







最近在做 LLM 窗口外推的相关工作,因此刚好也回顾一下目前最流行的位置编码 RoPE。
01
关于RoPE
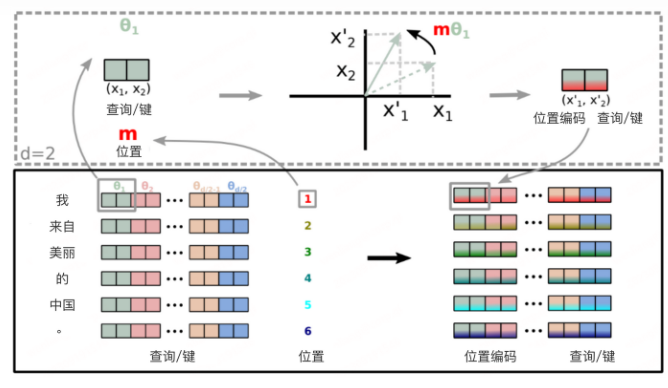
RoPE(Rotary Position Embedding),是苏剑林大神在 2021 年就提出的一种 Transformer 模型的位置编码。
RoPE 是一种可以以绝对位置编码形式实现的相对位置编码,兼顾了模型性能和效率。
2023 年上半年的时候,大模型位置编码尚有 Alibi 和 RoPE 在相互比拼,而到了 2023 年下半年,及今 2024 年,新开源出来的模型,大部分都是使用 RoPE 了。当然 Alibi 也有其优势,这个在讲 Alibi 的时候来说。
苏神在他的个人网站科学空间中对 RoPE 有相关文章进行了介绍,本篇是在这个基础上,对 RoPE 进行理解(公式和符号上也会沿用苏神的写法)。
02
以绝对位置编码的方式实现相对位置编码
前面提到,RoPE 是一种一绝对位置编码的方式实现的相对位置编码,那么这么做能带来什么收益?
先说原因:
在文本长度不长的情况下(比如 Bert 时代基本都是 256/512 token 的长度),相对位置编码和绝对位置编码在使用效果上可以说没有显著差别。
如果要处理更大长度的输入输出,使用绝对位置编码就需要把训练数据也加长到推理所需长度,否则对于没训练过的长度(训练时没见过的位置编码),效果多少会打些折扣。
而使用相对位置编码则更容易外推,毕竟 token-2 和 token-1 的距离,与 token-10002 和 token-10001 的距离是一样的,也因此可以缓解对巨量长文本数据的需求。
但是传统相对位置编码的实现相对复杂,有些也会有计算效率低的问题。由于修改了 self-attention 的计算方式,也比较难推广到线性注意力计算法模型中。
总结来说,就是绝对位置编码好实现,效率高,适用线性注意力,而相对位置编码易外推,因此就有了对“绝对位置编码的方式实现相对位置编码”的追求,去把二者的优点结合起来。
下面简单回顾一下绝对位置编码和相对位置编码。(对位置编码比较熟悉的朋友可以直接跳到第3节。)
(1)绝对位置编码
先回顾一下带绝对位置编码的 self-attention。
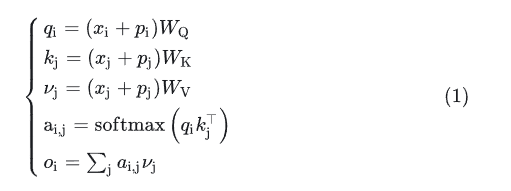

(2)相对位置编码

直观来说,比如词表大小是 1 万,模型训练窗口最大长度是 512,那么对于模型来说,实际上要区分的输入是 1 万×512=512 万个。
看起来虽然不少,但是在海量的数据和训练量下,这也不算什么事儿,模型确实能 handle。

*Google 式*

为什么要增加一个 clip 操作?因为直观上,一个词对其左右附近的其他词的位置关系理应更加敏感。
比如“我请你吃饭”中,“吃饭”这个词需要以高分辨率明确
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









