









一、构造函数
什么是构造函数?
•类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。
•构造,那构造的是什么呢?
构造成员变量的初始化值,内存空间等
•构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值。
下面的实例有助于更好地理解构造函数的概念:
#include <iostream>
using namespace std;
class Car
{
public:
string brand;
string type;
int year;
Car(string b,string t,int y):brand(b),type(t),year(y){
cout << "参数列表的方式进行构造函数" << endl;
}
Car(){
cout << "无参数构造函数被调用" << endl;
}
Car(string b){
cout << "带一个参数构造函数被调用" << endl;
brand = b;
}
Car(string b,int y){
cout << "带两个参数构造函数被调用" << endl;
brand = b;
year = y;
}
void display(){
cout << "Brand:" << brand << " Year:" << year << endl;
}
void displayAll(){
cout << "Brand:" << brand << " Type:" << type << " Year:" << year << endl;
}
};
int main()
{
Car car;
car.brand = "奥迪";
car.year = 2008;
car.display();
Car car1("小米");
car1.year = 2024;
car1.display();
Car car2("宝马",2009);
car2.display();
Car car3("奇瑞","风云2",2016);
car3.displayAll();
return 0;
}
二、拷贝构造函数
1.基本概念及发生条件
•拷贝构造函数是 C++ 中的一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它在以下几种情况下被调用:
•当一个新对象被创建为另一个同类型的现有对象的副本时:
例如:MyClass obj1 = obj2; 或 MyClass obj1(obj2);,其中 obj2 是现有的对象。
•将对象作为参数传递给函数时(按值传递):
当对象作为参数传递给函数,并且参数不是引用时,会使用拷贝构造函数创建函数内部的对象副本。
•从函数返回对象时(按值返回):
当函数返回对象,并且没有使用引用或指针时,拷贝构造函数用于从函数返回值创建副本。
•初始化数组或容器中的元素时:
例如,在创建一个包含对象的数组时,数组中的每个对象都是通过拷贝构造函数初始化的。
拷贝构造函数的典型声明如下:
class MyClass {
public:
MyClass(const MyClass& other);
};
其中,other 是对同类型对象的引用,通常是常量引用。
示例代码
#include <iostream>
#include <string>
using namespace std;
class Car {
public:
string brand;
int year;
// 常规构造函数
Car(string b, int y) : brand(b), year(y) {}
// 拷贝构造函数
Car(const Car& other) {
brand = other.brand;
year = other.year;
cout << "拷贝构造函数被调用" << endl;
}
void display() {
cout << "Brand: " << brand << ", Year: " << year << endl;
}
};
int main() {
Car car1("Toyota", 2020); // 使用常规构造函数
Car car2 = car1; // 使用拷贝构造函数
car1.display();
car2.display();
return 0;
}
2.浅拷贝
浅拷贝只复制对象的成员变量的值。如果成员变量是指针,则复制指针的值(即内存地址),而不是指针所指向的实际数据。这会导致多个对象共享相同的内存地址。
#include <iostream>
using namespace std;
class Shallow {
public:
int* data;
Shallow(int d) {
//(d):这是初始化表达式。在这里,分配的 int 类型内存被初始化为 d 的值。如果 d 的值是 20,那么分配的内存将被初始化为 20。
data = new int(d); // 动态分配内存
cout << "观察数据:" << endl;
cout << d << endl;
cout << *data << endl;
cout << "观察内存在构造函数中:" << endl;
cout << data << endl;
}
// 默认的拷贝构造函数是浅拷贝
~Shallow() {
delete data; // 释放内存
}
};
int main() {
Shallow obj1(20);
Shallow obj2 = obj1; // 浅拷贝
cout << "观察内存在main函数obj2的data地址:" << endl;
cout << obj2.data << endl;
cout << "obj1 data: " << *obj1.data << ", obj2 data: " << *obj2.data << endl;
return 0;
}
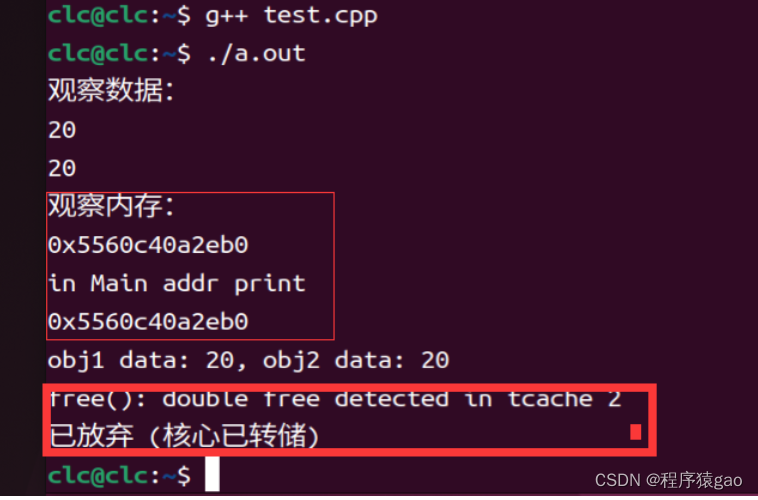
在这个例子中,obj2 是通过浅拷贝 obj1 创建的。这意味着 obj1.data 和 obj2.data 指向相同的内存地址。
当 obj1 和 obj2 被销毁时,同一内存地址会被尝试释放两次,导致潜在的运行时错误。
在QT中我们不能直观看见,在Linux中我们获得如下运行结果:
3.深拷贝
深拷贝复制对象的成员变量的值以及指针所指向的实际数据。这意味着创建新的独立副本,避免了共享内存地址的问题。
#include <iostream>
using namespace std;
class Deep {
public:
int* data;
Deep(int d) {
data = new int(d); // 动态分配内存
cout << "观察数据:" << endl;
cout << d << endl;
cout << *data << endl;
cout << "观察内存在构造函数中:" << endl;
cout << data << endl;
}
// 显式定义深拷贝的拷贝构造函数
Deep(const Deep& source) {
data = new int(*source.data); // 复制数据,而不是地址
cout << "深拷贝构造函数\n";
}
~Deep() {
delete data; // 释放内存
}
};
int main() {
Deep obj1(20);
Deep obj2 = obj1; // 深拷贝
cout << "观察内存在main函数obj2的data地址:" << endl;
cout << obj2.data << endl;
cout << "obj1 data: " << *obj1.data << ", obj2 data: " << *obj2.data << endl;
return 0;
}
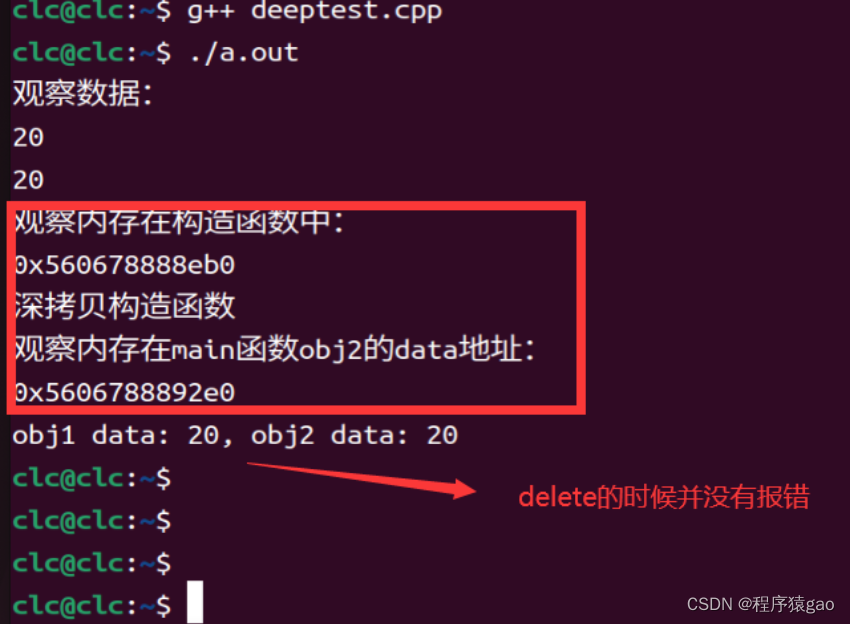
在这个例子中,obj2 是通过深拷贝 obj1 创建的。这意味着 obj1.data 和 obj2.data 指向不同的内存地址。每个对象有自己的内存副本,因此不会相互影响,避免了潜在的运行时错误。
 4. 规则三则
4. 规则三则
在 C++ 中,规则三则(Rule of Three)是一个面向对象编程原则,它涉及到类的拷贝控制。规则三则指出,如果你需要显式地定义或重载类的任何一个拷贝控制操作(拷贝构造函数、拷贝赋值运算符、析构函数),那么你几乎肯定需要显式地定义或重载所有三个。这是因为这三个功能通常都是用于管理动态分配的资源,比如在堆上分配的内存。
示例代码
#include <iostream>
#include <cstring>
class MyClass {
private:
char* buffer;
public:
// 构造函数
MyClass(const char* str) {
if (str) {
buffer = new char[strlen(str) + 1];
strcpy(buffer, str);
} else {
buffer = nullptr;
}
}
// 析构函数
~MyClass() {
delete[] buffer;
}
// 拷贝构造函数
MyClass(const MyClass& other) {
if (other.buffer) {
buffer = new char[strlen(other.buffer) + 1];
strcpy(buffer, other.buffer);
} else {
buffer = nullptr;
}
}
// 拷贝赋值运算符
MyClass& operator=(const MyClass& other) {
if (this != &other) {
delete[] buffer; // 首先删除当前对象的资源
if (other.buffer) {
buffer = new char[strlen(other.buffer) + 1];
strcpy(buffer, other.buffer);
} else {
buffer = nullptr;
}
}
return *this;
}
};
int main() {
MyClass obj1("Hello");
MyClass obj2 = obj1; // 调用拷贝构造函数
MyClass obj3("World");
obj3 = obj1; // 调用拷贝赋值运算符
return 0;
}
在这个例子中:
•构造函数为成员变量 buffer 分配内存,并复制给定的字符串。
•析构函数释放 buffer 所占用的内存,以避免内存泄露。
•拷贝构造函数创建一个新对象作为另一个现有对象的副本,并为其分配新的内存,以避免多个对象共享同一内存。
•拷贝赋值运算符更新对象时,首先释放原有资源,然后根据新对象的状态分配新资源。
这个类遵循规则三则,确保了动态分配资源的正确管理,避免了内存泄露和浅拷贝问题。
5.避免不必要的拷贝
避免不必要的拷贝是 C++ 程序设计中的一个重要原则,尤其是在处理大型对象或资源密集型对象时。使用引用(包括常量引用)和移动语义(C++11 引入)是实现这一目标的两种常见方法。下面是两个示例:
1. 使用引用传递对象
通过使用引用(尤其是常量引用)来传递对象,可以避免在函数调用时创建对象的副本。
#include <iostream>
#include <vector>
using namespace std;
class LargeObject {
// 假设这是一个占用大量内存的大型对象
};
void processLargeObject(const LargeObject& obj) {
// 处理对象,但不修改它
cout << "Processing object..." << endl;
}
int main() {
LargeObject myLargeObject;
processLargeObject(myLargeObject); // 通过引用传递,避免拷贝
return 0;
}
在这个例子中,processLargeObject 函数接受一个对 LargeObject 类型的常量引用,避免了在函数调用时复制整个 LargeObject。
2. 使用移动语义
C++11 引入了移动语义,允许资源(如动态分配的内存)的所有权从一个对象转移到另一个对象,这避免了不必要的拷贝。
#include <iostream>
#include <utility> // 对于 std::move
using namespace std;
class MovableObject {
public:
MovableObject() {
// 构造函数
}
MovableObject(const MovableObject& other) {
// 拷贝构造函数(可能很昂贵)
}
MovableObject(MovableObject&& other) noexcept {
// 移动构造函数(轻量级)
// 转移资源的所有权
}
MovableObject& operator=(MovableObject&& other) noexcept {
// 移动赋值运算符
// 转移资源的所有权
return *this;
}
};
MovableObject createObject() {
MovableObject obj;
return obj; // 返回时使用移动语义,而非拷贝
}
int main() {
MovableObject obj = createObject(); // 使用移动构造函数
return 0;
}
在这个例子中,MovableObject 类有一个移动构造函数和一个移动赋值运算符,它们允许对象的资源(如动态分配的内存)在赋值或返回时被“移动”而非复制。这减少了对资源的不必要拷贝,提高了效率。
通过这些方法,你可以在 C++ 程序中有效地减少不必要的对象拷贝,尤其是对于大型或资源密集型的对象。
6.拷贝构造函数的隐式调用
在 C++ 中,拷贝构造函数可能会在几种不明显的情况下被隐式调用。这种隐式调用通常发生在对象需要被复制时,但代码中并没有明显的赋值或构造函数调用。了解这些情况对于高效和正确地管理资源非常重要。下面是一些典型的隐式拷贝构造函数调用的例子:
1.作为函数参数传递(按值传递)
当对象作为函数参数按值传递时,会调用拷贝构造函数来创建参数的本地副本。
#include <iostream>
using namespace std;
class MyClass {
public:
MyClass() {}
MyClass(const MyClass &) {
cout << "拷贝构造函数被隐式调用" << endl;
}
};
void function(MyClass obj) {
// 对 obj 的操作
}
int main() {
MyClass myObject;
function(myObject); // 调用 function 时,拷贝构造函数被隐式调用
return 0;
}
2. 从函数返回对象(按值返回)
当函数返回一个对象时,拷贝构造函数会被用于创建返回值的副本。
MyClass function() {
MyClass tempObject;
return tempObject; // 返回时,拷贝构造函数被隐式调用
}
int main() {
MyClass myObject = function(); // 接收返回值时可能还会有一次拷贝(或移动)
return 0;
}
3. 初始化另一个对象
当用一个对象初始化另一个同类型的新对象时,会使用拷贝构造函数。
int main() {
MyClass obj1;
MyClass obj2 = obj1; // 初始化时,拷贝构造函数被隐式调用
return 0;
}
---------------------------------------------------------------------------------------------------------------------------------
在以上所有这些情况下,如果类包含资源管理(例如,动态内存分配),那么正确地实现拷贝构造函数是非常重要的,以确保资源的正确复制和管理,防止潜在的内存泄漏或其他问题。此外,随着 C++11 的引入,移动语义提供了对资源的高效管理方式,可以减少这些场景中的资源复制。
7.禁用拷贝构造函数
在 C++ 中,禁用拷贝构造函数是一种常用的做法,尤其是在设计那些不应该被复制的类时。这可以通过将拷贝构造函数声明为 private 或使用 C++11 引入的 delete 关键字来实现。这样做的目的是防止类的对象被拷贝,从而避免可能导致的问题,如资源重复释放、无意义的资源复制等。
使用 delete 关键字
在 C++11 及更高版本中,可以使用 delete 关键字明确指定不允许拷贝构造:
class NonCopyable {
public:
NonCopyable() = default; // 使用默认构造函数
// 禁用拷贝构造函数
NonCopyable(const NonCopyable&) = delete;
// 禁用拷贝赋值运算符
NonCopyable& operator=(const NonCopyable&) = delete;
};
int main() {
NonCopyable obj1;
// NonCopyable obj2 = obj1; // 编译错误,拷贝构造函数被禁用
return 0;
}
这种方法清晰明了,它向编译器和其他程序员直接表明该类的对象不能被拷贝。
使用 private 声明(C++98/03)
在 C++11 之前,常见的做法是将拷贝构造函数和拷贝赋值运算符声明为 private,并且不提供实现:
class NonCopyable {
private:
// 将拷贝构造函数和拷贝赋值运算符设为私有
NonCopyable(const NonCopyable&);
NonCopyable& operator=(const NonCopyable&);
public:
NonCopyable() {}
};
int main() {
NonCopyable obj1;
// NonCopyable obj2 = obj1; // 编译错误,因为无法访问私有的拷贝构造函数
return 0;
}
在这个例子中,任何尝试拷贝 NonCopyable 类型对象的操作都会导致编译错误,因为拷贝构造函数和拷贝赋值运算符是私有的,外部代码无法访问它们。
---------------------------------------------------------------------------------------------------------------------------------
通过这些方法,你可以确保你的类的对象不会被意外地拷贝,从而避免可能出现的资源管理相关的错误。
8.拷贝构造函数总结
三、使用初始化列表
在C++中,使用初始化列表来初始化类的字段是一种高效的初始化方式,尤其在构造函数中。初始化列表直接在对象的构造过程中初始化成员变量,而不是先创建成员变量后再赋值。这对于提高性能尤其重要,特别是在涉及到复杂对象或引用和常量成员的情况下。
初始化列表紧跟在构造函数参数列表后面,以冒号(:)开始,后跟一个或多个初始化表达式,每个表达式通常用逗号分隔。下面是使用初始化列表初始化字段的例子:
class MyClass {
private:
int a;
double b;
std::string c;
public:
// 使用初始化列表来初始化字段
MyClass(int x, double y, const std::string& z) : a(x), b(y), c(z) {
// 构造函数体
}
};
在这个例子中,MyClass 有三个成员变量:a(int 类型)、b(double 类型)和 c(std::string 类型)。当创建 MyClass 的一个实例时,我们通过构造函数传递三个参数,这些参数被用于通过初始化列表直接初始化成员变量。初始化列表 : a(x), b(y), c(z) 的意思是用 x 初始化 a,用 y 初始化 b,用 z 初始化 c。
初始化列表的优点包括:
•效率:对于非基本类型的对象,使用初始化列表比在构造函数体内赋值更高效,因为它避免了先默认构造然后再赋值的额外开销。
•必要性:对于引用类型和常量类型的成员变量,必须使用初始化列表,因为这些类型的成员变量在构造函数体内不能被赋值。
•顺序:成员变量的初始化顺序是按照它们在类中声明的顺序,而不是初始化列表中的顺序。
四、this关键字
在 C++ 中,this 关键字是一个指向调用对象的指针。它在成员函数内部使用,用于引用调用该函数的对象。使用 this 可以明确指出成员函数正在操作的是哪个对象的数据成员。下面是一个使用 Car 类来展示 this 关键字用法的示例:
#include <iostream>
#include <string>
using namespace std;
class Car {
private:
string brand;
int year;
public:
Car(string brand, int year) {
this->brand = brand;
this->year = year;
// cout << "构造函数中:" << endl;
// cout << this << endl;
}
void display() const {
cout << "Brand: " << this->brand << ", Year: " << this->year << endl;
// 也可以不使用 this->,直接写 brand 和 year
}
Car& setYear(int year) {
this->year = year; // 更新年份
return *this; // 返回调用对象的引用
}
};
int main()
{
Car car("宝马",2024);
car.display();
// 链式调用
car.setYear(2023).display();
// cout << "main函数中:" << endl;
// cout << &car << endl;
// Car car2("宝马",2024);
// cout << "main函数中:" << endl;
// cout << &car2 << endl;
return 0;
}
在这个例子中,Car 类的构造函数使用 this 指针来区分成员变量和构造函数参数。同样,setYear 成员函数使用 this 指针来返回调用该函数的对象的引用,这允许链式调用,如 myCar.setYear(2021).display();。在 main 函数中创建了 Car 类型的对象,并展示了如何使用这些成员函数。
五、new关键字
在C++中,new 关键字用于动态分配内存。它是C++中处理动态内存分配的主要工具之一,允许在程序运行时根据需要分配内存。
1.基本用法
a.分配单个对象
使用 new 可以在堆上动态分配一个对象。例如,new int 会分配一个 int 类型的空间,并返回一个指向该空间的指针。
int* ptr = new int; //C语言中,int *p = (int *)malloc(sizeof(int));
b.分配对象数组
new 也可以用来分配一个对象数组。例如,new int[10] 会分配一个包含10个整数的数组。
int* arr = new int[10]; //C语言中,int *arr = (int *)malloc(sizeof(int)*10);
c. 初始化
可以在 new 表达式中使用初始化。对于单个对象,可以使用构造函数的参数:
MyClass* obj = new MyClass(arg1, arg2);
d.与 delete 配对使用
使用 new 分配的内存必须显式地通过 delete(对于单个对象)或 delete[](对于数组)来释放,以避免内存泄露:
•释放单个对象:
delete ptr; // 释放 ptr 指向的对象
•释放数组:
delete[] arr; // 释放 arr 指向的数组
2.注意事项
•异常安全:如果 new 分配内存失败,它会抛出 std::bad_alloc 异常(除非使用了 nothrow 版本)。
•内存泄露:忘记释放使用 new 分配的内存会导致内存泄露。
•匹配使用 delete 和 delete[]:为避免未定义行为,使用 new 分配的单个对象应该使用 delete 释放,使用 new[] 分配的数组应该使用 delete[] 释放。
示例代码
class MyClass {
public:
MyClass() {
std::cout << "Object created" << std::endl;
}
};
int main() {
// 分配单个对象
MyClass* myObject = new MyClass();
// 分配对象数组
int* myArray = new int[5]{1, 2, 3, 4, 5};
// 使用对象和数组...
// 释放内存
delete myObject;
delete[] myArray;
return 0;
}
在这个例子中,new 被用来分配一个 MyClass 类型的对象和一个整数数组,然后使用 delete 和 delete[] 来释放内存。每个 new 都对应一个 delete,保证了动态分配的内存被适当管理。


















 2641
2641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











