







帮忙点赞评论一番,以满足我的虚荣心[狗头.jpg]
目录
1 决策树分类模型原理
决策树分类模型是机器学习中一种常用的分类算法,它通过构建一个树形结构来实现对数据集的分类。这种模型的核心思想是将数据集按照其属性特征进行递归划分,直到满足一定的终止条件,形成一棵决策树。决策树由结点和有向边组成,其中结点分为内部结点和叶结点两种类型,内部结点表示一个特征或属性,而叶结点则表示一个类别。决策树可以被视为一系列if-then规则的集合,从根节点到叶结点的每一条路径都构建了一条规则,路径上的内部结点特征对应规则的条件,叶结点的类别对应规则的结论。
1.1 基本原理
决策树算法的主要目的是通过选择最优的属性来对数据集进行划分,以达到最佳的分类效果。这个最优属性的选择通常依赖于一些度量标准,如信息增益、基尼系数等。
1.1.1 信息增益(Information Gain)
信息增益是决策树算法中用于选择最优划分属性的一个重要标准。它基于信息熵(Entropy)的概念,信息熵是度量样本集合纯度最常用的一种指标。假设样本集合D中第k类样本所占的比例为(k=1,2,...,N),则D的信息熵定义为:
信息熵的值越小,表示D的纯度越高。给定属性A,我们可以计算条件熵H(D∣A),即在属性A的条件下,数据集D的经验条件熵。条件熵的计算公式为:
其中,表示在属性A上取值为v的样本子集,v是属性A的可能取值个数。
信息增益IG(D,A)则是数据集D的经验熵H(D)与条件熵H(D∣A)之差,即:
信息增益越大,表示使用属性A进行划分所获得的纯度提升越大,因此,选择信息增益最大的属性作为最优划分属性。
1.1.2 基尼系数(Gini Index)
基尼系数也是决策树算法中常用的一个划分标准,尤其在CART(Classification and Regression Trees)算法中广泛使用。基尼系数用于度量数据集D的纯度,其定义如下:
其中,∣Y∣表示数据集D中不同类别的个数,pk表示数据集D中属于第k个类别的样本占总样本数的比例。基尼系数的值越小,表示数据集D的纯度越高。
对于属性A,我们可以计算基尼系数GiniA(D),即按照属性A的不同取值对数据集D进行划分后的基尼系数加权和:
选择基尼系数最小的属性作为最优划分属性。
1.2 决策树生成算法
决策树的生成算法主要包括特征选择、决策树的生成和决策树的修剪三个步骤。常用的算法有ID3、C4.5和CART。
1. 2.1 ID3算法
ID3算法是最早的决策树生成算法之一,它使用信息增益作为选择最优划分属性的标准。ID3算法的主要步骤如下:
- 初始化:从根节点开始,数据集为D。
- 特征选择:计算数据集D中每个属性的信息增益,选择信息增益最大的属性作为最优划分属性。
- 划分数据集:根据最优划分属性的不同取值,将数据集D划分为若干个子集。
- 递归生成:对每个子集递归执行步骤2和步骤3,直到满足停止条件(如子集只包含一类样本或达到预设的树深度)。
- 生成叶结点:如果当前子集只包含一类样本,则生成一个叶结点,并将其类别标记为该样本的类别。
1.2.2 C4.5算法
C4.5算法在ID3算法的基础上,引入了信息增益比(Gain Ratio)作为选择最优划分属性的标准。信息增益比克服了信息增益在选择属性时偏向于选择取值数目较多属性的不足。
1.2.2.1信息增益比的计算
信息增益比的计算首先要求出属性A的固有值(Intrinsic Value)或称为分裂信息(Split Information):
其中,Dv表示在属性A上取值为v的样本子集,V是属性A的可能取值个数。然后,信息增益比GainRatio(D,A)定义为信息增益IG(D,A)与属性A的固有值SplitInfo(D,A)之比:
注意,如果某个属性A的取值数目较多,则SplitInfo(D,A)的值会较大,导致GainRatio(D,A)的值较小。这样,信息增益比就在一定程度上避免了信息增益的偏好问题。
1.2.2.2 C4.5算法的主要步骤
C4.5算法的主要步骤与ID3算法类似,但在特征选择阶段使用信息增益比代替信息增益:
- 初始化:从根节点开始,数据集为D。
- 特征选择:计算数据集D中每个属性的信息增益比,选择信息增益比最大的属性作为最优划分属性。
- 划分数据集:根据最优划分属性的不同取值,将数据集D划分为若干个子集。
- 递归生成:对每个子集递归执行步骤2和步骤3,直到满足停止条件(如子集只包含一类样本、达到预设的树深度或信息增益比小于预设阈值)。
- 生成叶结点:如果当前子集只包含一类样本,则生成一个叶结点,并将其类别标记为该样本的类别。
C4.5算法还通过剪枝技术来避免过拟合问题,提高模型的泛化能力。
1.2.3 CART算法
CART(Classification and Regression Trees)算法是一种既可以用于分类也可以用于回归的决策树算法。在分类任务中,CART使用基尼系数作为选择最优划分属性的标准。
CART算法的主要步骤(分类任务):
- 初始化:从根节点开始,数据集为D。
- 特征选择:计算数据集D中每个属性的基尼系数,选择基尼系数最小的属性作为最优划分属性。
- 划分数据集:根据最优划分属性的不同取值,将数据集D划分为若干个子集。
- 递归生成:对每个子集递归执行步骤2和步骤3,直到满足停止条件(如子集只包含一类样本、达到预设的树深度或基尼系数减小量小于预设阈值)。
- 生成叶结点:如果当前子集只包含一类样本,则生成一个叶结点,并将其类别标记为该样本的类别。
CART算法生成的决策树是二叉树,即每次划分都是将数据集划分为两个子集。对于具有多个取值的属性,CART算法通常采用某种策略(如使用属性值的某个中位数或众数)来将属性值划分为两个子集。
1.3 决策树剪枝
剪枝是决策树学习中防止过拟合、提高模型泛化能力的重要手段。剪枝通过简化决策树的结构来减少模型的复杂度,使得模型在未知数据上的表现更加稳定。
1.3.1 后剪枝(Post-pruning)
后剪枝是一种在决策树完全生长之后,再对其进行剪枝的方法。其步骤如下:
- 从底部开始:首先,将决策树中最底层的非叶结点视为候选结点。
- 评估剪枝效果:对于每个候选结点,尝试将其替换为其子树中最常见的类别(即将其转化为叶结点),并评估这一剪枝操作对模型性能的影响。这通常通过交叉验证在验证集上进行,比较剪枝前后的误差率或准确率等指标。
- 剪枝决策:如果剪枝操作能够提升模型的泛化能力(即验证集上的性能有所提升),则进行剪枝。
- 递归剪枝:将剪枝后的结点视为新的候选结点,重复步骤2和步骤3,直到无法进一步提升模型性能为止。
后剪枝的优点在于其能够保留更多的分支,因此可能具有更好的分类效果。然而,其计算量相对较大,因为需要对每个非叶结点都进行剪枝评估。
1.3.2预剪枝(Pre-pruning)
预剪枝则是在决策树生成过程中,提前停止树的生长,从而避免生成过于复杂的树结构。其策略包括:
- 设置最大深度:在生成决策树之前,指定树的最大深度。当树达到这个深度时,停止生长。
- 限制节点样本数:如果某个节点的样本数少于预设的阈值,则停止该节点的进一步划分。
- 限制信息增益(或基尼系数减小量):如果某个节点的划分带来的信息增益(或基尼系数减小量)小于预设的阈值,则不进行划分,该节点成为叶结点。
预剪枝的优点在于其计算量相对较小,因为决策树在生成过程中就进行了剪枝。然而,预剪枝可能导致模型欠拟合,因为某些可能重要的分支可能由于未达到剪枝条件而被提前终止。
1.3.3 剪枝的权衡
剪枝是一个权衡过程,需要在模型的复杂度和泛化能力之间找到最佳平衡点。过少的剪枝可能导致模型过拟合,即在训练集上表现良好但在测试集上表现不佳;而过多的剪枝则可能导致模型欠拟合,即模型过于简单,无法充分捕捉数据中的复杂关系。
在实际应用中,可以通过交叉验证等方法来评估不同剪枝策略对模型性能的影响,从而选择最合适的剪枝方法。此外,还可以结合使用预剪枝和后剪枝技术,以进一步提高模型的性能。
1.4 总结
决策树分类模型通过构建树形结构来实现对数据集的分类。其核心在于选择最优的划分属性来递归地划分数据集,直到满足一定的停止条件。在生成决策树的过程中,需要采用信息增益、基尼系数等度量标准来选择最优属性。为了防止过拟合,还需要对生成的决策树进行剪枝处理。剪枝方法包括预剪枝和后剪枝两种,各有优缺点,需要根据实际情况选择使用。通过合理的剪枝策略,可以提高决策树模型的泛化能力,使其在实际应用中更加有效。
2 代码
2.1 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from sklearn.model_selection import RandomizedSearchCV
from skopt import BayesSearchCV
from skopt.space import Real, Categorical, Integer
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
import seaborn as sns
# 忽略Matplotlib的警告(可选)
import warnings
warnings.filterwarnings("ignore")
# 设置中文显示和负号正常显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False2.2 加载数据与数据预处理
# 加载数据
df = pd.read_excel('目标客户体验数据.xlsx')
df.fillna(0, inplace=True)
df.dtypes2.3 划分数据集
# 假设 'isorno' 是目标列,其余为特征
X = df.iloc[:, :-1] # 所有行,除了最后一列
y = df.iloc[:, -1] # 所有行的最后一列
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42) 2.4 训练模型
# 创建决策树模型
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train) 2.5 可视化决策树
2.5.1 matplotlob库
# 可视化决策树
plt.figure(figsize=(20,10))
plot_tree(clf, filled=True, feature_names=X_train.columns, class_names=['No', 'Yes'], rounded=True)
plt.show()
可视化结果如图5-1所示:
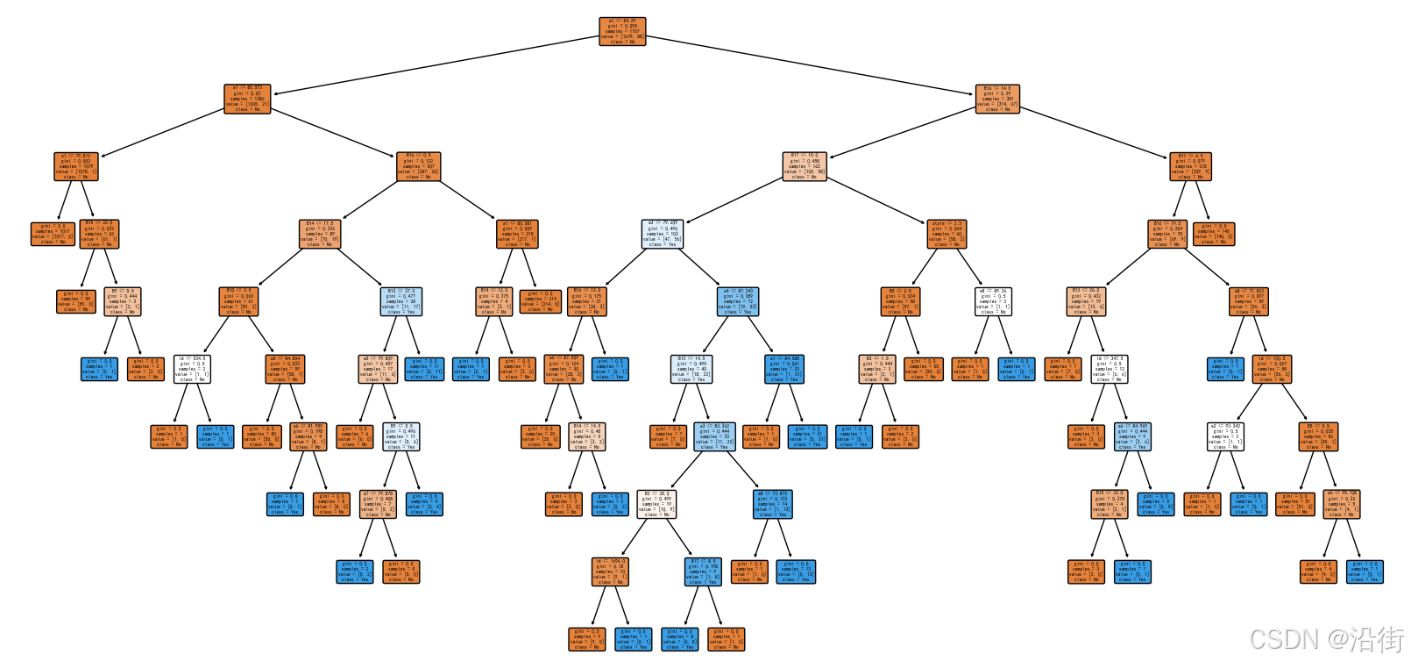
图5-1 决策树树状图
2.5.2 graph库
使用graph库可能会有报错:未安装graph库,安装方法可以参考别人的贴子。
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import graphviz
feature_names = ['id', 'style', 'a1', 'a2', 'a3', 'a4', 'a5', 'a6', 'a7', 'a8', 'B1',
'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8', 'B9', 'B10', 'B11', 'B12',
'B13', 'B14', 'B15', 'B16', 'B17'] # 获取特征名
target_names = ['0','1'] # 获取类别名
# 导出决策树为 .dot 文件(这里我们直接渲染,不保存到文件)
dot_data = export_graphviz(clf, out_file=None,
feature_names=feature_names,
class_names=target_names,
filled=True, rounded=True,
special_characters=True)
# 使用 graphviz 渲染 .dot 数据
graph = graphviz.Source(dot_data)
# 如果你在 Jupyter Notebook 中,可以直接显示图形
graph
graph.render("decision_tree", format="png")可视化结果如图5-2所示:
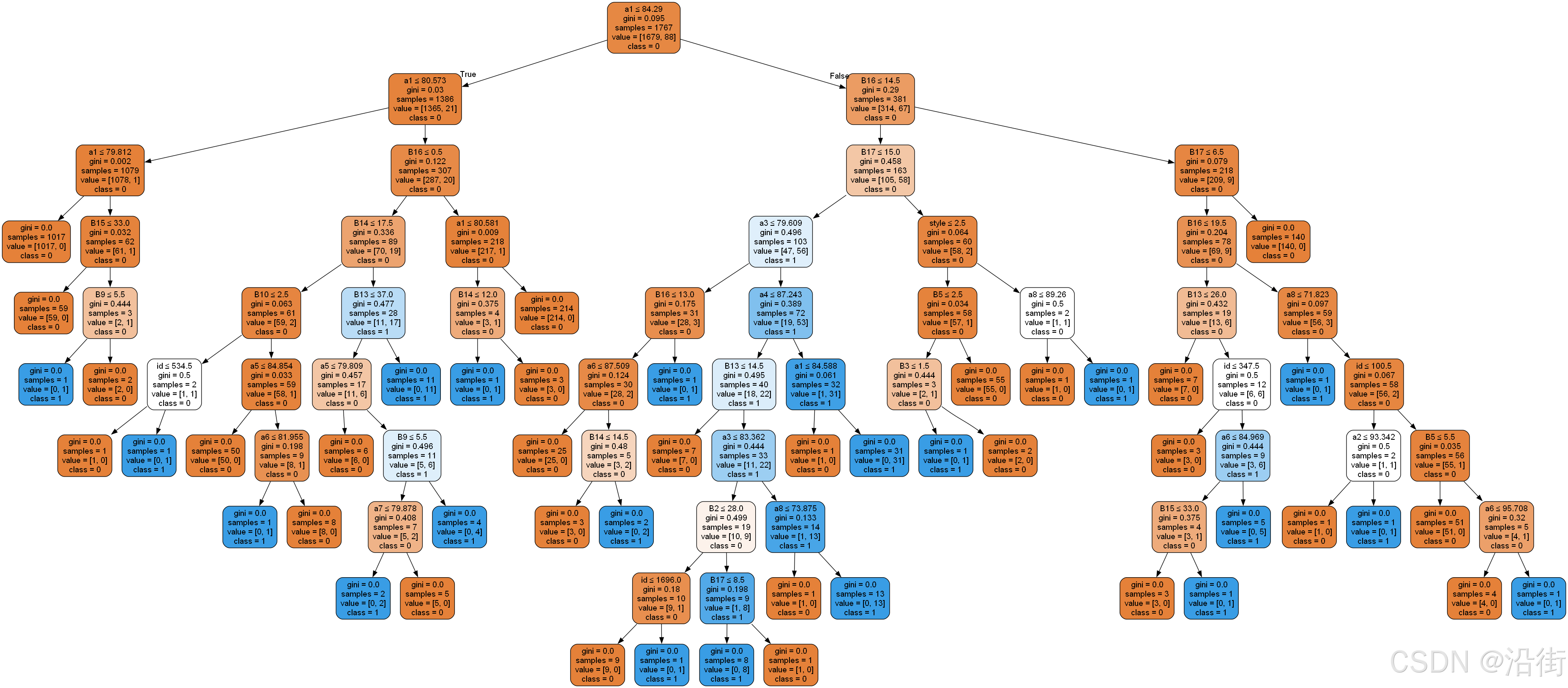
图5-2 决策树树状图
2.6 预测
# 预测并评估
y_pred = clf.predict(X_test)
2.7模型评估
2.7.1 模型评估报告
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred)) [[182 4]
[ 4 7]]
precision recall f1-score support
0 0.98 0.98 0.98 186
1 0.64 0.64 0.64 11
accuracy 0.96 197
macro avg 0.81 0.81 0.81 197
weighted avg 0.96 0.96 0.96 197
2.7.2 K折交叉验证
from sklearn.model_selection import cross_validate, KFold
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt
# 设置 k_values
k_values = range(2, 21) # 从 2 开始,因为 KFold 需要至少 2 个折叠
# 用于存储结果的列表
accuracies = []
recalls = []
f1_scores = []
for k in k_values:
kf = KFold(n_splits=k, shuffle=True, random_state=42)
results = cross_validate(clf, X, y, cv=kf, scoring=['accuracy', 'recall', 'f1'], return_train_score=False)
accuracies.append(results['test_accuracy'].mean())
recalls.append(results['test_recall'].mean())
f1_scores.append(results['test_f1'].mean())
# 找到每个列表中的最大值及其索引
max_acc_idx = accuracies.index(max(accuracies))
max_recall_idx = recalls.index(max(recalls))
max_f1_idx = f1_scores.index(max(f1_scores)) # 绘制图形
plt.figure(figsize=(12, 6))
# 绘制准确率
plt.subplot(1, 3, 1)
plt.plot(k_values, accuracies, color='black',marker='o')
plt.xlabel('Number of folds')
plt.ylabel('Average Accuracy')
plt.title('Accuracy vs. Number of Folds')
plt.xticks(np.arange(0, 21,1))
plt.grid(True)
plt.annotate(f'X: {max_acc_idx:.0f}', (k_values[max_acc_idx], max(accuracies)), textcoords="offset points", xytext=(-15,7), ha='center')
plt.annotate(f'Max: {max(accuracies):.4f}', (k_values[max_acc_idx], max(accuracies)), textcoords="offset points", xytext=(30,7), ha='center')
plt.axhline(y=max(accuracies), color='r', linestyle='--')
plt.axvline(x=k_values[max_acc_idx], color='deepskyblue', linestyle='--')
# 绘制召回率
plt.subplot(1, 3, 2)
plt.plot(k_values, recalls, color='orange', marker='o')
plt.xlabel('Number of folds')
plt.ylabel('Average Recall')
plt.title('Recall vs. Number of Folds')
plt.xticks(np.arange(0, 21, 1))
plt.grid(True)
plt.annotate(f'X: {max_recall_idx:.0f}', (k_values[max_recall_idx], max(recalls)), textcoords="offset points", xytext=(-15,7), ha='center')
plt.annotate(f'Max: {max(recalls):.4f}', (k_values[max_recall_idx], max(recalls)), textcoords="offset points", xytext=(30,7), ha='center')
plt.axhline(y=max(recalls), color='r', linestyle='--')
plt.axvline(x=k_values[max_recall_idx], color='deepskyblue', linestyle='--')
# 绘制 F1 分数
plt.subplot(1, 3, 3)
plt.plot(k_values, f1_scores, color='g', marker='o')
plt.xlabel('Number of folds')
plt.ylabel('Average F1 Score')
plt.title('F1 Score vs. Number of Folds')
plt.xticks(np.arange(0, 21, 1))
plt.grid(True)
plt.annotate(f'X: {max_f1_idx:.0f}', (k_values[max_acc_idx], max(f1_scores)), textcoords="offset points", xytext=(-15,7), ha='center')
plt.annotate(f'Max: {max(f1_scores):.4f}', (k_values[max_f1_idx], max(f1_scores)), textcoords="offset points", xytext=(30,7), ha='center')
plt.axhline(y=max(f1_scores), color='r', linestyle='--')
plt.axvline(x=k_values[max_f1_idx], color='deepskyblue', linestyle='--')
plt.tight_layout() # 调整子图参数, 使之填充整个图像区域
plt.show()可视化结果如图7-2所示:
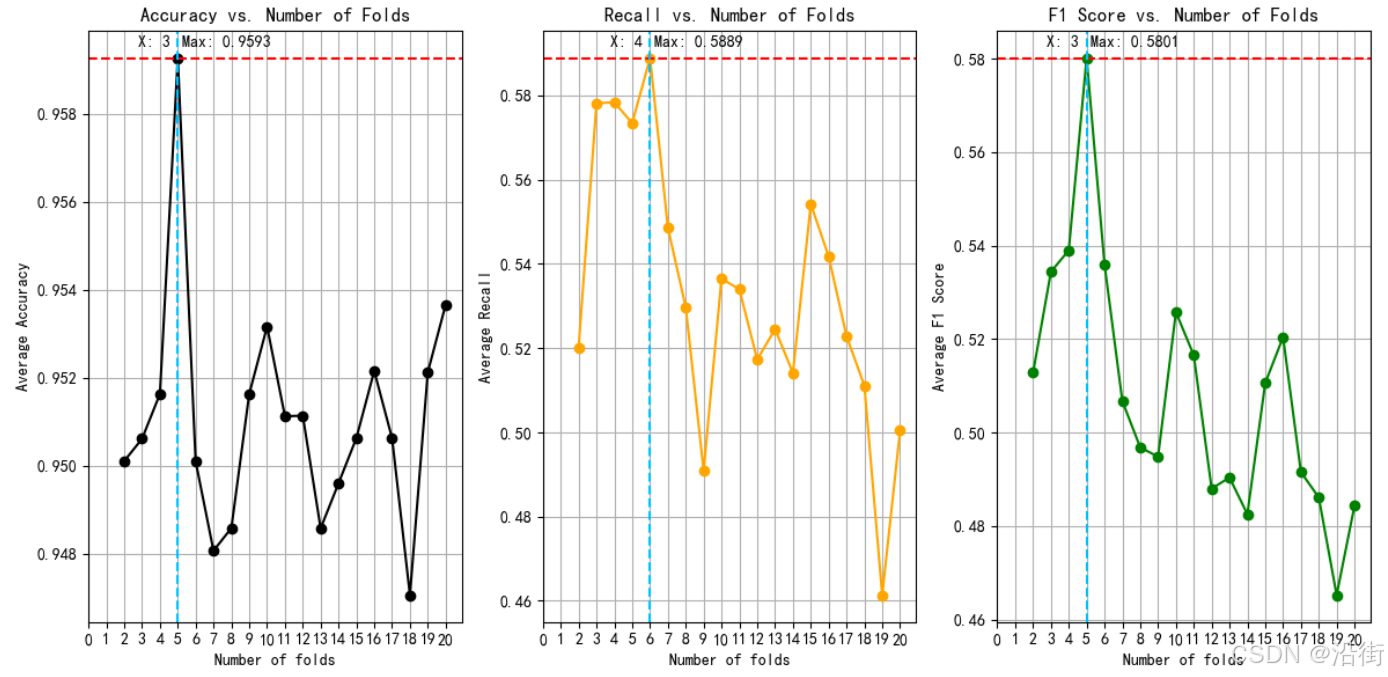
图7-2 不同K值模型性能对比


















 5654
5654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









