



 文章探讨了HTTP请求路径的构成,环境变量的作用及其区别,以及四种常见的XML解析方式(DOM、SAX、JDOM、DOM4J),包括它们的优缺点和使用场景。还提及了URI和URL的区别,以及基本数据类型与字符串相加的知识点和路径类型(相对路径和绝对路径)。
文章探讨了HTTP请求路径的构成,环境变量的作用及其区别,以及四种常见的XML解析方式(DOM、SAX、JDOM、DOM4J),包括它们的优缺点和使用场景。还提及了URI和URL的区别,以及基本数据类型与字符串相加的知识点和路径类型(相对路径和绝对路径)。
1.一个请求路径的组成
1.请求路径的构成
客户端提交请求去访问服务端上的指定资源,所以请求路径是由两部分组成,资源路径和资源名称,即:请求路径=资源路径+资源名称。
例如,请求路径:http://localhost:8080/springMVC-1/main.jsp
资源路径:http://localhost:8080/springMVC-1
资源名称:main.jsp
2.环境变量是干啥的?放了和不放有什么区别?
环境变量就是将某些数据、文件、文件夹设置成系统默认值,之后再调用这些的时候就不用完整的路径和地址或者进行设置了,直接就能调用该。任何用户都可以添加、修改或删除用户的环境变量。但是,只有管理员才能添加、修改或删除系统环境变量。
你配置了环境变量,不论在哪cmd都能运行你软件的指令,如果不配置环境变量,那只有在软件的目录下运行cmd,cmd才能运行软件的指令。环境变量的配置就是充当了一个类似于导游的身份,正如上面对环境变量的介绍一句话,cmd当前目录下面寻找此程序外,还应到path中指定的路径去找。
3.XML + 4种常见解析方式
(1)什么是XML文件
XML即可扩展标记语言(eXtensible Markup Language)。标记是指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种信息的文章等。就是可以存储有关系的数据,也可以用来做各种框架的配置文件。
(2) 4种常见解析方式
- DOM 解析
- SAX 解析
- JDOM 解析
- DOM4J 解析
1、DOM(Document Object Model)
DOM 是用与平台和语言无关的方式表示 XML 文档的官方 W3C 标准。DOM 是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而 DOM 被认为是基于树或基于对象的。
优点:
①、整个 Dom 树都加载到内存中了,所以允许随机读取访问数据。
②、允许随机的对文档结构进行增删。
缺点:
①、整个 XML 文档必须一次性解析完,耗时。
②、整个 Dom 树都要加载到内存中,占内存。
适用于:文档较小,且需要修改文档内容
示例:
1.java代码部分
public class DOM {
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException {
//建立DocumentBuilderFactor,用于获得DocumentBuilder对象:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.建立DocumentBuidler:
DocumentBuilder builder = factory.newDocumentBuilder();
//3.建立Document对象,获取树的入口:
Document doc = builder.parse("D:\\2345Downloads\\demo\\untitled2\\src\\main\\java\\xmlCeshi\\ceshi.xml");
//4.建立NodeList:
NodeList node = doc.getElementsByTagName("linkman");
//5.进行xml信息获取
for(int i=0;i<node.getLength();i++){
Element e = (Element)node.item(i);
System.out.println("姓名:"+
e.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
System.out.println("邮箱:"+
e.getElementsByTagName("email").item(0).getFirstChild().getNodeValue());
}
}
}2.xml文件部分
<?xml version="1.0" encoding="UTF-8"?>
<address>
<linkman>
<name>张三</name>
<email>张三@163.com</email>
</linkman>
<linkman>
<name>李四</name>
<email>李四@qq.com</email>
</linkman>
</address>结果:
2、Sax(Simple API for XML)
SAX处理的特点是基于事件流的。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。sax分析器在对xml文档进行分析时,触发一系列的事件,应用程序通过事件处理函数实现对xml文档的访问,因为事件触发是有时序性的,所以sax分析器提供的是一种对xml文档的顺序访问机制,对于已经分析过的部分,不能再重新倒回去处理.此外,它也不能同时访问处理2个tag,sax分析器在实现时,只是顺序地检查xml文档中的字节流,判断当前字节是xml语法中的哪一部分,检查是否符合xml语法并且触发相应的事件.对于事件处理函数的本身,要由应用程序自己来实现. SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。
优点:
①、访问能够立即进行,不需要等待所有数据被加载。
②、只在读取数据时检查数据,不需要保存在内存中
③、不需要将整个数据都加载到内存中,占用内存少
④、允许注册多个Handler,可以用来解析文档内容,DTD约束等等。
缺点:
①、需要应用程序自己负责TAG的处理逻辑(例如维护父/子关系等),文档越复杂程序就越复杂。
②、单向导航,无法定位文档层次,很难同时访问同一文档的不同部分数据,不支持XPath。
③、不能随机访问 xml 文档,不支持原地修改xml。
适用于:文档较大,只需要读取文档数据。
3、JDOM(Java-based Document Object Model)
JDOM是处理xml的纯java api.使用具体类而不是接口。JDOM具有树的遍历,又有SAX的java规则。
JDOM与DOM主要有两方面不同。首先,JDOM仅使用具体类而不使用接口。这在某些方面简化了API,但是也限制了灵活性。第二,API大量使用了Collections类,简化了那些已经熟悉这些类的Java开发者的使用。
JDOM自身不包含解析器。它通常使用SAX2解析器来解析和验证输入XML文档(尽管它还可以将以前构造的DOM表示作为输入)。它包含一些转换器以将JDOM表示输出成SAX2事件流、DOM模型或XML文本文档。JDOM是在Apache许可证变体下发布的开放源码。
优点:
①、使用具体类而不是接口,简化了DOM的API。
②、大量使用了Java集合类,方便了Java开发人员。
缺点:
①、不能处理大于内存的文档.
②、API 简单,没有较好的灵活性
示例:
xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<books>
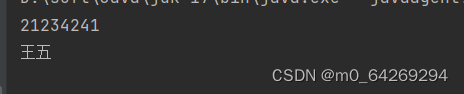
<book email="21234241">
<name>王五</name>
<price>60.0</price>
</book>
</books>
java代码:
package xml.four.lianxi;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
import org.jdom2.output.XMLOutputter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class JDom {
public JDom(){
String xmlpath="D:\\2345Downloads\\demo\\untitled2\\src\\main\\java\\xmlCeshi\\ceshi2.xml";
//使用JDOM首先要指定使用什么解析器。如:
// 这表示使用的是默认的解析器
SAXBuilder builder=new SAXBuilder(false);
try {
//得到Document,我们以后要进行的所有操作都是对这个Document操作的
Document doc=builder.build(xmlpath);
//在JDOM中所有的节点(DOM中的概念)都是一个org.jdom.Element类,当然他的子节点也是一个org.jdom.Element类。
Element books=doc.getRootElement();//得到根元素
//这表示得到“books”元素的所在名称为“book”的元素,并把这些元素都放到一个List集合中
List<Element> booklist=books.getChildren("book");//得到元素(节点)的集合
//轮循List集合
for (Element o : booklist) {
String email = o.getAttributeValue("email");//取得元素的属性
System.out.println(email);
//注意的是,必须确定book元素的名为“name”的子元素只有一个。
String name = o.getChildTextTrim("name");
//取得元素的子元素(为最低层元素)的值
System.out.println(name);
// 这只是对Document的修改,并没有在实际的XML文档中进行修改
o.getChild("name").setText("王五");
}
//保存Document的修改到XML文件中
//我们先要有一个XMLOutputter类,再把已经修改了的Document保存进XML文档中。
XMLOutputter outputter=new XMLOutputter();
outputter.output(doc, Files.newOutputStream(Paths.get(xmlpath)));
} catch (JDOMException | IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new JDom();
}
}
结果:
4、DOM4J(Document Object Model for Java)
虽然DOM4J代表了完全独立的开发结果,但最初,它是JDOM的一种智能分支。它合并了许多超出基本XML文档表示的功能,包括集成的XPath,支持XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过DOM4J API和标准DOM接口具有并行访问功能。从2000下半年开始,它就一直处于开发之中。
为支持所有这些功能,DOM4J使用接口和抽象基本类方法。DOM4J大量使用了API中的Collections类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然DOM4J付出了更复杂的API的代价,但是它提供了比JDOM大得多的灵活性。
在添加灵活性、XPath集成和对大文档处理的目标时,DOM4J的目标与JDOM是一样的:针对Java开发者的易用性和直观操作。它还致力于成为比JDOM更完整的解决方案,实现在本质上处理所有Java/XML问题的目标。在完成该目标时,它比JDOM更少强调防止不正确的应用程序行为。
DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多Java软件都在使用DOM4J来读写XML,特别值得一提的是连Sun的JAXM也在用DOM4J。
优点:
①、大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法。
②、支持XPath。查找节点特别快
③、灵活性高。
缺点:
①、大量的使用了接口,API复杂,理解难。
②、移植性差。
4.URI 和 URL区别
URI算是一个网络资源的特有标识,用来区别于其他资源的标识。URL一般是一个完整的链接,我们可以使用URL直接访问一个网站,URI并不是一个直接访问的链接,而是相对地址。
5.基本数据类型与 字符串相加的 知识点
- String+int -- 直接数字与字符串按顺序拼接起来
- char+int -- char转换为对应的ascll值再与int做相加运算
- char+char -- 不能通过两个char相加得到String,两个char相加固定得到的是99,无论char里面的是什么数值
- 基本数据类型和String相加结果一定是字符串型。
6.相对路径和绝对路径
相对路径:从一个目录为起点到另外一个的目录的路径。
绝对路径:从根目录为起点到某一个目录的路径。
例如:把一张图片放在文件夹内,
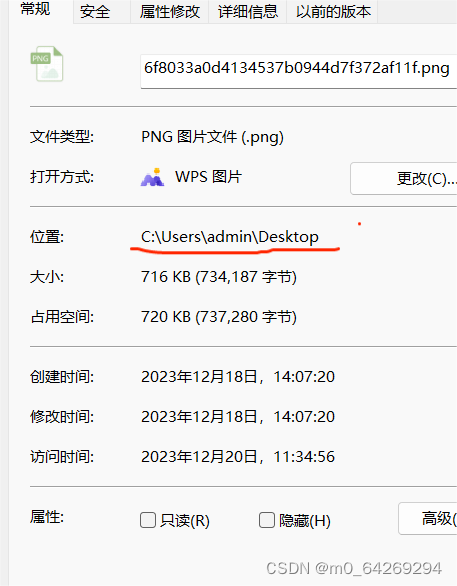
C:\Users\admin\Desktop\6f8033a0d4134537b0944d7f372af11f.png就是绝对路径,如果在相同的文件夹或目录下就可以使用相对路径


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









