







系列文章目录
(11条消息) 为什么大部分小数在计算机中是不精确的_芯轴的博客-优快云博客
(11条消息) java迭代器的实现原理_java迭代器底层实现原理_芯轴的博客-优快云博客
前言
Set:接口 在Collection的基础上再没有做功能的扩展(没有新的方法) 特点:没有索引值,不能重复
单列集合Set<E.>:接口:特点:没有索引值,不能重复
Set:接口 在Collection的基础上再没有做功能的扩展(没有新的方法) 特点:没有索引值,不能重复
常用实现类HashSet<E.>:无序,底层是哈希表
无序(新增顺序和取出顺序,不一定一致)。底层是哈希表:数组+链表+红黑树
package com.apesource.demo03.Set接口;
import java.util.HashSet;
import java.util.Set;
public class Test01 {
public static void main(String[] args) {
//多态
Set<String> set = new HashSet<>();
//添加元素
set.add("张三");
set.add("李四");
set.add("王五");
set.add("张三");
//获取长度
System.out.println(set.size());
System.out.println(set);
}
}
测试类接本天 Object 类代码***************重复值、不存储
package lianxi2.Set接口;
import java.util.HashSet;
import java.util.Set;
public class Test03 {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student("张三",20));
set.add(new Student("李四",21));
set.add(new Student("王五",22));
boolean b = set.add(new Student("张三",20));
System.out.println(b);//false
//获取长度
System.out.println(set.size());
System.out.println(set);
}
}
常用实现类LinkedHashSet<E.>:有序。哈希表+链表(保证顺序)
HashSet和LinkedHashSet不能重复的标准是什么:
两个对象,哈希值相同 && equals都相同,就被认为是同一个元素。 哈希值:通过调用hashCode方法得来的
自定义类型的对象,添加时两个对象成员变量的值相同,即认为是同一个元素:
则需要覆盖重写equals 和 hashCode方法
Object类
int hashCode();//可以理解为地址值 boolean equals(Object obj);比较的是地址值
package lianxi2.Set接口;
public class Student {
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
/*
* 成员变量的值相同,返回的哈希值就相同
* String类覆盖重写了hashCode方法,字符串的内容一致,则返回的哈希值一致。
*/
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
//按照快捷方式覆盖重写equals方法,比较的是两个对象的成员变量的值是否相同
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
常用实现类TreeSet<E.>:可排序,底层是红黑树。
TreeSet为例,只要比较结果是0就被认为是同一个元素,不新增。
构造方法:
public TreeSet();
public TreeSet(Comparator<E.>)
package lianxi2.Set接口;
import java.util.TreeSet;
public class Test04 {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(10);
set.add(20);
set.add(13);
set.add(18);
set.add(28);
System.out.println(set);
}
}
使用TreeSet的时候要注意:1.泛型必须是Comparable类型。
package lianxi2.Set接口;
import java.util.TreeSet;
public class Test05 {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>();
set.add(new Person("张三",20));
set.add(new Person("张三疯了",2000));
set.add(new Person("张三丰",200));
System.out.println(set);
}
}
class Person implements Comparable<Person>{
private String name;
private int age;
/*
* 写明比较的规则:this和参数对象进行比较
* */
@Override
public int compareTo(Person p) {
/*
* 升序:当前对象-参数对象
* 降序:参数对象-当前对象
* */
return p.age-this.age;
}
}
2.如果不是这个Comparable类型,创建一个Comparator类型的对象
则需要创建一个Comparator类型的对象,传入TreeSet的构造方法中。
package lianxi2.Set接口;
import java.util.Comparator;
import java.util.TreeSet;
public class Test06 {
public static void main(String[] args) {
//创建议个Comparator类型的对象,通过匿名内部类的方式
Comparator<Car> c = new Comparator<Car>() {
@Override
public int compare(Car o1, Car o2) {
/*
* 升序:参数1-参数2
* 降序:参数2-参数1
* */
return o1.getBrand().length()-o2.getBrand().length();
}
};
TreeSet<Car> set = new TreeSet<>(c);
set.add(new Car("理想L9","银色"));
set.add(new Car("比亚迪*汉武大帝","红"));
set.add(new Car("沃尔沃s90","白"));
System.out.println(set);
}
}
claSS Car{
private String name;
private String color;
}
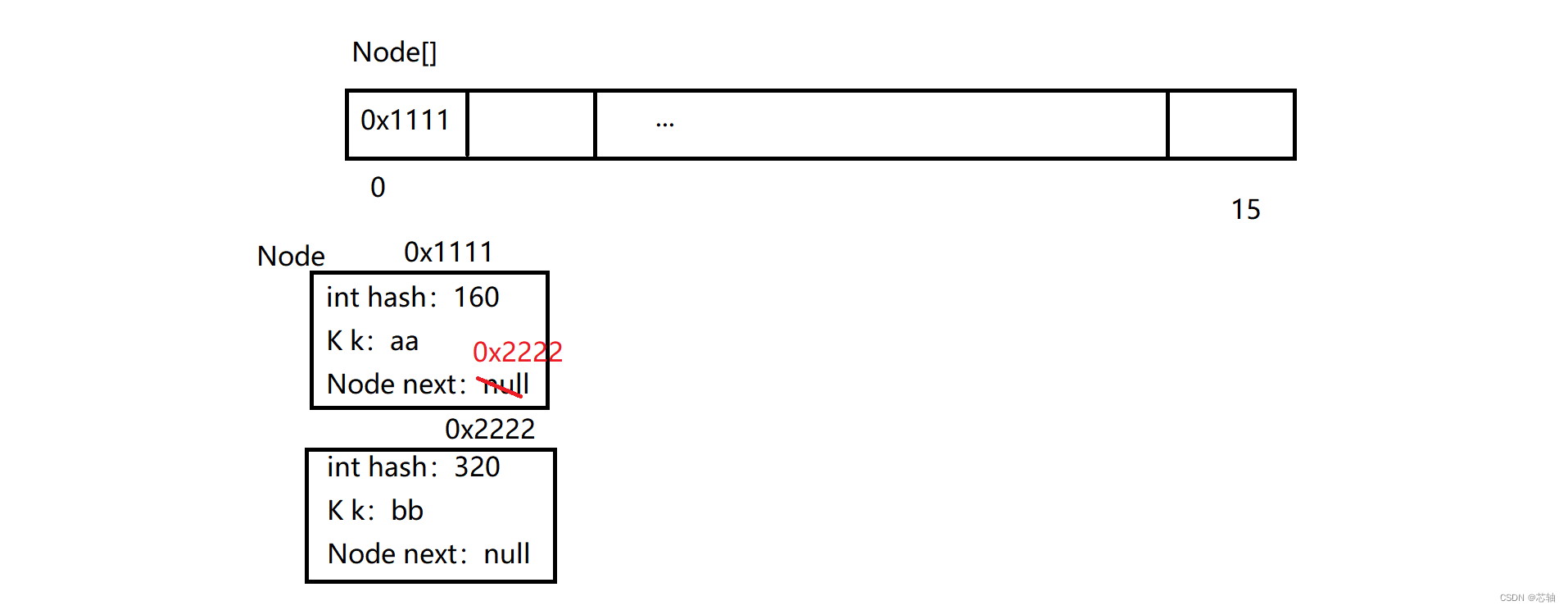
哈希表的原理
Set的底层就是Map
HashSet为例:
哈希表:数组+链表+红黑树
什么类型的数组:java.util.HashMap$Node
数组的长度是多少:通过无参数构造方法:长度是16
通过无参数构造方法:长度是16
通过有参数的构造方法:长度是>=capacity的最进行2的次方的值
怎么扩容:新容量 = 旧容量*2;
什么情况下会扩容: a. 当同一索引值下元素个数>8 && 数组长度<64 b. 当数组的格子的占有率达到了0.75的时候会扩容。 新容量 = 旧容量*2;//newCap = oldCap << 1
怎么体现链表:Node类的设计就是一个单项链表的设计
怎么体现红黑树:个数>8&&长度>=64时链表结构转换成红黑树
当同一索引值下元素个数>8 && 数组长度>=64 则会把该索引值下的链表结构是转换成红黑树
新增的过程:
1.计算新增元素的哈希值
2.如果是第一次新增,创建一个长度是16的java.util.HashMap$Node类型的数组
3.通过 哈希值%数组长度,来计算新增元素的索引值位置
如果该位置没有元素:则创建Node类型的对象,添加在该位置 如果该位置有元素:判断新增元素和该位置的元素是否相同 如果相同:不新增 如果不相同:新增,新增元素挂载该索引值链表的最末尾
判断两个元素是否重复的标准:简单来说就是 哈希值相同 && equals相同 就认为是同一个元素。 p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))
HashSet类:
构造方法: public HashSet(); public HashSet(int capacity);//实际数组的容量是一个>=capacity的最进行2的次方的值 public HashSet(int capacity,float loadFactor);//默认的加载因子是0.75,可以修改(不建议)
总结
两个对象,哈希值相同 && equals都相同,就被认为是同一个元素。 哈希值:通过调用hashCode方法得来的
自定义类型的对象,添加时两个对象成员变量的值相同,即认为是同一个元素:
则需要覆盖重写equals 和 hashCode方法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











