






最近在学习NLP,学到word2vec的时候卡了一会,因为我刚开始无法理解无论是无论是CBOW的用上下文预测目标词或者skip-gram的用目标词预测上下文,怎么就能得到具体的词向量呢。经过这两天不断地学习和思考,从相似性突破,这才想通。
我这两天看到的资料都不断强调word2vec假设相邻词之间存在相似性。
我理解的word2vec训练过程如下:未经训练或者仅训练很少次数的词的词向量分布是很乱的,举个极端的例子:国王和女人在一起,男人和女王在一起。
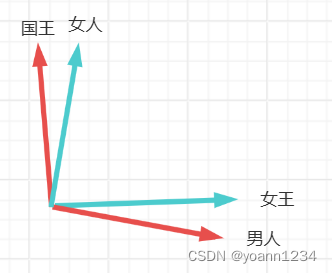
但是在语料中中“国王”和“女王” “相似”,那么模型训练过程就会不断让这两个向量靠近。
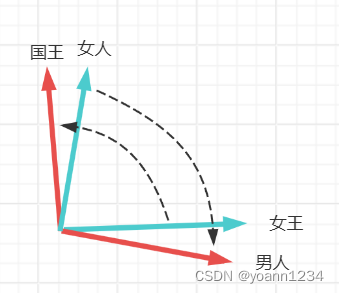
其他词向量同理。等到词向量都分配到和自己“相似”的词附近,训练也就结束了。
所以无论是CBOW或者skip-gram,实际上都是为了让“相似”的词走到一起。
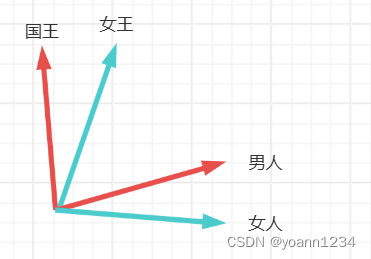
训练结束之后,国王和女王、男人和女人,他们的距离差也相似,因此才会有那个经典的相似问题:国王-女王≈男人-女人。实际上就是向量之间的计算。
可能思考有不对的地方,还请大佬帮忙指出来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









