






集合框架体系图
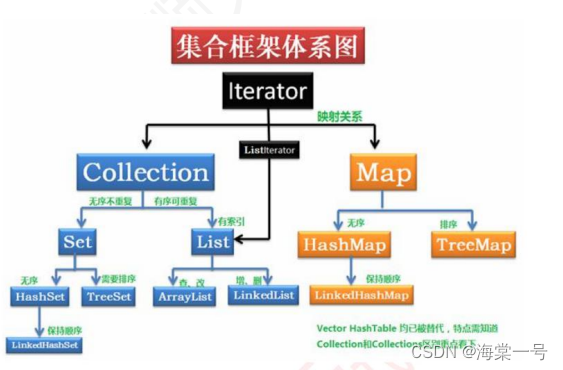
该图片来源于互联网,博主实在难得画
我们可以从实现接口进行出发
Connection接口:
List:有序、可重复
- ArrayList:
- 底层数据结构是数组,查询快,增删慢
- 线程不安全、效率高
- Vector
- 底层数据结构是数组,查询快,增删慢
- 线程安全,但是效率低,已经舍弃
- LinkedList
- 底层结构是双向链表,查询慢,增删快
- 线程不安全,效率高
Set:无序,唯一
- HashSet
- 底层数据结构是哈希表。(无序,唯一)
- 如何来保证元素唯一性?
- 依赖两个方法:hashCode()和equals()
- LinkedHashSet
- 底层数据结构是链表和哈希表(FIFO插入有序,唯一)
- 由链表保证元素有序
- 由哈希表保证元素唯一
- 底层数据结构是链表和哈希表(FIFO插入有序,唯一)
- TreeSet
- 底层数据结构是红黑树。(唯一,有序)
- 如何保证元素排序的呢?
- 自然排序
- 比较器排序
- 如何保证元素唯一性的呢?
- 根据比较的返回值是否是0来决定
- 如何保证元素排序的呢?
- 底层数据结构是红黑树。(唯一,有序)
Map接口:
HashMap:基于hash表的Map接口实现,非线程安全,高效,支持null值和null建,线程不安全
LinkedHashMap:线程不安全,是HashMap的一个子类,有序:保存了记录的插入顺序
HashTable:线程安全,低效,不支持null值和null建
TreeMap:能够把它保存的记录根据键排序,默认是键值的升序排序,线程不安全
2.5Hashmap 的底层原理(高薪常问)
JDK1.8之前的实现方式 数组+链表
JDK1.8之后:数组+链表 或者由 数组+链表或者数组+红黑树 实现,目的是提高查找效率
- 节点数>=8 数组+红黑树
- 节点数<=6数组+链表
HashMap结构
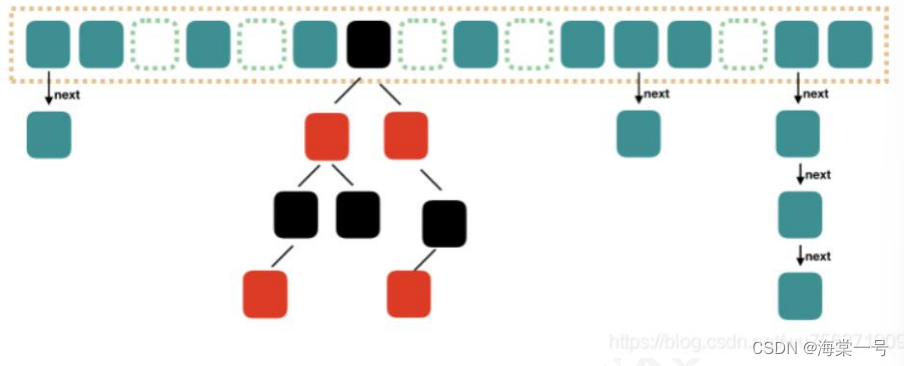 图片来自互联网
图片来自互联网
- JDK8数组+链表 OR 数组+红黑树 实现,当链表中的元素超过8个以后,会将链表转换为红黑树,当红黑树节点小于等于 6时又会退化为链表。
- 当new HashMap():底层没有创建数组,首次调用put()方式时,底层创建长度为16的数组,jdk8底层的数组是:Node[](节点数组)存储引用关系,而非Entry[](存储键值对),用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍,专业术语叫做扩容,在做扩容的时候会生成一个新的数组,原来的所有数据需要重新计算哈希码值分配到新的数组,所以扩容的操作非常消耗性能
- 默认的负载因子大小为0.75,数组大小为16。也就是说,默认情况下,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍
- 在我们java中任何对象都有hashcode,hash算法就是通过hashcode与自己进行向右位移16的异或运算。这样做是为了计算出来的hash值足够随机,足够分散,还有产生的数组下标足够随机。
map.put(k,v)实现原理
- 首先将k,v封装到Node对象当中(节点)。
- 先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的小标。
- 小标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果其中有一个equals返回了true,那么这个节点的value将会被覆盖;如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。
map.get(k)实现原理
- 先调用k的hashcode()方法得到k的哈希值,然后通过哈希算法转换成数组的小标
- 在通过数组小标快速定位到某个位置。
- 重点理解:如果这个位置上面什么也没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数k和单向链表上的每一个节点k进行equals,如果所有equals方法都返回false,则get方法返回null。如果某个节点返回true,就代表这个节点就是我们要找的节点,返回这个节点的value
Hash冲突
不同对象经过哈希函数得到的哈希值是一致的,这就会产生hash冲突。当单线链表达到一定长度后效率会非常低
注意:链表长度大于8的时候,就会将链表转换为红黑树,提高查询效率
Hashmap 和 hashtable ConcurrentHashMap 区别
HashMap和HashTable的区别:
- HashMap是非线程安全的,HashTable是线程安全的。
- HashMap的键和值都允许有null值存在,而HashTable则不行。
- HashMap线程不安全,HashTable线程安全,但是因为线程安全的原因,HashMap效率更高。
- HashTable是同步的,HashMap不是。因此,HashMap更适合于单线程环境,而HashTable适合于多线程环境,一般现在是不建议使用HashTable,
- ①是因为HashTable是遗留类,内部实现很多没有优化,并且冗余。
- ②即使在多线程环境下,现在也有同步的ConcurrentHashMap替代。
HashTable和ConcurrentHashMap区别:
HashTable使用的是Synchronize关键字修饰,ConcurrentHashMap是JDK1.7使用了锁分段技术来保证线程安全的。JDK1.8ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。
ConcurrentHashMap底层是数组+链表/红黑树
HashTable底层是数组加链表
ConcurrentHashMap中的synchronized只锁定当前链表或红黑树的首节点,只要hash不冲突,就不会产生并发,效率有提示N倍
为什么ConcurrentHashMap优于HashTable?
- ConcurrentHashMap 在JDK1.8以后采用的是CAS 乐观锁和synchronized悲观锁,而HashTable采用的是Synchronize悲观锁。其中ConcurrentHashMap的synchronized
- 乐观锁的范围小于悲观锁,尤其是读多写少的场景下,并发性能优于悲观锁。

















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









