









依赖框架 Hadoop,Zookeeper
整合框架Phoenix,Hive
一、HBase定义
以hdfs为数据存储的,一种分布式、可扩充的NoSQL非关系型数据库。
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
关系型数据库如MySQL是按照行列表存储,非关系型数据库是kv对存储
二、Hbase数据模型
依据Google的BigTable论文,是一个稀疏的、分布式的、持久的多维排序map
map指映射,由行健、列键、时间戳索引,映射中的每个值都是一个未解释的字节数组。
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族;
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识;
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元,创建表的时候创建;
- 列限定符:列族里的数据通过列限定符(或列)来定位;
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell);
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引;
三、HBase快速入门
HBase安装部署
1.启动zookeeper
[wy@hadoop102 zookeeper]$ bin/zkServer.sh start
[wy@hadoop103 zookeeper]$ bin/zkServer.sh start
[wy@hadoop104 zookeeper]$ bin/zkServer.sh start
2.启动 Hadoop集群
[wy@hadoop102 hadoop]$ sbin/start-dfs.sh
[wy@hadoop103 hadoop]$ sbin/start-yarn.sh
3. HBase的解压
1)解压Hbase到指定目录
[wy@hadoop102 software]$ tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/
[wy@hadoop102 software]$ mv /opt/module/hbase-2.4.11 /opt/module/hbase
2)配置环境变量
[wy@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
3)使用source让配置的环境变量生效
[wy@hadoop102 module]$ source /etc/profile.d/my_env.sh
HBase的配置文件
1)hbase-env.sh修改内容,可以添加到最后:
export HBASE_MANAGES_ZK=false
2)hbase-site.xml修改内容:
修改
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
添加
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
3)regionservers
hadoop102
hadoop103
hadoop104
4)解决HBase和Hadoop的log4j兼容性问题,修改HBase的jar包,使用Hadoop的jar包
[wy@hadoop102 hbase]$ mv /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
5)HBase远程发送到其他集群
[wy@hadoop102 module]$ xsync hbase/
HBase服务的启动
1)单点启动
[wy@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[wy@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver
2)群启
[wy@hadoop102 hbase]$ bin/start-hbase.sh
3)对应的停止服务
[wy@hadoop102 hbase]$ bin/stop-hbase.sh
高可用(可选)
在HBase中HMaster负责监控HRegionServer的生命周期,均衡RegionServer的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置。
1)关闭HBase集群(如果没有开启则跳过此步)
[wy@hadoop102 hbase]$ bin/stop-hbase.sh
2)在conf目录下创建backup-masters文件
[wy@hadoop102 hbase]$ touch conf/backup-masters
3)在backup-masters文件中配置高可用HMaster节点
[wy@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters
4)将整个conf目录scp到其他节点
[wy@hadoop102 hbase]$ xsync conf
5)重启hbase,打开页面测试查看
四、HBase API 操作
新建项目后在 pom.xml 中添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.11</version>
</dependency>
</dependencies>
创建连接
根据官方API介绍,HBase的客户端连接由ConnectionFactory类来创建,用户使用完成之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对HBase的命令通过连接中的两个属性Admin和Table来实现。
见gitee
Hbase · 王大雷/redis - 码云 - 开源中国 (gitee.com) https://gitee.com/wy980530/redis/tree/master/Hbase
https://gitee.com/wy980530/redis/tree/master/Hbase
五、HBase基本架构
1)Master
实现类为HMaster,负责监控集群中所有的 RegionServer 实例。主要作用如下:
(1)管理元数据表格hbase:meta,接收用户对表格创建修改删除的命令并执行
(2)监控region是否需要进行负载均衡,故障转移和region的拆分。
通过启动多个后台线程监控实现上述功能:
①LoadBalancer负载均衡器
周期性监控region分布在regionServer上面是否均衡,由参数hbase.balancer.period控制周期时间,默认5分钟。
②CatalogJanitor元数据管理器
定期检查和清理hbase:meta中的数据。meta表内容在进阶中介绍。
③MasterProcWAL master预写日志处理器
把master需要执行的任务记录到预写日志WAL中,如果master宕机,让backupMaster读取日志继续干。
2)Region Server
Region Server实现类为HRegionServer,主要作用如下:
(1)负责数据cell的处理,例如写入数据put,查询数据get等
(2)拆分合并region的实际执行者,有master监控,有regionServer执行。
1)MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile,写入到对应的文件夹store中。
2)WAL
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
3)BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。
3)Zookeeper
HBase通过Zookeeper来做master的高可用、记录RegionServer的部署信息、并且存储有meta表的位置信息。
HBase对于数据的读写操作时直接访问Zookeeper的,在2.3版本推出Master Registry模式,客户端可以直接访问master。使用此功能,会加大对master的压力,减轻对Zookeeper的压力。
4)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高容错的支持。
六、HBase进阶
6.1写流程
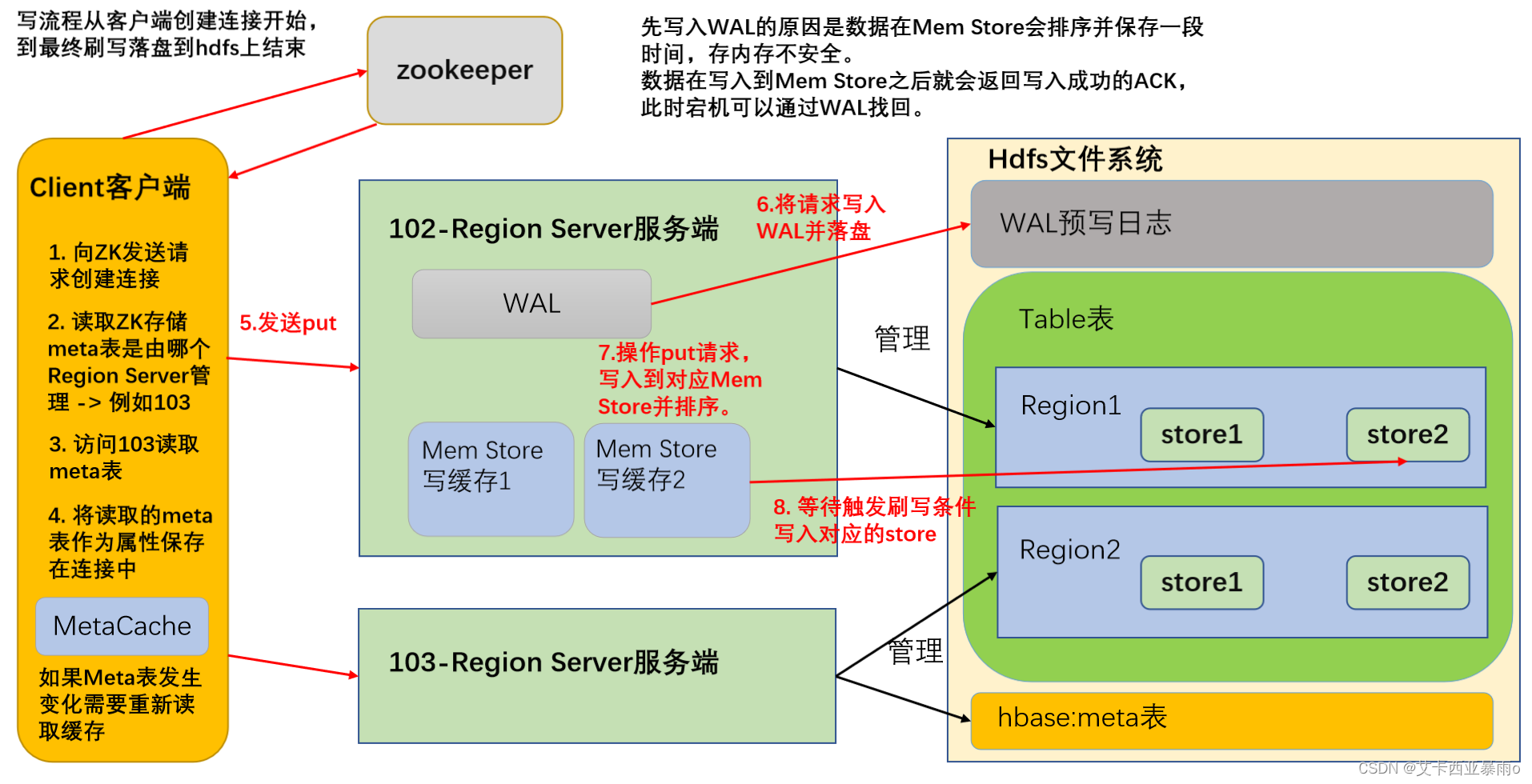
首先创建HBase的重量级连接
(1)首先访问zookeeper,获取hbase:meta表位于哪个Region Server;
(2)访问对应的Region Server,获取hbase:meta表,将其缓存到连接中,作为连接属性MetaCache,由于Meta表格具有一定的数据量,导致了创建连接比较慢;
之后使用创建的连接获取Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问RegionServer,之后在获取Table时不会访问RegionServer;
(3)调用Table的put方法写入数据,此时还需要解析RowKey,对照缓存的MetaCache,查看具体写入的位置有哪个RegionServer;
(4)将数据顺序写入(追加)到WAL,此处写入是直接落盘的,并设置专门的线程控制WAL预写日志的滚动(类似Flume);
(5)根据写入命令的RowKey和ColumnFamily查看具体写入到哪个MemStory,并且在MemStory中排序;
(6)向客户端发送ack;
(7)等达到MemStore的刷写时机后,将数据刷写到对应的store中。
6.2读流程
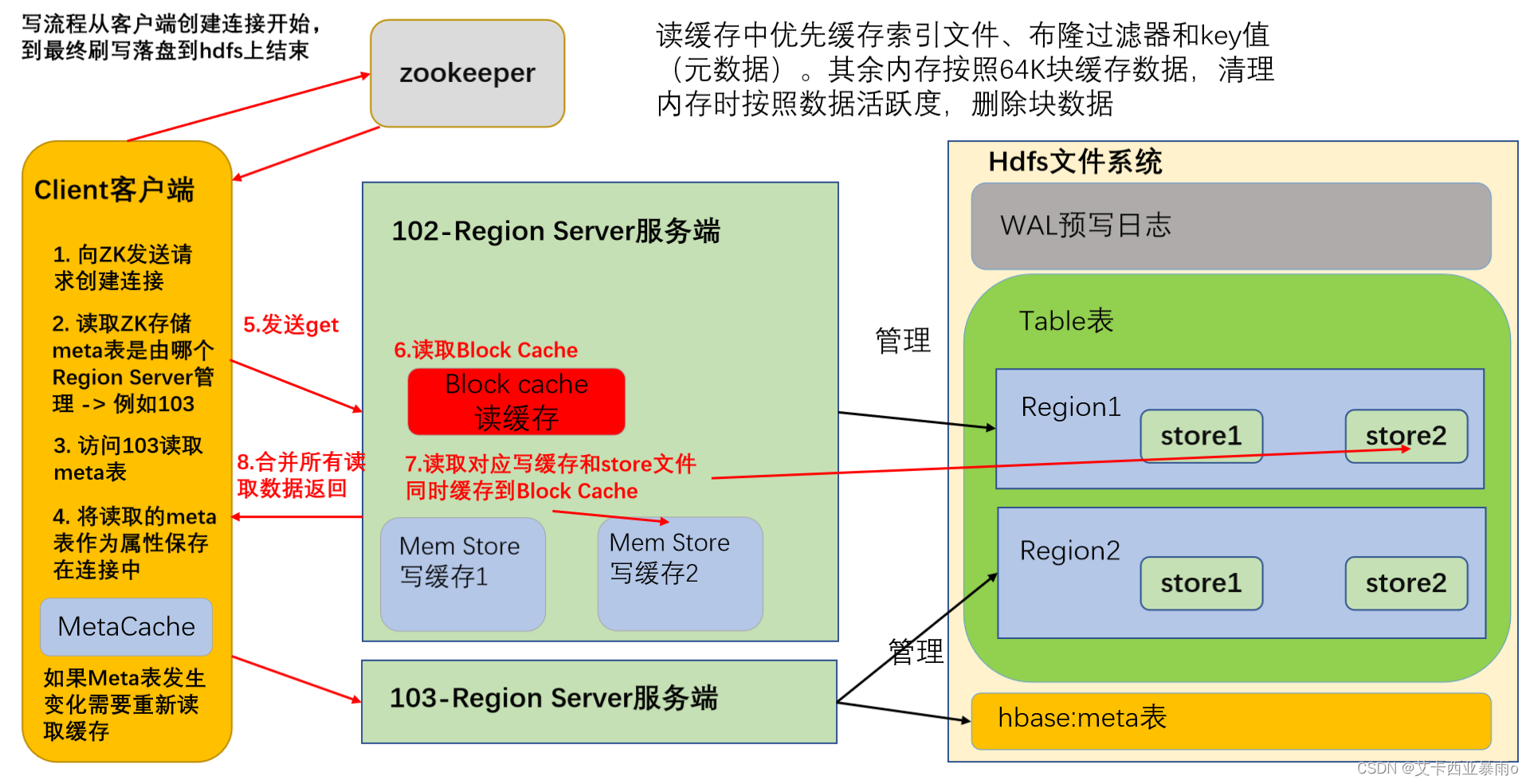
创建连接同写流程。
(1)创建Table对象发送get请求。
(2)优先访问Block Cache,查找是否之前读取过,并且可以读取HFile的索引信息和布隆过滤器。
(3)不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和store中的文件。
(4)最终将所有读取到的数据合并版本,按照get的要求返回即可。
6.3MemStore Flush
当某个memstroe的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。
为了避免数据过长时间处于内存之中,到达自动刷写的时间,也会触发memstore flush。
七、HBase优化
RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈rowkey常用的设计方案。
1)生成随机数、hash、散列值
2)字符串反转
3)字符串拼接
添加预分区优化
预分区的分区号同样需要遵守rowKey的scan原则。所有必须添加在rowKey的最前面,前缀为最简单的数字。同时使用hash算法将用户名和月份拼接决定分区号。(单独使用用户名会造成单一用户所有数据存储在一个分区)
rowkey的设计和预分区相结合 根据业务需求实现
详细可见


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









