






1.

(1)
打印出现NoneType的地方
结果显示:
<class 'NoneType'>原因:经过查阅资料发现:出现这种问题就是,获取不到数据。原因就是该网站被爬太多次,我们被该网页服务器的反爬虫程序发现了,并禁止我们爬取。因此我们需要模拟浏览器,重新给服务器发送请求,并且添加头等信息headers,headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。

注意:headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
你可以找你的浏览器的header,我这里直接给出一个header运行
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
未解决
参考文章:解决python爬虫时遇到AttributeError: ‘NoneType‘ object has no attribute ‘find_all‘_小朱小朱绝不服输的博客-优快云博客
(2)
BeautifulSoup报"AttributeError: 'NoneType' object has no attribute 'find_all' "的原因可能有很多,包括URL错误、HTML代码有误、标签、属性不存在等等。
在使用find_all()方法查找标签时,应该先确保标签、属性存在,避免出现这个错误。同时,推荐使用其他解析器,如lxml,来解决这个问题。
print(soup.find(attrs={'class':'mb20'}).find_all('a'))


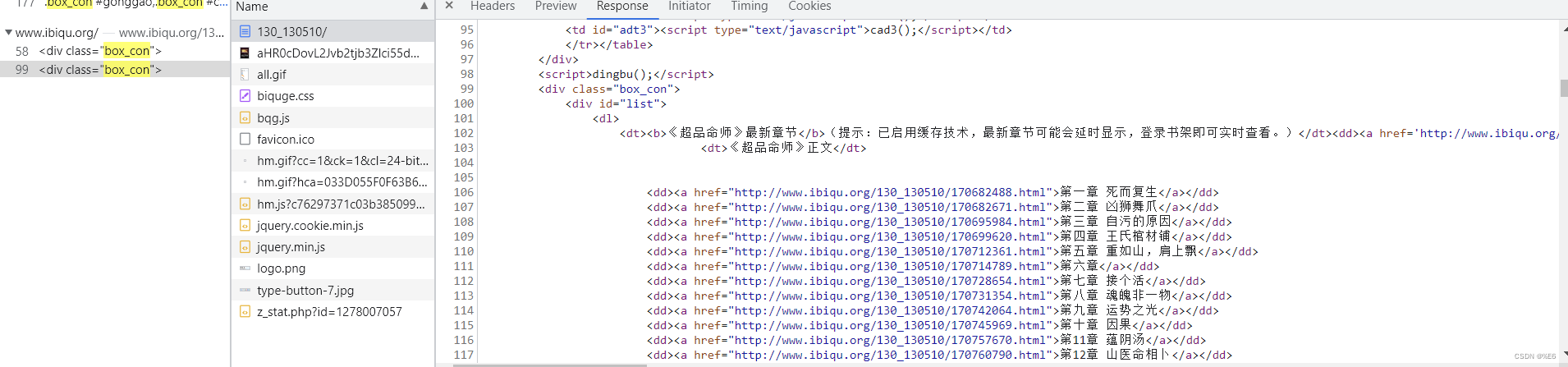
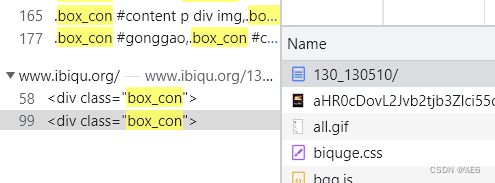
标签名不唯一,find方法
获取到指定文档从上到下第一个指定标签
解决思路:换一本书
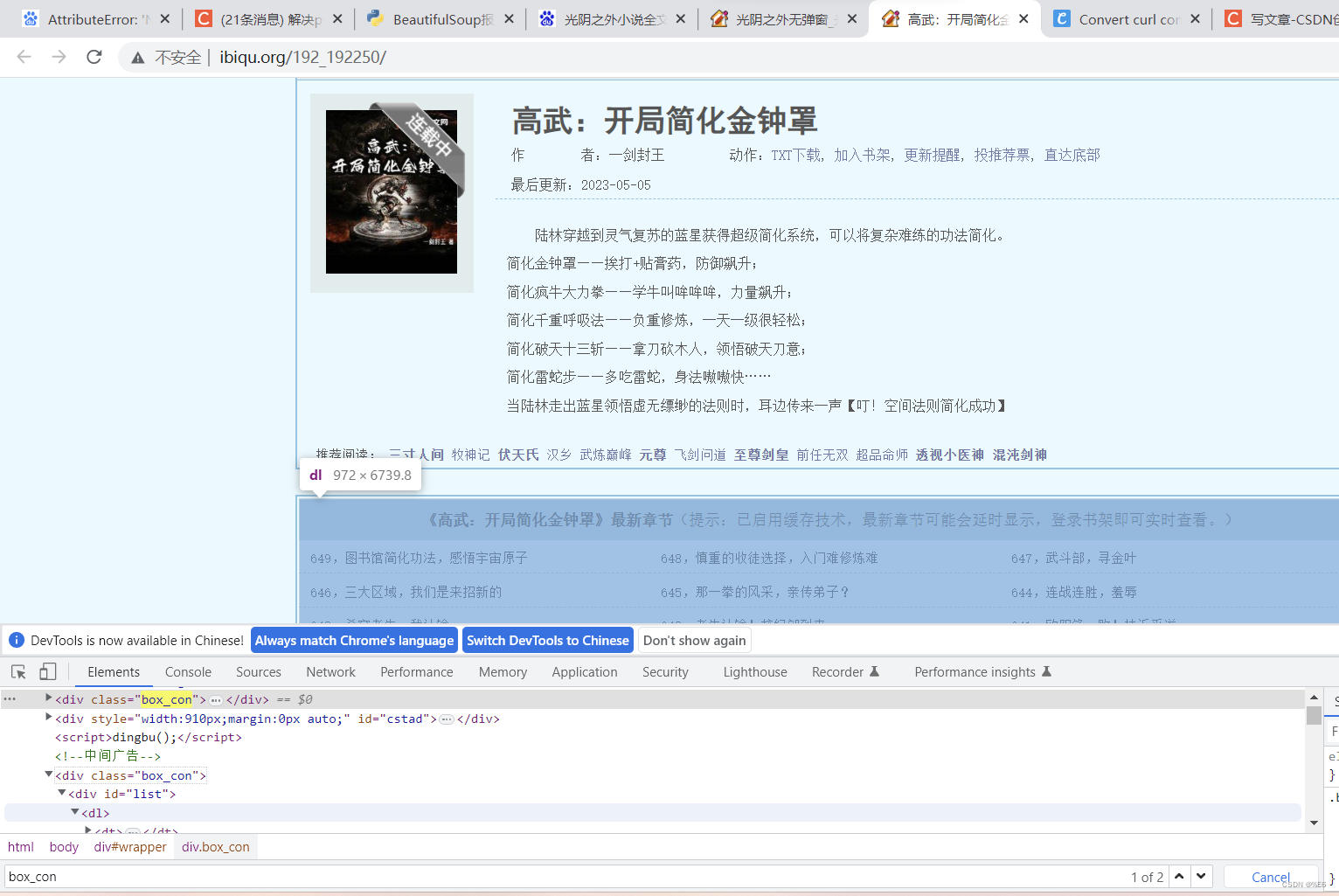
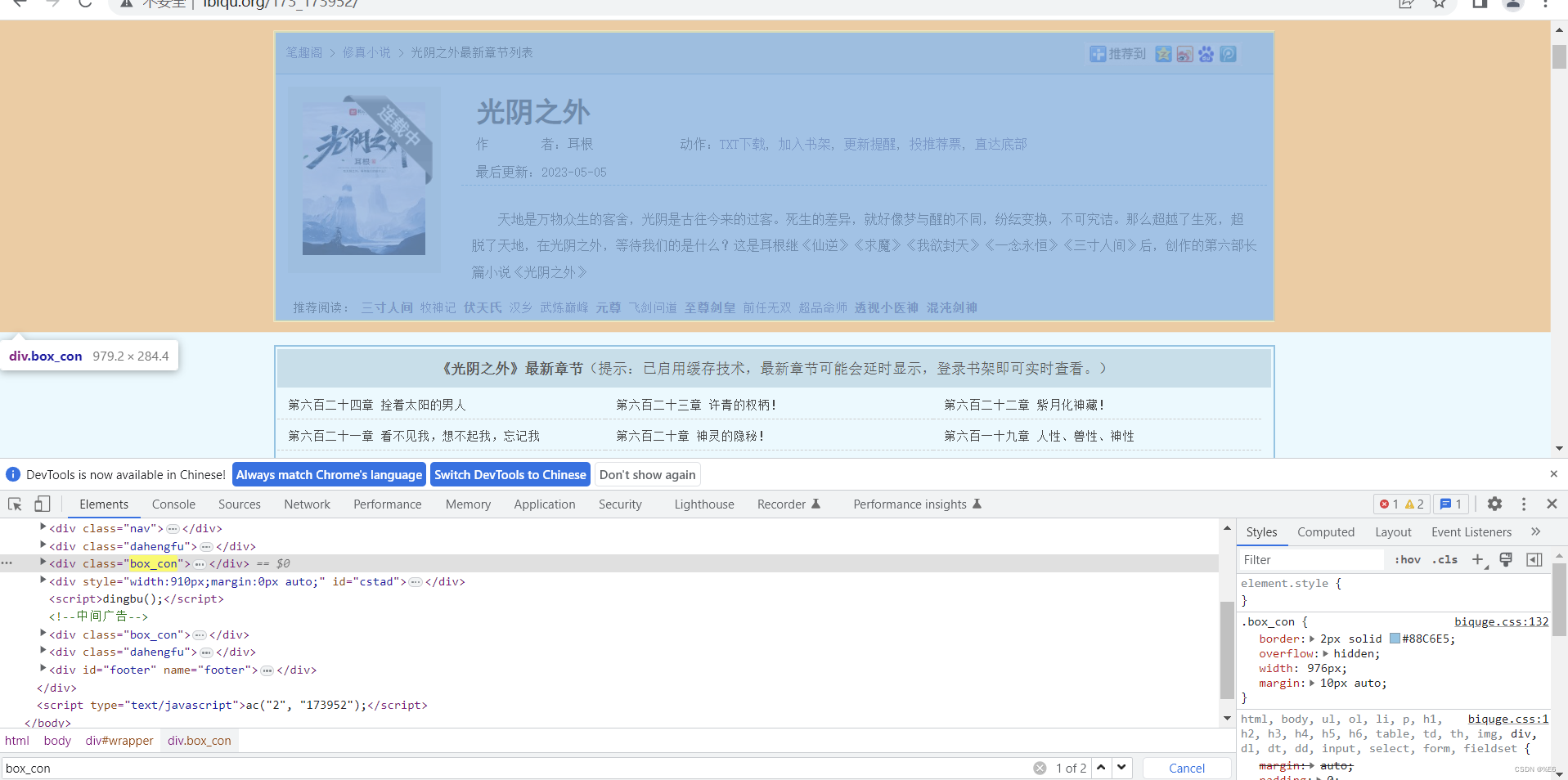
发现换一本书结构也是一样的,box_con标签还是有两个。且最新章节与正文部分在一个box_con容器内
for i in (soup.find_all(attrs={'class':'box_con'}).find_all('a')):

for i in (soup.find_previous(attrs={'class':'box_con'}).find_all('a')):

for i in (soup.find_next(attrs={'class':'box_con'}).find_all('a')):
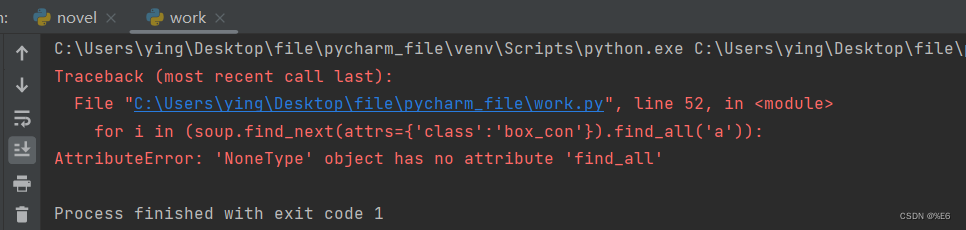
for i in (soup.find_previous(attrs={'class':'box_con'})[1:].find_all('a')):

for i in (soup.find_all(attrs={'class':'box_con'})[1].find_all('a')):
成功
参考文章:
BeautifulSoup报”AttributeError: ‘NoneType’ object has no attribute ‘find_all’ “异常的原因以及解决办法_Python技术站
2.
数据在打开某一节的内容,打开抓包工具netork>Fetch>payload data = { 'articleid': '173_173952', 'chapterid': chapterid, 'pid': flag, }
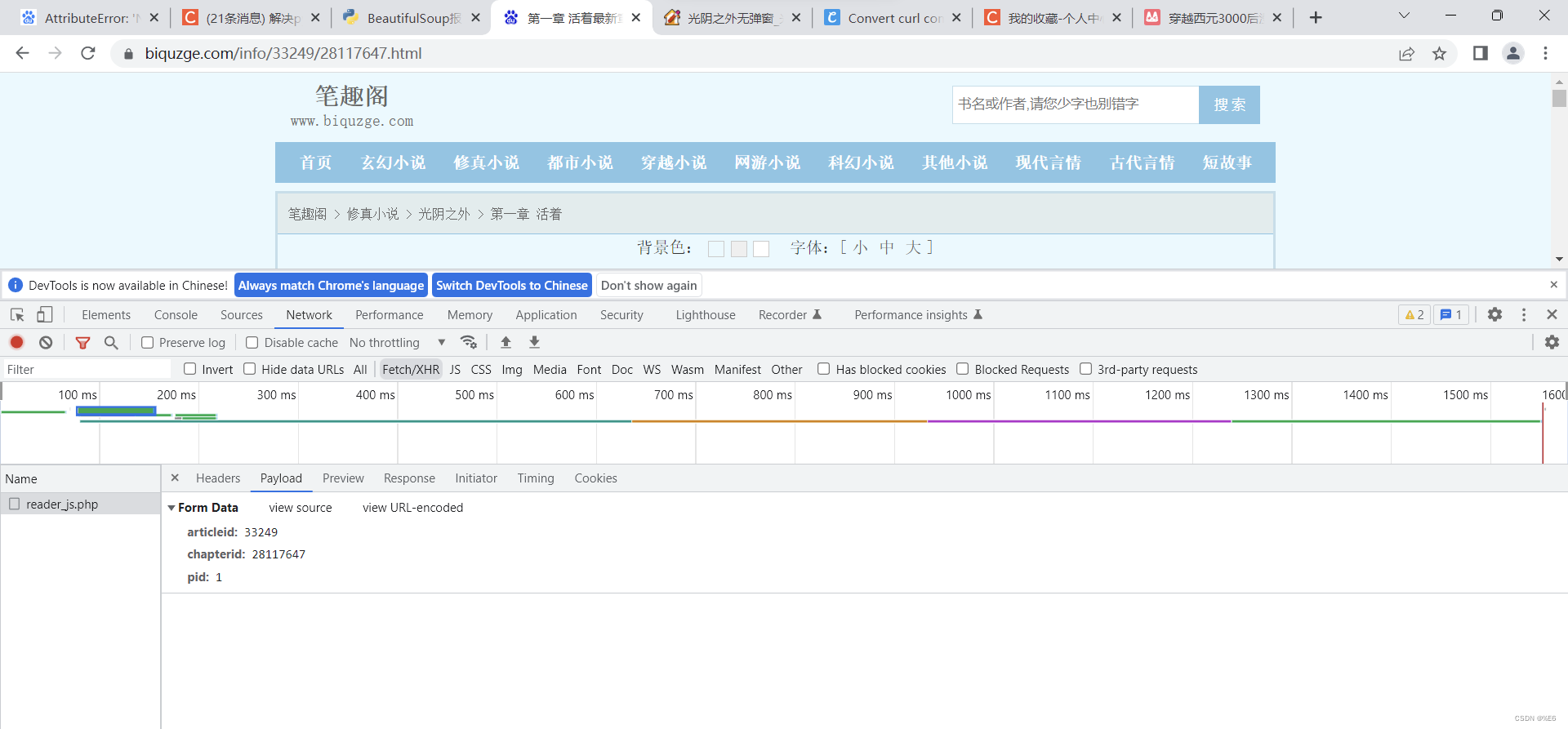
http://www.ibiqu.org/173_173952/
打开第一章的内容,打开抓包工具netork>Fetch>payload
binbin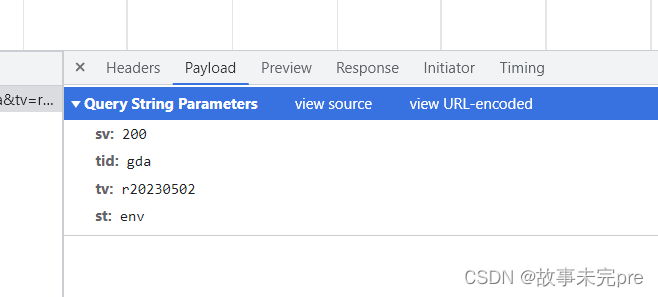
屏蔽部分代码后,运行结果都是目录的内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









