用的内存,导致数据丢失。 - 所以如果程序退出,内存回收,数据就丢失了,等再次运⾏程序,是看不到上次程序的数据的,如果要将数据进⾏持久化的保存,
- 数据持久化存储: 那么就需要程序在运行过程中将数据保存到了数据库、文件系统或其他持久化存储中,那么这些数据会在程序结束后依然存在。
- 我们可以使⽤⽂件(文件是存储在硬盘上的),硬盘:
如果数据被写入到硬盘(无论是HDD还是SSD),那么即使程序结束,这些数据也会被保留。硬盘是一种非易失性存储,可以在断电后仍然保持数据不丢失。
文件
在程序设计中,文件按照其存储的数据和用途进行分类为:数据文件和程序文件
- 程序文件:其实就是程序员存写的代码的文件,是指包含计算机程序的文件,这些程序是一系列指令的集合,由编程语言编写,用于执行特定的任务。程序文件通常需要被编译或解释执行。包括了源程序文件(以.c为后缀)、目标文件(以.obj为后缀)、可执行文件(以.exe为后缀);
- 数据文件:数据文件是指包含数据的文件,这些数据可以是文本、数字、图像、音频等任何形式的信息。数据文件通常用于存储、传输和处理数据。
文件操作:
一般来说,对文件的操作,都是对数据文件的相关操作,因为都是程序员对文件进行相关操作,进行打开、读取、写入、关闭文件等。
比如:有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使⽤,这⾥处理的就是磁盘上⽂件。
数据库文件概述:
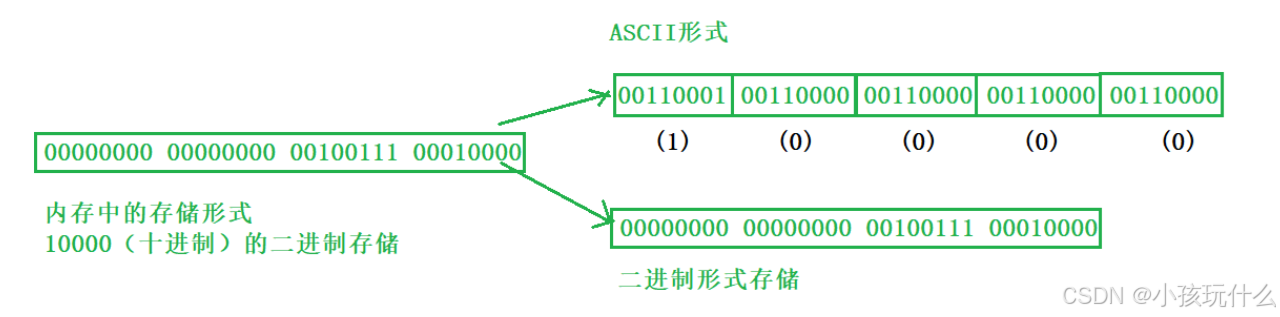
一个数据在内存中是如何存储的呢?
字符⼀律以ASCII形式存储,数值型数据既可以⽤ASCII形式存储,也可以使⽤⼆进制形式存储。
- 文本文件:如.txt、.csv、.xml等,包含可读的文本信息。
- 二进制文件:如.bin、.dat、.jpg等,包含二进制数据,可能包含图像、音频、视频等。
- 数据库文件:如.db、.sql等,用于存储和管理结构化数据。
解释:要知道数据在内存中以⼆进制的形式存储,如果不加转换的输出到外存,就是⼆进制⽂件。
如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的⽂件就是⽂本⽂件。
如有整数10000,如果以ASCII码的形式输出到磁盘,就是按照每个字符的ASCII码存储,则磁盘中占⽤5个字节(每个字符⼀个字节),⽽⼆进制形式输出,则在磁盘上只占4个字节
数据文件的主要特点包括:
- 存储性:数据文件主要用于存储数据,以便后续的访问和处理。
- 格式多样性:数据文件可以有不同的格式,每种格式都有其特定的用途和结构。
- 非执行性:数据文件通常不包含可执行的代码,它们是静态的数据集合。
补充:程序文件与数据文件的关系
- 交互:程序文件可以读取和写入数据文件,进行数据处理。
- 依赖:程序文件的运行可能依赖于数据文件,例如,一个应用程序可能需要读取配置文件或用户数据来执行任务。
- 输出:程序文件可以生成数据文件作为输出,例如,日志文件、报告等。
在实际应用中,程序文件和数据文件是相辅相成的,程序文件提供了处理数据的能力,而数据文件提供了程序文件需要处理的对象。理解这两种文件类型的区别和联系,对于编程和数据处理都是非常重要的。
文件的打开和关闭
理解流的概念
我们程序的数据需要输出到各种外部设备,也需要从外部设备获取数据,不同的外部设备的输⼊输出操作各不相同,为了⽅便程序员对各种设备进⾏⽅便的操作,我们抽象出了流的概念,我们可以把流想象成流淌着字符的河。
就可以把流看成一个中间商,它会帮助程序员对于不同的外部设备进行细节处理;
C程序针对⽂件、画⾯、键盘等的数据输⼊输出操作都是通过流操作的。
⼀般情况下,我们要想向流⾥写数据,或者从流中读取数据,都是要打开流,然后操作。
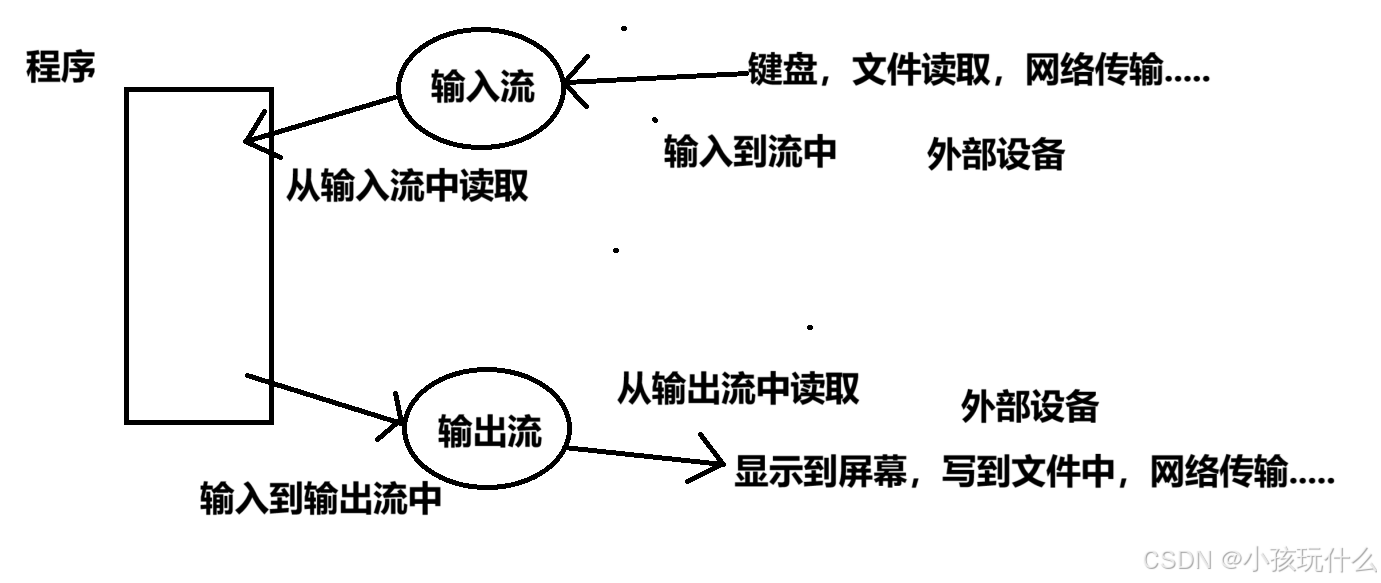
注意: C语⾔程序在启动的时候,默认打开了3个流:
• stdin - 标准输⼊流,在⼤多数的环境中从键盘输⼊,scanf函数就是从标准输⼊流中读取数据。
• stdout - 标准输出流,⼤多数的环境中输出⾄显⽰器界⾯,printf函数就是将信息输出到标准输出
流中。
• stderr - 标准错误流,⼤多数环境中输出到显⽰器界⾯。
这是默认打开了这三个流,我们使⽤scanf、printf等函数就可以直接进⾏输⼊输出操作的。
文件指针
缓冲⽂件系统中,关键的概念是“⽂件类型指针”,简称“⽂件指针”
每个被使⽤的⽂件都在内存中开辟了⼀个相应的⽂件信息区,⽤来存放⽂件的相关信息(如⽂件的名字,⽂件状态及⽂件当前的位置等)。这些信息是保存在⼀个结构体变量中的。该结构体类型是由系统声明的,取名FILE。
不同的C编译器的FILE类型包含的内容不完全相同,但是⼤同⼩异。
每当打开⼀个⽂件的时候,系统会根据⽂件的情况⾃动创建⼀个FILE结构的变量,并填充其中的信息,使⽤者不必关⼼细节。
⼀般都是通过⼀个FILE的指针来维护这个FILE结构的变量,这样使⽤起来更加⽅便。
如图解释:
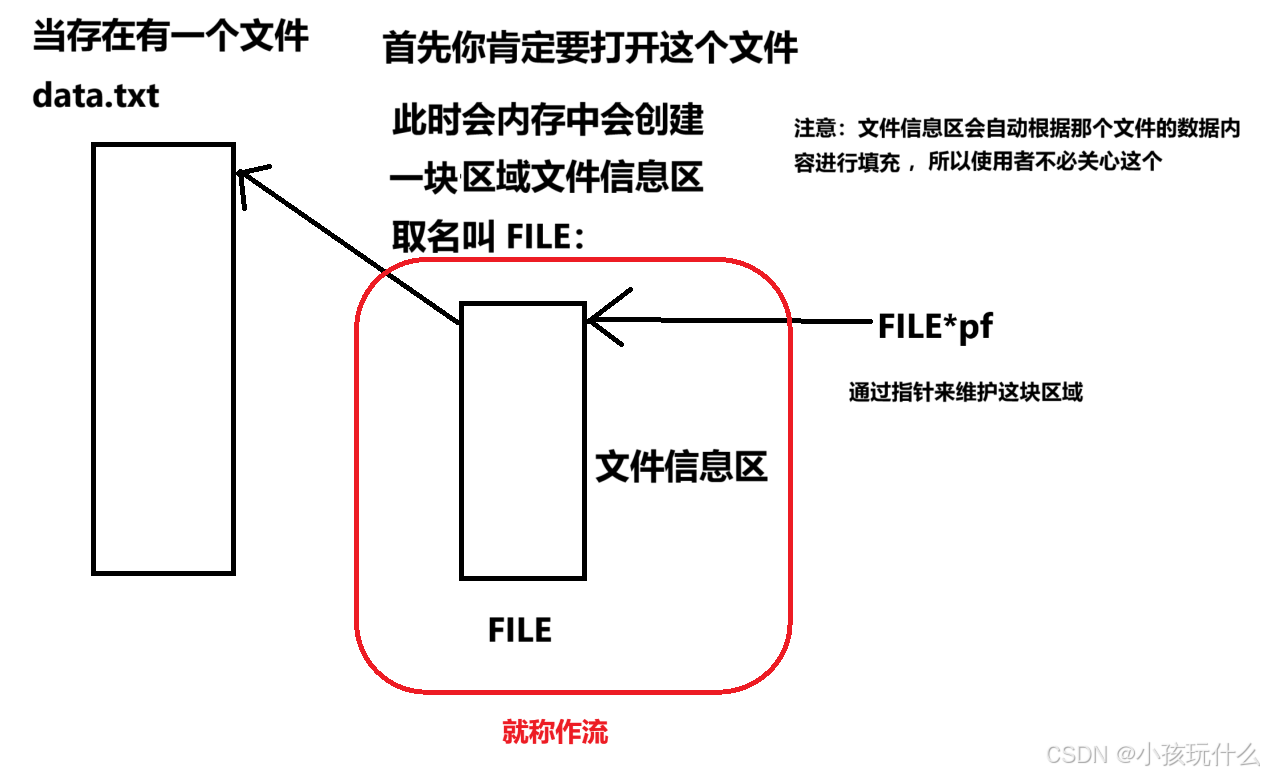
定义pf是⼀个指向FILE类型数据的指针变量。可以使 pf 指向某个⽂件的⽂件信息区(是⼀个结构体变量)。通过该⽂件信息区中的信息就能够访问该⽂件。也就是说,通过⽂件指针变量能够间接找到与它关联的⽂件。
所以对于上述中的stdin、stdout、stderr 三个流的类型是: FILE* ,通常称为⽂件指针。
C语⾔中,就是通过 FILE* 的⽂件指针来维护流的各种操作的。
文件的打开与关闭
⽂件在读写之前应该先打开⽂件,在使⽤结束之后应该关闭⽂件。
在编写程序的时候,在打开⽂件的同时,都会返回⼀个FILE*的指针变量指向该⽂件,也相当于建⽴了指针和⽂件的关系。
//打开⽂件
FILE * fopen ( const char * filename, const char * mode );
//关闭⽂件
int fclose ( FILE * stream );
解释:filename:指的是要打开的文件名,而mode是打开方式;
举例:
//打开一个文件名为“tt.txt”文件,以“wb”(只写)的方式
//"wb"其含义:为了输出数据,打开⼀个⼆进制⽂件,若没有该文件,则会创建一个新的文件;
FILE* pf = fopen("tt.txt", "wb");
//关闭该文件,
fclose(pf);
pf = NULL;
mode表⽰⽂件的打开模式,下⾯都是⽂件的打开模式:
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
| “r”(只读) | 为了输⼊数据,打开⼀个已经存在的⽂本⽂件 | 出错 |
| “w”(只写) | 为了输出数据,打开⼀个⽂本⽂件 | 建⽴⼀个新的⽂件 |
| “a”(追加) | 向⽂本⽂件尾添加数据 | 建⽴⼀个新的⽂件 |
| “rb”(只读) | 为了输⼊数据,打开⼀个⼆进制⽂件 | 出错 |
| “wb”(只写) | 为了输出数据,打开⼀个⼆进制⽂件 | 建⽴⼀个新的⽂件 |
| “ab”(追加) | 向⼀个⼆进制⽂件尾添加数据 | 建⽴⼀个新的⽂件 |
| “r+”(读写) | 为了读和写,打开⼀个⽂本⽂件 | 出错 |
| “w+”(读写) | 为了读和写,创建⼀个新的⽂件 | 建⽴⼀个新的⽂件 |
| “a+”(读写) | 打开⼀个⽂件,在⽂件尾进⾏读写 | 建⽴⼀个新的⽂件 |
| “rb+”(读写) | 为了读和写打开⼀个⼆进制⽂件 | 出错 |
| “wb+”(读写) | 为了读和写,新建⼀个新的⼆进制⽂件 | 建⽴⼀个新的⽂件 |
| “ab+”(读写) | 打开⼀个⼆进制⽂件,在⽂件尾进⾏读和写 | 建⽴⼀个新的⽂件 |
注意:上述的只是我们片面的理解,如果需要更深入的理解,我们可以根据文献的详细介绍:文献网站
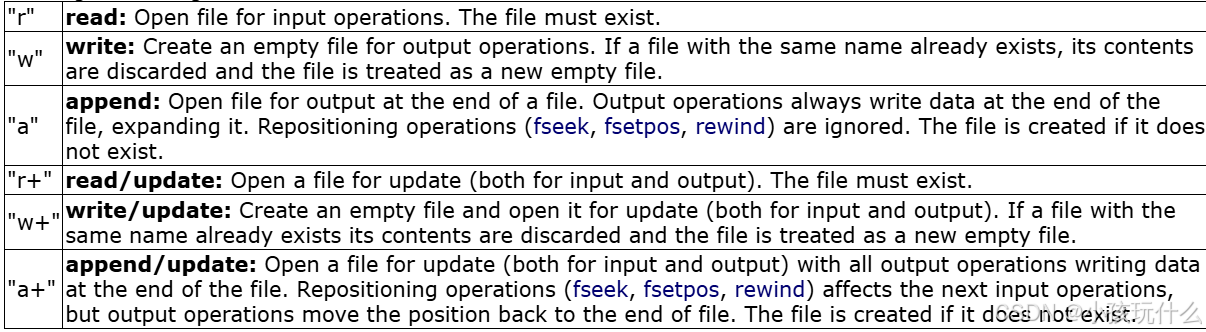
观察到对于方式“w”来说:为输出操作创建一个空文件。如果同名的文件已经存在,则其内容将被丢弃,并将该文件视为新的空文件。
好了,学习了以上那么多内容,我们来做个简单的实例:
int main() {
// 打开文件,以二进制写入模式("wb")打开文件"tt.txt"
// 如果文件不存在,则创建新文件;如果文件存在,则截断文件为0长度
FILE* pf = fopen("tt.txt", "wb");
if (pf == NULL) {
// 如果文件打开失败,使用perror打印错误信息
perror("fopen"); // perror会打印出错误描述,"fopen: "是自定义的前缀
return -1; // 返回-1表示程序因错误而终止
}
// 关闭文件,释放资源
fclose(pf); // 关闭文件指针pf指向的文件
pf = NULL; // 将pf设置为NULL,表示pf不再指向任何文件,避免出现野指针的情况
return 0; // 返回0表示程序正常结束
}
执行该程序够,文件默认会在你程序文件的相对路径创建: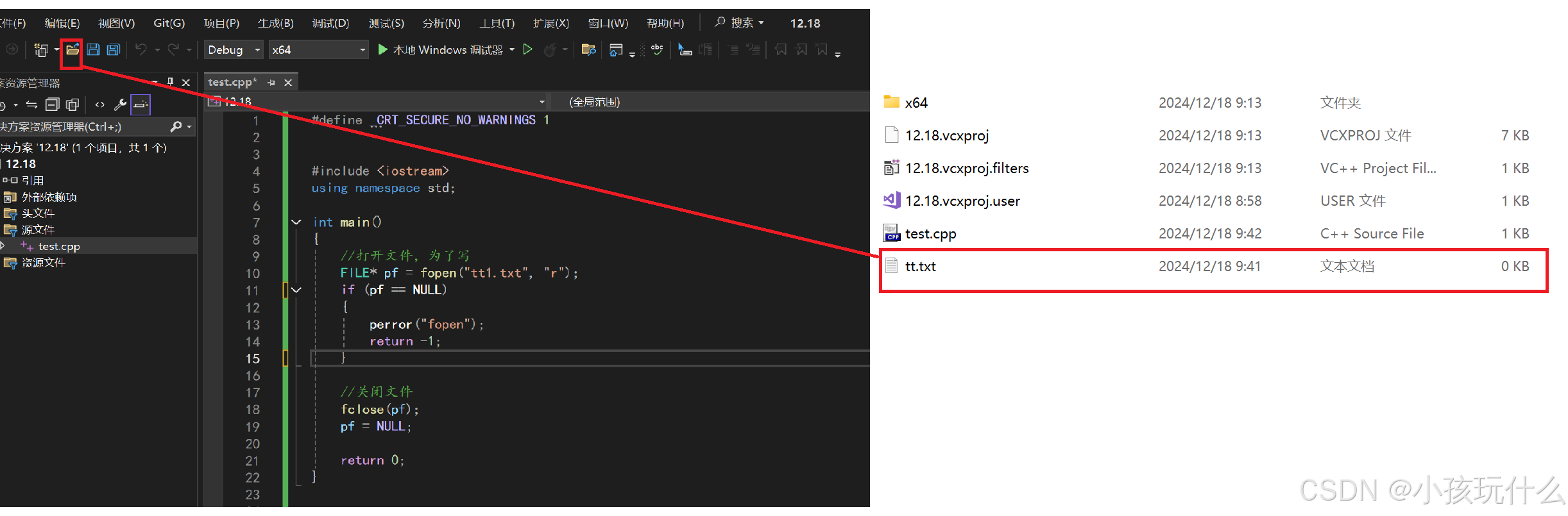
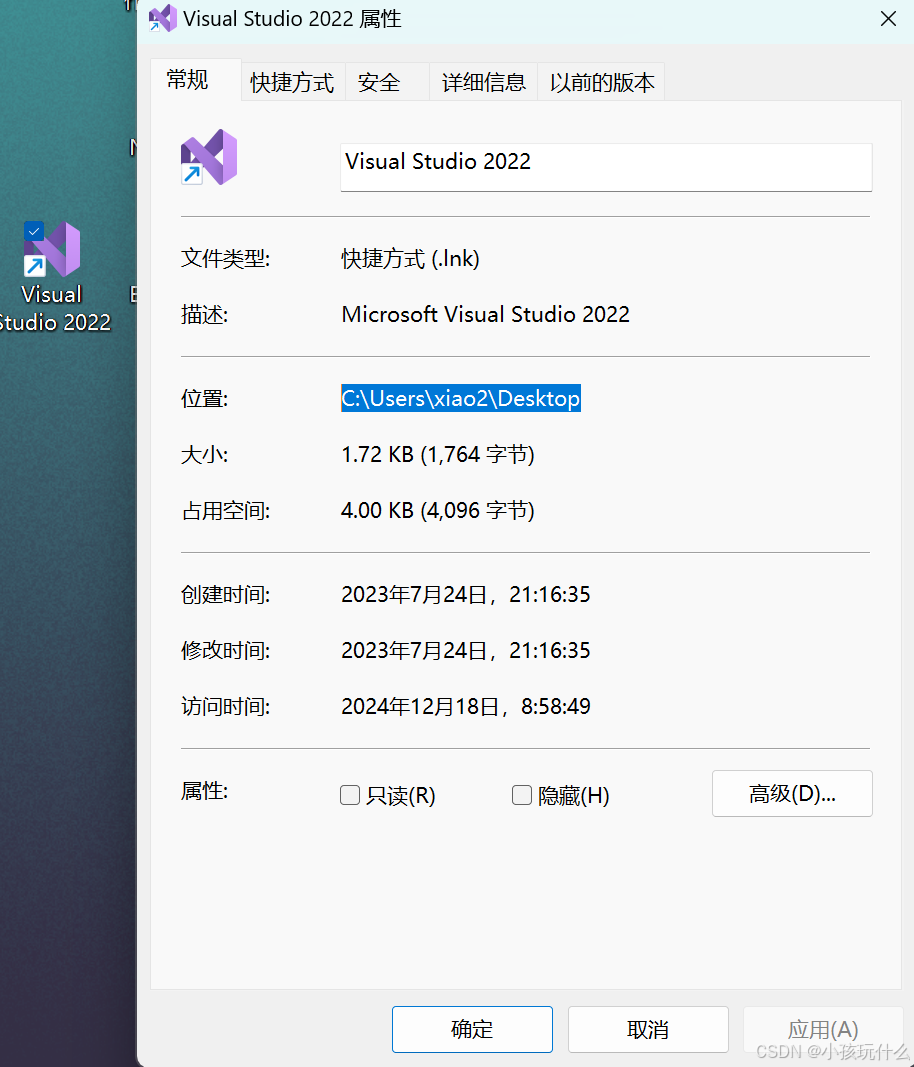
当然你也可以设置你想要的绝对路径:假如我们想直接对桌面上的文件进行操作,只需要找到桌面上的位置:(随意在你自己的桌面上一个程序快捷键,右击,点属性,找到其位置)
然后我们将程序文件改写为绝对路径即可
int main()
{
//打开文件,为了写,注意这里的双斜杠是为了将单斜杠转义
FILE* pf = fopen("C:\\Users\\xiao2\\Desktop\\tt.txt", "w");
if (pf == NULL)
{
perror("fopen");
return -1;
}
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}
在程序执行后,桌面就会创建一个tt.txt的文件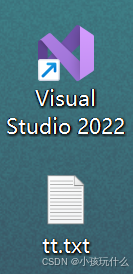
补充知识:
绝对路径(Absolute Path)
定义:绝对路径是从根目录(在Unix-like系统中是/,在Windows系统中是盘符如C:\)开始的完整路径。
特点:
- 不依赖于当前工作目录,无论在哪个目录下,绝对路径都能准确指向文件系统中的同一个位置。
- 通常包含盘符(在Windows中)和完整的目录结构。
- 因为包含了完整的路径信息,所以比较长。
相对路径(Relative Path)
定义:相对路径是相对于当前工作目录的路径。
特点:
- 依赖于当前工作目录,不同的工作目录下,相对路径可能指向不同的位置。
- 通常较短,因为它只包含从当前目录到目标文件的路径。
- 使用.表示当前目录,
..表示上级目录。
好了,介绍完文件的打开和关闭,接下来将介绍文件的读和写:
文件的读和写
文件的顺序读写
顺序读取是指按照文件中数据的物理存储顺序,从文件的开始到结束依次读取数据。在这种方式下,文件被当作一个线性序列,每次读取操作都会从当前位置向后移动一定量的数据。
| 函数名 | 功能 | 适⽤于 |
|---|---|---|
| fgetc | 字符输⼊函数 | 所有输⼊流 |
| fputc | 字符输出函数 | 所有输出流 |
| fgets | ⽂本⾏输⼊函数 | 所有输⼊流 |
| fputs | ⽂本⾏输出函数 | 所有输出流 |
| fscanf | 格式化输⼊函数 | 所有输⼊流 |
| fprintf | 格式化输出函数 | 所有输出流 |
| fread | ⼆进制输⼊ | ⽂件输入流 |
| fwrite | ⼆进制输出 | ⽂件输出流 |
上⾯说的适⽤于所有输⼊流⼀般指适⽤于标准输⼊流和其他输⼊流(如⽂件输⼊流);所有输出流⼀般指适⽤于标准输出流和其他输出流(如文件输出流)。
所以举个例子理解:
如果我们想写26个字母写入到tt.txt文件中去,所以我们要用到fputc函数:
- 介绍fputc函数
fputc 函数将参数 c 指定的字符写入由 stream 指定的文件流中。这个函数通常用于写入单个字符,但它也可以写入任何整数,因为字符在 C 语言中是以整数形式存储的。
int fputc ( int character, FILE * stream );
character:要写入文件的字符(以整数形式表示)
stream:指向 FILE 对象的指针,该 FILE 对象标识了要写入的文件流。
其返回值:
如果成功写入字符,fputc 返回写入的字符。
如果发生错误或到达文件末尾(EOF),返回 EOF(通常是 -1)
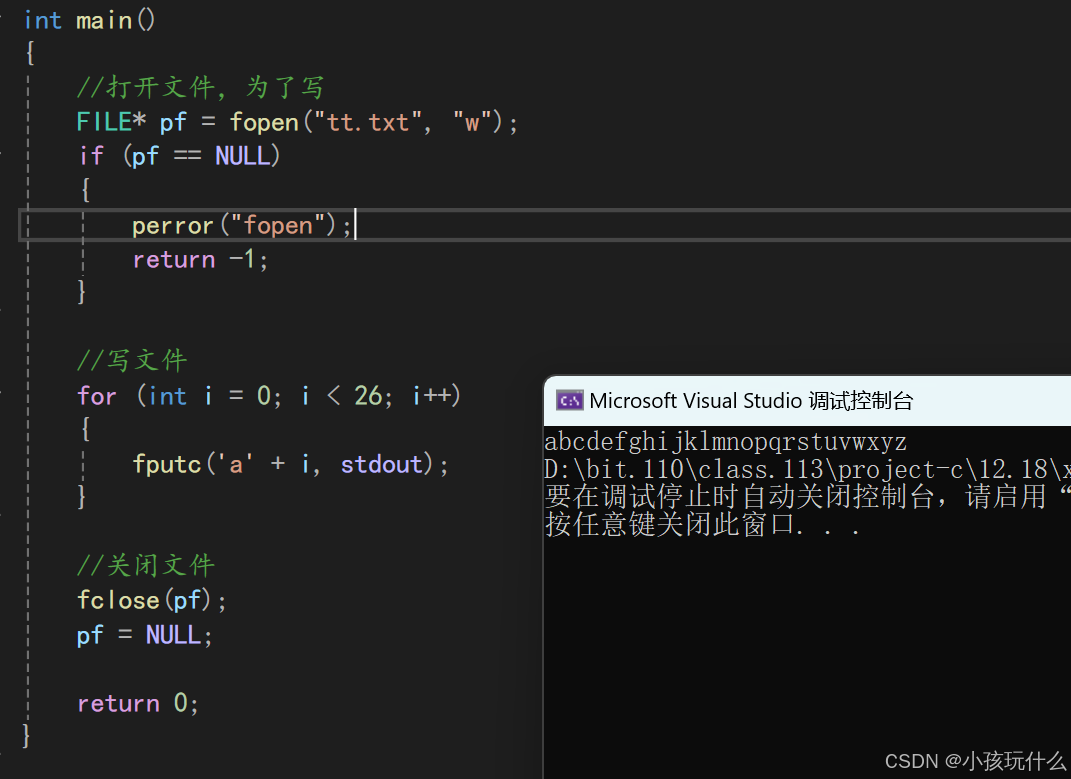
int main() {
// 打开文件,以写入模式打开"tt.txt",如果文件不存在则创建
FILE* pf = fopen("tt.txt", "w");
if (pf == NULL) {
// 如果文件打开失败,打印错误信息并返回-1
perror("fopen");
return -1;
}
// 循环写入26个英文小写字母到文件中
for (int i = 0; i < 26; i++) {
fputc('a' + i, pf); // 写入单个字符到文件
}
// 关闭文件,释放资源
fclose(pf);
// 将文件指针设置为NULL,表示文件已关闭
pf = NULL;
return 0; // 程序正常退出,返回0
}
在程序执行完成后,26个小写字母也就写入了该tt.txt文本文件中:
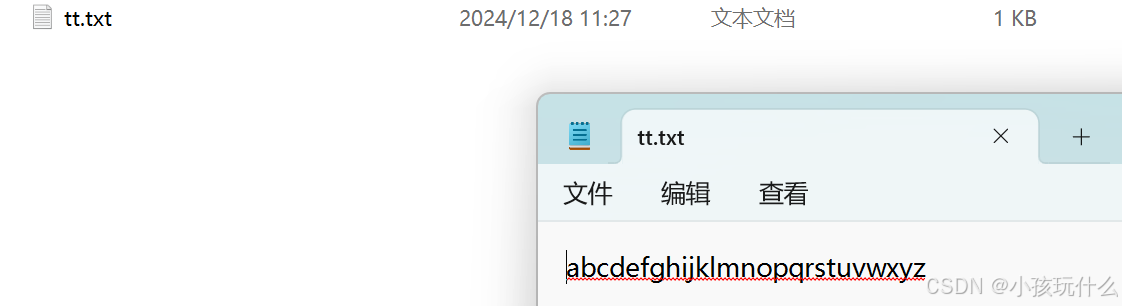
很容易就可以看出这是顺序写的方式;
以上是写入文件的一种方式:是因为fputc函数提供了文件输出流的接口,当然这个函数适用于所有的流,所以也就是说我们可以控制其流的接口,若pf文件输出流改为stdout标准输出流,又会有不同的效果;
stdout标准输出流:在 C 程序中,stdout 是一个指向 FILE 结构的指针,通常用于向终端或命令行窗口输出数据。它是全局可访问的,因此在程序的任何地方都可以使用它来打印信息。
// 循环写入26个英文小写字母到标准输出(屏幕)
for (int i = 0; i < 26; i++) {
fputc('a' + i, stdout); // 写入单个字符到标准输出
}
以上是对文件的顺序写,接下来我来介绍对文件的顺序读:
文件的顺序读取:
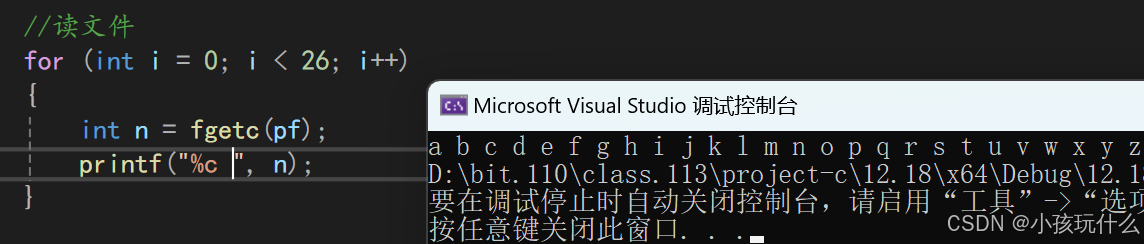
介绍fgetc函数:
我需要起码知道fgetc函数来读取文件数据;功能:从流(所有流)中获取元素

返回值 :如果读取成功,则返回读取到的字符的ASCII码值;如果读取失败,则返回EOF(-1);
这样我们也就可以顺序读取tt.txt文件的数据了:
根据以上所学的知识,来拓展一个做一个练习:文件的拷贝,把tt.txt文件里的数据拷贝到tt1.txt文件中去
void test1() {
// 打开文件 "tt.txt" 用于读取
FILE* pread = fopen("tt.txt", "r");
// 检查是否成功打开文件 "tt.txt"
if (pread == NULL) {
perror("Error opening tt.txt for reading");
return; // 如果打开失败,则退出函数
}
// 打开文件 "tt1.txt" 用于写入
FILE* pwrite = fopen("tt1.txt", "w"); // 如果文件不存在,则创建它
// 检查是否成功打开文件 "tt1.txt"
if (pwrite == NULL) {
perror("Error opening tt1.txt for writing");
fclose(pread); // 关闭已打开的读取文件
return; // 如果打开失败,则退出函数
}
int ch = 0; // 用于存储从文件中读取的字符
// 循环读取 "tt.txt" 中的内容,直到到达文件末尾(EOF)
while ((ch = fgetc(pread)) != EOF) {
fputc(ch, pwrite); // 将读取的字符写入 "tt1.txt"
}
// 关闭读取的文件
fclose(pread);
// 关闭写入的文件
fclose(pwrite);
// 将文件指针设置为NULL,表示文件已经关闭
pread = NULL;
pwrite = NULL;
}
对于其余的函数在本篇博客中就不过多介绍了,下一篇的博客我在细节介绍;
文件的随机读写
随机读取是指可以直接访问文件中的任意位置,而不需要从头开始读取。这种方式允许程序快速跳转到文件的任何部分,读取或写入数据。
首先需要介绍几个函数的使用:
fseek函数:根据⽂件指针的位置和偏移量来定位⽂件指针。其原型如下:
int fseek ( FILE * stream, long int offset, int origin );
参数介绍:
stream:指向FILE对象的指针,该FILE对象标识了流。
offset:移动的字节偏移量。
origin:指定offset的起始位置,可以是以下宏之一:SEEK_SET:文件开头(默认值)。
SEEK_CUR:当前文件位置。
SEEK_END:文件末尾。功能描述:
fseek函数根据orgin参数指定的参考点和offset参数指定的偏移量来移动文件位置指针。如果成功,函数返回0;如果失败,返回非0值。
举个实例:
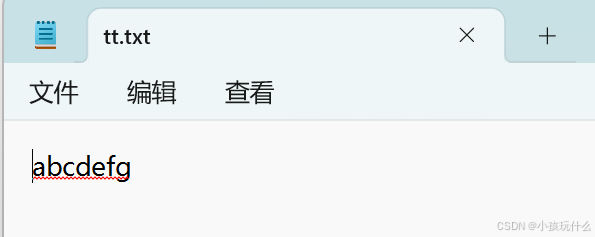
若我在tt.txt文件中存入abcdefg:
此时我要一个一个顺序读取出来,以下代码实现:
//第一次读取时,文件指针(也叫光标)的位置在开头位置
//所以此时读取第一个字符:a
int ch = fgetc(pf);
printf("%c\n", ch);
//当读取完第一次后,文件指针的位置会向后移偏移一个字节
//此时在读取字符为:b
ch = fgetc(pf);
printf("%c\n", ch);
//以上述步骤类似:
//此时读取一个字符:c
ch = fgetc(pf);
printf("%c\n", ch);
//此时读取一个字符:d
ch = fgetc(pf);
printf("%c\n", ch);
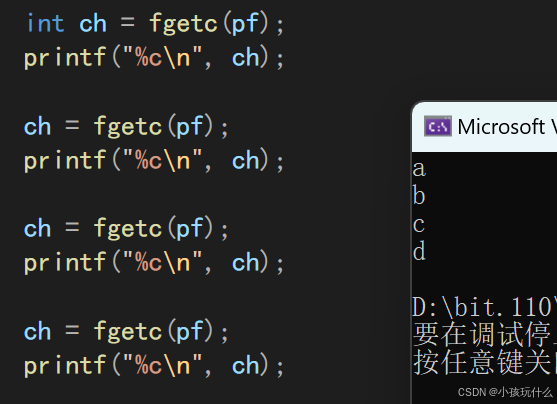
此时可以使用fseek函数,重新定位其函数指针(光标)的位置,下面举例介绍该函数的使用方法;
//第一次读取时,文件指针(也叫光标)的位置在开头位置
//所以此时读取第一个字符:a
int ch = fgetc(pf);
printf("%c\n", ch);
//当读取完第一次后,文件指针的位置会向后移偏移一个字节
//此时在读取字符为:b
ch = fgetc(pf);
printf("%c\n", ch);
//以上述步骤类似:
//此时读取一个字符:c
ch = fgetc(pf);
printf("%c\n", ch);
//此时读取一个字符:d
ch = fgetc(pf);
printf("%c\n", ch);
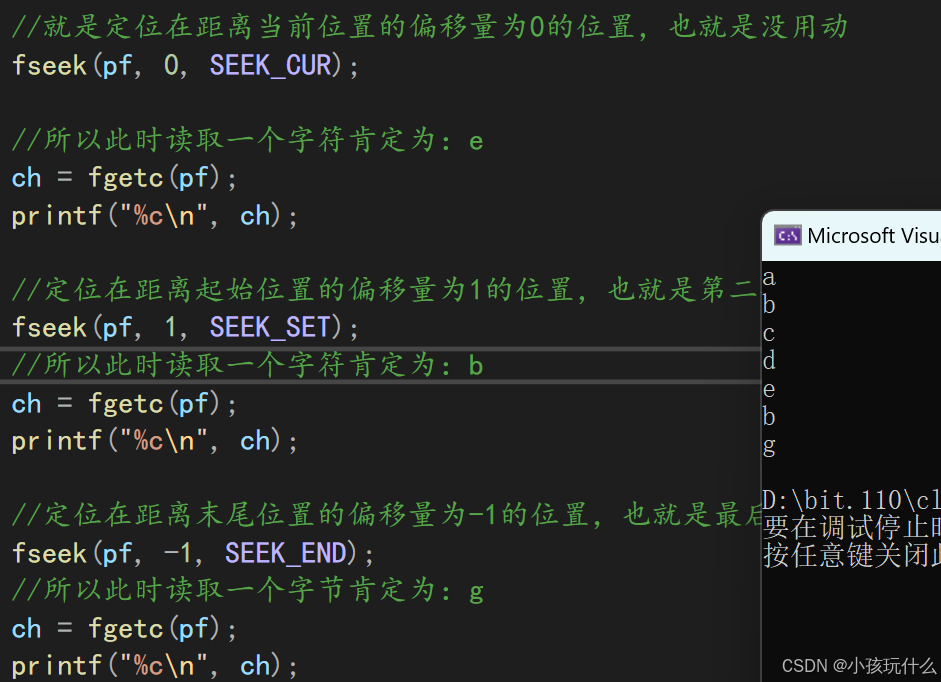
//就是定位在距离当前位置的偏移量为0的位置,也就是没用动
fseek(pf, 0, SEEK_CUR);
//所以此时读取一个字符肯定为:e
ch = fgetc(pf);
printf("%c\n", ch);
//定位在距离起始位置的偏移量为1的位置,也就是第二个字节的位置
fseek(pf, 1, SEEK_SET);
//所以此时读取一个字符肯定为:b
ch = fgetc(pf);
printf("%c\n", ch);
//定位在距离末尾位置的偏移量为-1的位置,也就是最后一个字节的位置
fseek(pf, -1, SEEK_END);
//所以此时读取一个字节肯定为:g
ch = fgetc(pf);
printf("%c\n", ch);
但是对于一个很复杂的文件的话,操作起来会比较麻烦;
这里我在介绍一个函数:fstell
ftell函数:用于获取文件流当前位置相对于文件开头的偏移量。简单说就是:ftell函数返回给定流stream的当前文件位置,即从文件开头到当前位置的字节数量;
原型如下:
long int ftell ( FILE * stream );
stream参数是指向要获取位置的文件流的指针
返回值:
- 如果调用成功,函数返回从文件开头算起的字节数量。
- 如果发生错误(例如,文件指针的位置超出文件尾,或者文件流出>现错误),函数返回-1L
举个实例:若需要计算该文件的大小?
可以先使用
fseek函数定位到最后的位置,在使用ftell函数获取其与起始位置的偏移量就是这个文件的大小;
FILE* pf = fopen("tt.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
fseek(pf, 0, SEEK_END);//光标定位到文件的末尾
long size = ftell(pf);//再计算与起始位置的偏移量
printf("%d",size);//对“abcdefg”,其文件的大小为 7个字节
fclose(pf);
pf = NULL;
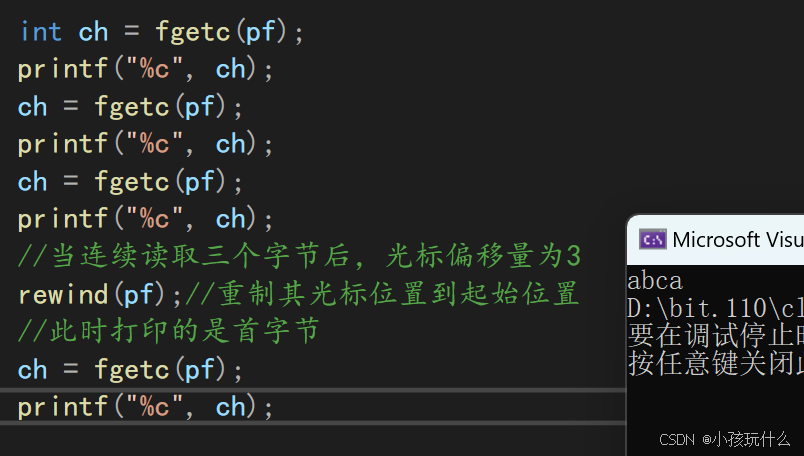
最后再介绍一个函数:rewind:用于将文件流的读/写位置指针重置到文件的开头;其原型如下:
void rewind ( FILE * stream );
stream参数是指向要重置位置的文件流的指针
功能:
rewind函数将指定文件流stream的文件位置指针重置到文件的开头,即文件的起始位置。这通常用于重新开始读取文件或在文件中重新定位到开始位置。
无返回值;
下面举例:
⽂件读取结束的判定
feof函数:用于检查流(通常是文件流)是否已经到达文件末尾(EOF)。当从文件读取数据时,如果已经读取到文件的末尾,feof 函数会返回一个非零值,通常为 1。如果文件没有到达末尾,它返回 0。其原型如下:
int feof ( FILE * stream );
stream:指向 FILE 对象的指针,该 FILE 对象标识了流。
返回值:
如果流的末尾已经被到达,返回一个非零值(通常是 1)。
如果流的末尾没有被到达,返回 0。
ferror函数:用于检查指定的流(通常是文件流)是否发生了错误。当在文件操作过程中发生错误时,ferror 函数会返回一个非零值,通常为 1。如果流没有错误,它返回 0。其原型如下:
int ferror ( FILE * stream );
stream:指向 FILE 对象的指针,该 FILE 对象标识了流。
返回值:
如果流发生了错误,返回一个非零值(通常是 1)。
如果流没有错误,返回 0。
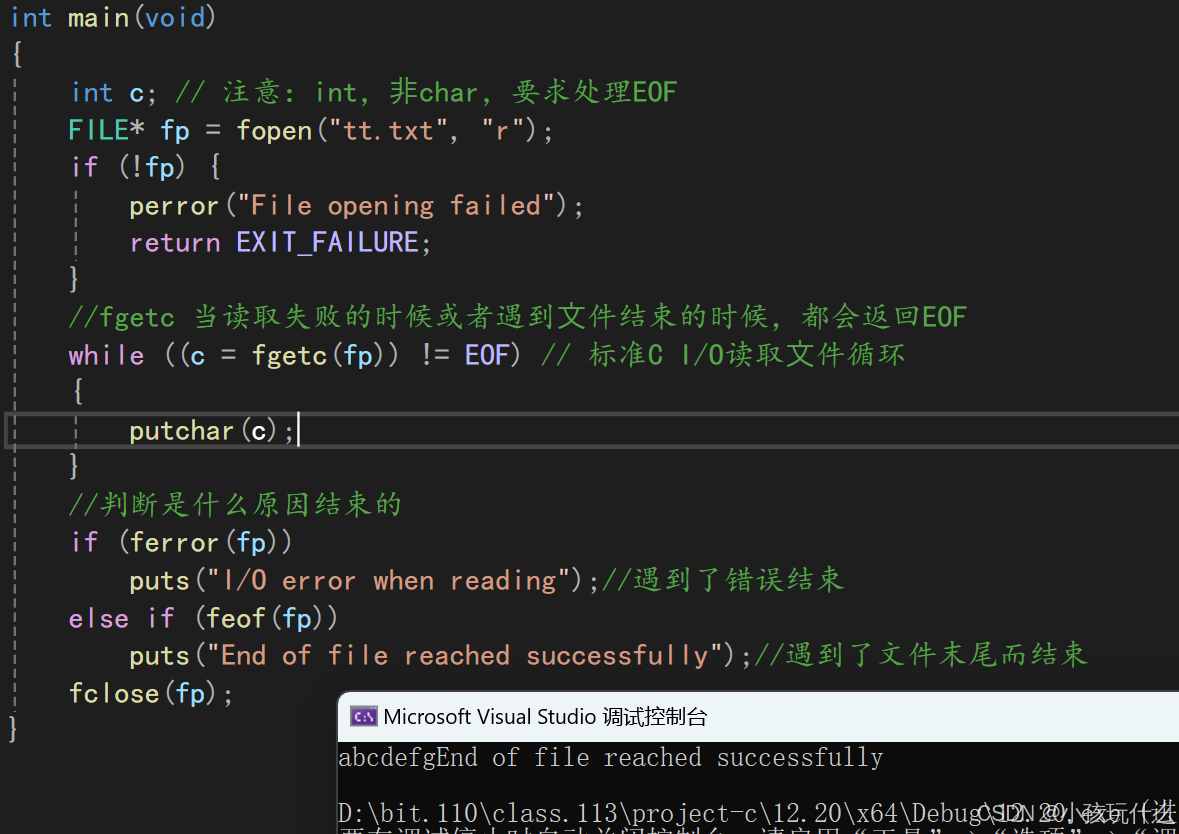
1.判断文本文件读取是否结束:
当使用fgetc函数读取时如果读取成功,则返回读取到的字符;如果读取失败,则返回EOF(-1);若使用fgets函数读取时如果成功读取数据,返回 str 指向的指针。如果发生错误或到达文件末尾(EOF),返回 NULL。
2.判断⼆进制⽂件的读取是否结束:
使用fread函数读取时判断返回值是否⼩于实际要读的个数。
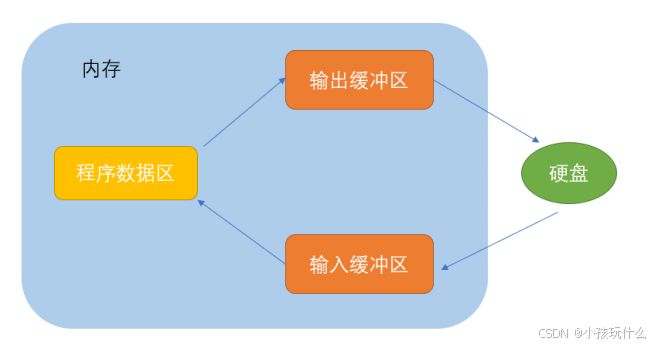
文件缓冲区
ANSIC 标准采⽤“缓冲⽂件系统”处理的数据⽂件的,所谓缓冲⽂件系统是指系统⾃动地在内存中为程序中每⼀个正在使⽤的⽂件开辟⼀块“⽂件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才⼀起送到磁盘上。如果从磁盘向计算机读⼊数据,则从磁盘⽂件中读取数据输⼊到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的⼤⼩根据C编译系统决定的。
文件缓冲区主要目的是提高文件操作的效率,减少对磁盘的直接访问次数
注意:缓冲区刷新也会将缓冲区内容写入文件;
缓冲区刷新:
缓冲区可以在特定条件下被刷新(即缓冲区的内容被写入文件),这些条件包括:缓冲区满、程序显式调用fflush函数、文件被关闭、程序结束等。
下面举例:
int main()
{
FILE* pf = fopen("tt.txt", "w");
fputs("abcdef", pf);//先将代码放在输出缓冲区
printf("睡眠10秒-已经写数据了,此时打开tt.txt⽂件,你会发现⽂件没有内容\n");
Sleep(10000);
printf("刷新缓冲区\n");
fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到⽂件(磁盘)
//注:fflush 在⾼版本的VS上不能使⽤了
printf("再睡眠10秒-此时,再次打开test.txt⽂件,⽂件有内容了\n");
Sleep(10000);
fclose(pf);
//注:fclose在关闭⽂件的时候,也会刷新缓冲区
pf = NULL;
return 0;
}
缓冲区与文件结束:
当程序读取文件时,如果到达文件末尾(EOF),缓冲区可能不会立即被清空,因为缓冲区中可能还有未处理的数据。
文件缓冲区类型:
- 全缓冲(Full buffering):对于输出操作,数据被写入缓冲区,直到缓冲区满或者显式调用fflush函数,缓冲区的内容才会被写入文件。
- 行缓冲(Line buffering):对于输出操作,通常在每次换行符(\n)出现时,缓冲区的内容会被写入文件。这对于需要即时输出的应用(如命令行工具)很有用。
- 无缓冲(Unbuffered):数据直接从应用程序写入文件,不经过缓冲区。
缓冲区通常由操作系统或运行时库管理,程序员不需要直接管理缓冲区的内存,但需要理解缓冲区的行为,以避免数据丢失或不一致。
总结
到了最后:感谢支持
------------对过程全力以赴,对结果淡然处之


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









