






个人debug得出,模型拆解学习使用
第一步:预训练好的基模型
经过了 model = AutoModelForCausalLM.from_config(cfg)
得到了 LlamaForCausalLM封装的模型结构
CFG
LlamaConfig {
"_name_or_path": "./llama-2-7b/7B",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 2048,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.39.3",
"use_cache": false,
"vocab_size": 32000
}
LlamaForCausalLM(
(model): **LlamaModel(**
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
**)**
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
第二步:Parameter-Efficient Fine-Tuning:PEFT
首先对线性层进行量化
经过了
model.model = replace_linear(model.model, Linear4bit, compute_dtype=compute_dtype,
quant_type='nf4', quant_storage=torch_dtype, skip_modules=skip_modules)
model.is_loaded_in_4bit = True
LlamaForCausalLM(
(model): **LlamaModel**(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): **Linear4bit**(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear4bit(in_features=11008, out_features=4096, bias=False)
**(act_fn): SiLU()**
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
peft_config 的配置
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, inference_mode=False,
r=args["lora_rank"],
lora_alpha=args["lora_alpha"],
lora_dropout=args["lora_dropout"],
target_modules=args["lora_target_modules"],
)
model = get_peft_model(model, peft_config)
经过这一步骤:
PeftModelForCausalLM 内是 LoraModel 内是 LlamaForCausalLM
[
包括了
(model): LlamaModel()
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
]
LlamaModel()下:
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList()
(norm): LlamaRMSNorm()
Embedding Layer(嵌入层)是非常关键的一部分,特别是在处理自然语言处理(NLP)任务时。
这里的Embedding Layer指的是embed_tokens,它是用于将输入的单词索引转换成对应的密集向量表示的层
每一个词汇有使用了4096维度进行表示,总共32000个词汇
# 假设词汇表大小为32000,嵌入维度为4096
vocab_size = 32000
embedding_dim = 4096
ModuleList()下:(0-31): 32 x LlamaDecoderLayer()
Decoder Layers (layers) # 自注意力机制和前馈网络,以及相关的归一化步骤
(layers): ModuleList( # type: ignore
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj):lora.Linear4bit()
(k_proj):lora.Linear4bit()
(v_proj):lora.Linear4bit()
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP( # 前馈网络 信息流控制、维度上升和维度下降
(gate_proj): lora.Linear4bit()
(up_proj): lora.Linear4bit()
(down_proj): lora.Linear4bit()
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()# 输入层归一化
# 对进入解码器层的每个子层(如自注意力或前馈网络层)之前的输入数据进行归一化
(post_attention_layernorm): LlamaRMSNorm()# 自注意力后归一化
# 对自注意力层输出进行归一化处理
)
)
对(q_proj)/(k_proj)/(v_proj)线性层进行了lora化
关于LORA化
LoRA 化的影响
在 LlamaDecoderLayer 的每个组成部分中,原始的线性层(例如 Linear4bit)被替换或增强为包含 LoRA 结构的复合层。每个 LoRA 化的层通常包含以下组件:
1. Base Layer
功能: 基础的线性变换。
LoRA化: LoRA 不替换基本层,而是并行使用。
2. LoRA Components
lora_A 和 lora_B: 这两个模块实现低秩矩阵变换。lora_A 将原始维度映射到一个较小的维度(通常远小于原始维度),而 lora_B 则将这个低维空间映射回原始的高维空间。
目的: 这种变换使得模型能够在不增加过多参数的情况下,学习到额外的、对特定任务有用的适应性变化。
3. Dropout
功能: 在 LoRA 结构中,dropout 被用于正则化低秩变换,帮助防止过拟合。
4. Embedding Parameters
lora_embedding_A 和 lora_embedding_B: 这些是额外的可学习参数,专门用于调整和优化 LoRA 低秩结构的行为。 PeftModelForCausalLM 模型结构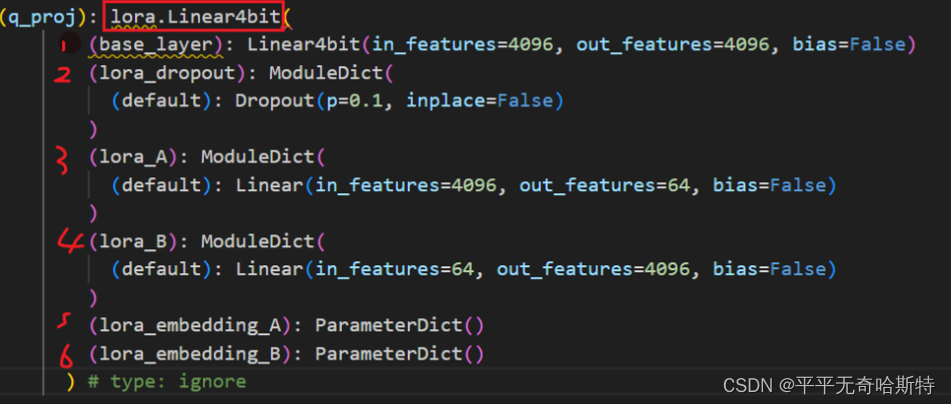
**PeftModelForCausalLM**(
(base_model): **LoraModel**(
(model): **LlamaForCausalLM**(
(model): **LlamaModel**(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x **LlamaDecoderLayer**(
(self_attn): LlamaSdpaAttention(
**(q_proj)**: **lora.Linear4bit**(
**(base_layer)**: Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
**(k_proj)**: lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
**(v_proj)**: lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=11008, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=11008, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=11008, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=11008, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=11008, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=11008, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
)
)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









