






跟着“莫烦python”记录Sarsa学习
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
视频链接:
https://www.bilibili.com/video/BV13W411Y75P?spm_id_from=333.788.videopod.episodes&vd_source=2613f45f05cdff9eb69129d6b00e37a2&p=10
代码链接:
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/3_Sarsa_maze
动作选择- ε-贪心策略

动作选择- Softmax 策略

和QLearning函数有一点不同,即更新策略
Q-learning的目标是通过学习和更新这些Q值,最终找到一个最优的策略,使得在每个状态下都能选择一个最优的动作,从而获得最大的长期奖励。
(这与Sarsa的思想略有不同,QLearning每次都要选最优解,不基于当前策略,而Sarsa还会基于当前的策略,选择最合适的解)
举个非常生动的例子
小刚和小明在上了大学之后,励志要学好高数,拿到高绩点。
但是他俩想法不同,小刚觉得每一节课都要非常认真的听讲,争取每节课都能学会新知识。
然而小明觉的是根据自己的进度和掌握程度来决定课上是听老师讲课,还是在b站听xx老师的网课。
很明显,小刚是QLearning算法,而小明则是Sarsa算法。
1. 策略类型
Q-learning 是 离策略(off-policy)算法。Q-learning 在更新 Q 值时,
使用的是下一个状态中 最大 Q 值的动作,而不关心下一个动作是如何选择的。
SARSA 是 基于策略(on-policy)算法。SARSA 在更新 Q 值时,
使用的是 实际选择的动作,因此它的学习过程是依赖于当前策略的。
2.更新规则
在 Q-learning 中,更新 Q 值时,选择下一个状态 s',
这种更新方式与当前策略无关,因此是 离策略的。
在 SARSA 中,更新 Q 值时,使用的是 实际选择的动作 a',
即智能体根据当前策略选择的动作来更新 Q 值,因此它是 基于策略的。
Sarsa(λ )
SARSA(λ) 是一种强化学习算法,属于 时序差分(Temporal Difference, TD) 学习方法,并且是基于策略的算法(on-policy)。它通过引入 资格迹(eligibility traces) 来改进标准的 SARSA 算法,使得算法能够更高效地学习,并且能够加速收敛。
SARSA(λ) 是在 SARSA 的基础上引入了 资格迹 的概念,资格迹的作用是 为状态-动作对分配一个记忆权重,使得更新不仅依赖于当前的状态-动作对,还考虑到过去一段时间内的状态-动作对对当前学习的影响。
资格迹 记录了一个状态-动作对最近被访问的强度,并在每次更新时按衰减因子 𝜆来调整。
λ 是一个 衰减因子,介于 0 和 1 之间,它控制着过去经验的影响范围。较大的 λ 值使得更长时间的历史经验对当前学习产生影响,较小的 λ 值则使得历史经验的影响变小。
时序差分误差:
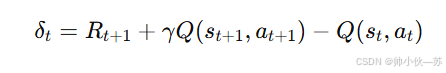
时序差分方程TD(0):
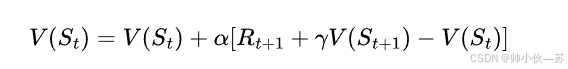


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









