






跟着“莫烦python”记录QLearning学习
视频链接:
https://www.bilibili.com/video/av16921335?spm_id_from=333.788.player.switch&aid=16921335&vd_source=2613f45f05cdff9eb69129d6b00e37a2&p=8
代码链接:
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/2_Q_Learning_maze
## 遇到的问题:
1.需要python的环境在3.7及以上
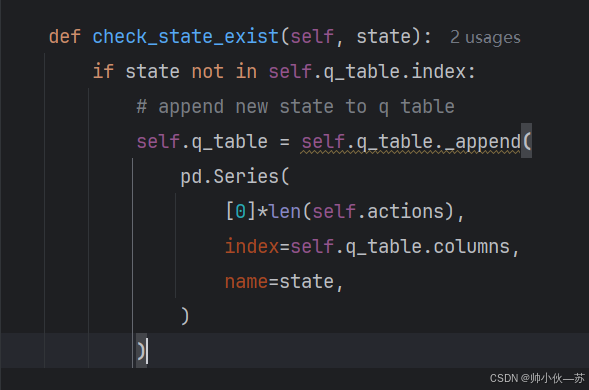
2.当出现'DataFrame' object has no attribute 'append'. Did you mean: '_append'?问题时
需要去修改一下代码,将append修改为_append
具体位置为RL_brain.py的check_state_exist 函数,如下图所示。
3.当出现某个包没有下载时,直接pip install xxx
例如:No module named 'pandas'
收获
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list 定义动作
self.lr = learning_rate #α
self.gamma = reward_decay #β
self.epsilon = e_greedy #ɛ
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
QLearningTable中的__init__是定义各种数据,action-α,lr-β(学习速率),rpsilon-ɛ(参数)
2.
def choose_action(self, observation):
self.check_state_exist(observation) #检验动作是否在q_table当中
# action selection
if np.random.uniform() < self.epsilon:
# choose best action选择最优结果
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
#打乱action元素位置
else:
# choose random action随机选择
action = np.random.choice(self.actions)
return action
QLearningTable中的choose_action是用来选择动作,需要提前来检验一下动作是否在q_table中。
根据随机生成的随机数和参数是最优解还是随机选择
结果
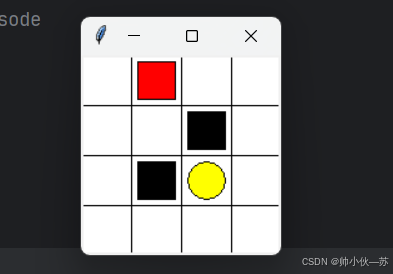
可以正常运行
后续
对QLearning学习的思考:
1.Q-learning的核心是通过不断更新Q值来逼近最优策略。
这里的Q值(动作-价值函数)即是对当前状态下采取某种动作所能得到的预期累计奖励
Q值是一个状态-动作对的评估
s 是当前状态
a 是当前状态下的某个动作
Q(s,a) 是从状态 𝑠出发,采取动作 a 后,能够获得的预期总奖励
2.Q-learning的目标是通过学习和更新这些Q值,最终找到一个最优的策略,使得在每个状态下都能选择一个最优的动作,从而获得最大的长期奖励。
(这与Sarsa的思想略有不同,QLearning每次都要选最优解,不基于当前策略,而Sarsa还会基于当前的策略,选择最合适的解)
举个非常生动的例子
小刚和小明在上了大学之后,励志要学好高数,拿到高绩点。
但是他俩想法不同,小刚觉得每一节课都要非常认真的听讲,争取每节课都能学会新知识。
然而小明觉的是根据自己的进度和掌握程度来决定课上是听老师讲课,还是在b站听xx老师的网课。
很明显,小刚是QLearning算法,而小明则是Sarsa算法。
3.Q-learning是一个无模型(model-free)强化学习算法,
通过与环境交互来逐步学习最优的状态-动作值函数
在Q-learning中,我们使用贝尔曼方程来更新Q值,实际更新的公式如下:
𝑄(𝑠,𝑎)←𝑄(𝑠,𝑎)+𝛼[𝑅(𝑠,𝑎)+𝛾max𝑄(𝑠′,𝑎′)−𝑄(𝑠,𝑎)]
其中的max是在s'状态下,采取最佳动作的Q值。
易知,学习过程中的Q值需要用一个二维表来存储,直观且易于修改。
当然只适合小的环境,稍微复杂一点可能就不合适了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









