







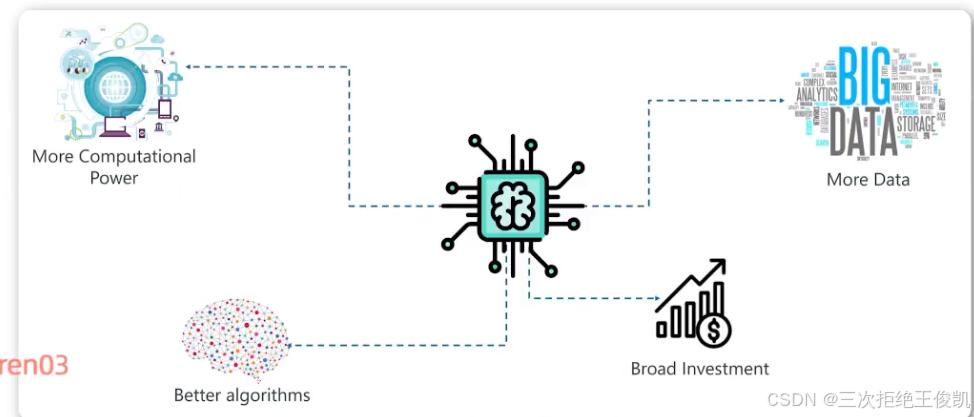
一 人工智能的常见流程

🌟 **约会模型与人工智能流程的类比简写**
**核心比喻**:
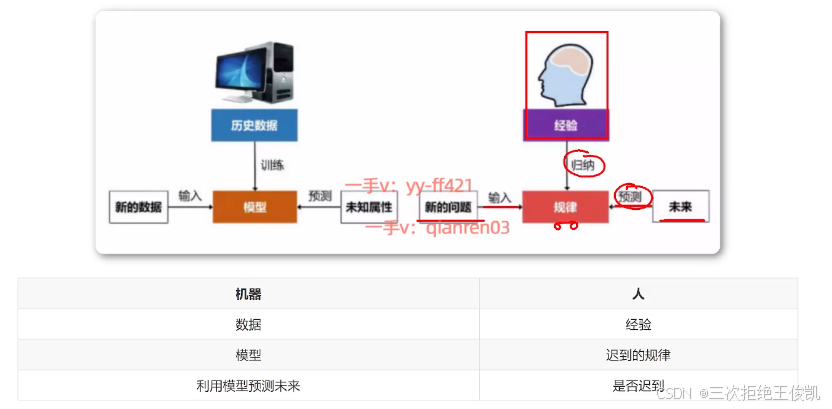
预测约会迟到问题 → 人工智能模型的训练过程
(通过积累历史数据优化决策,类似AI通过数据提升预测精度)*
**数据驱动决策的类比过程**
1. **初始阶段(数据不足)**
- **场景**:前两次约会女友均迟到10分钟
- **预测**:第三天仍猜测7:10到达
- **风险**:若对方准时,你将迟到9分钟(误差大)
2. **数据积累阶段**
- **新增数据**:持续记录一年约会时间
- **模式发现**:迟到频率、平均时长等规律
- **优化决策**:调整自身到达时间(如晚9分钟出门)以最小化等待时间
3. **数据价值体现**
- **数据量↑ → 预测精度↑**:长期数据揭示更稳定的行为模式
- **风险控制**:减少误判带来的负面后果(如让对方等待)
**人工智能开发的核心流程**
1. **数据收集**:获取历史行为记录(如约会时间)
2. **模型训练**:分析数据规律(迟到模式)
3. **预测优化**:动态调整策略(出门时间)
4. **持续迭代**:新数据输入 → 模型更新 → 更精准输出
**类比结论**:
人工智能的本质是通过海量数据“学习”规律,如同人类通过经验优化决策,数据规模和质量直接决定模型性能。
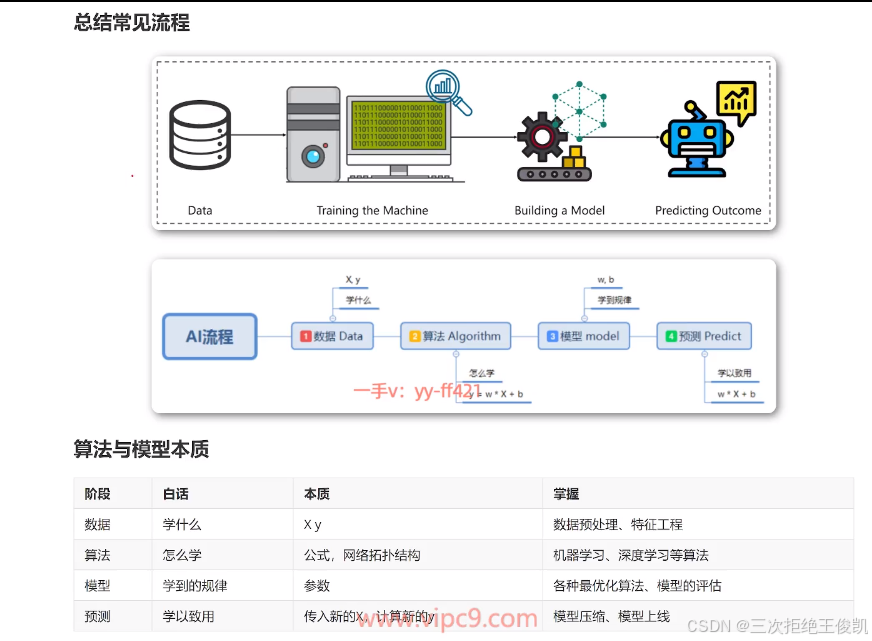


二 机器学习不同的学习方式
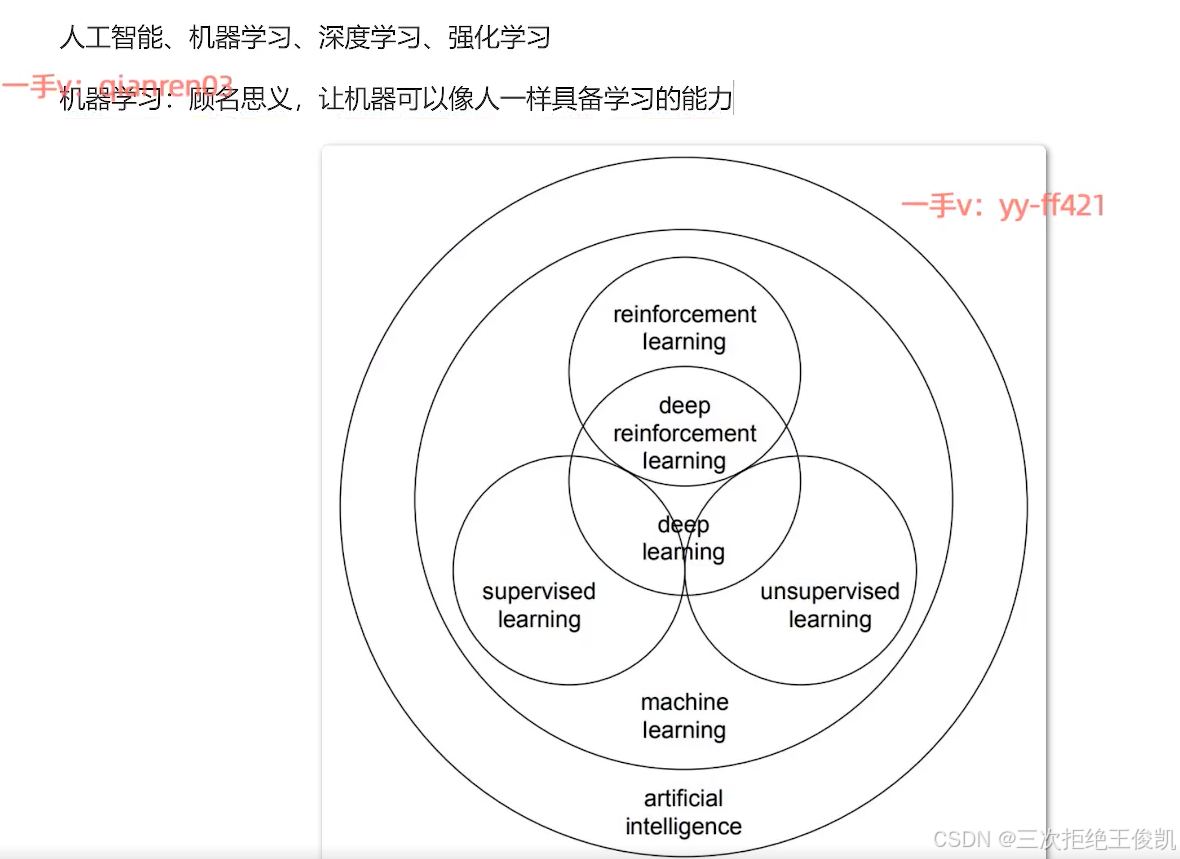
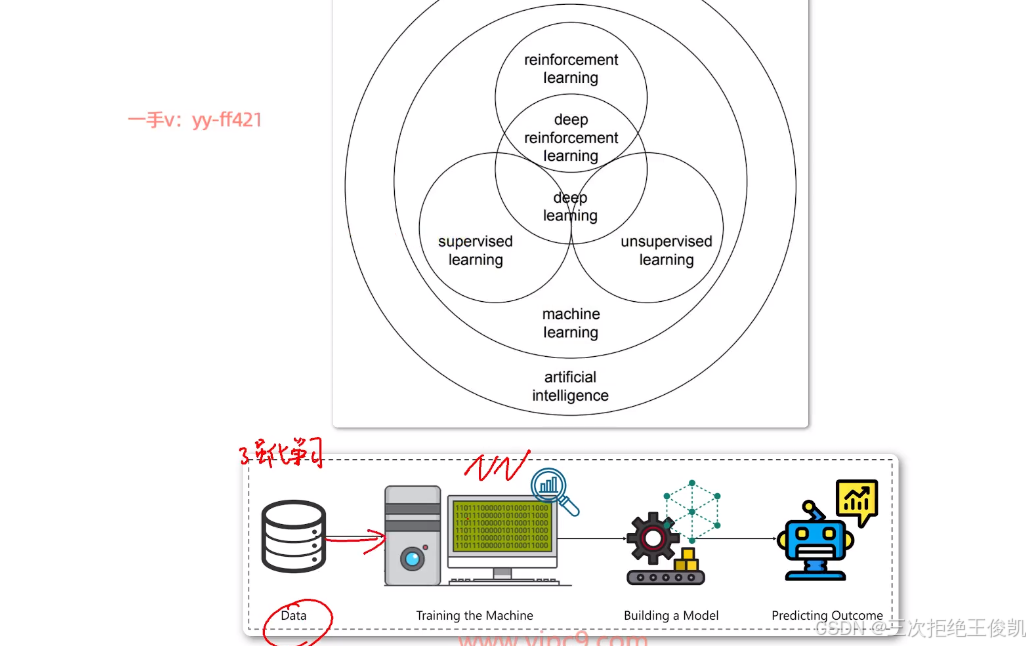
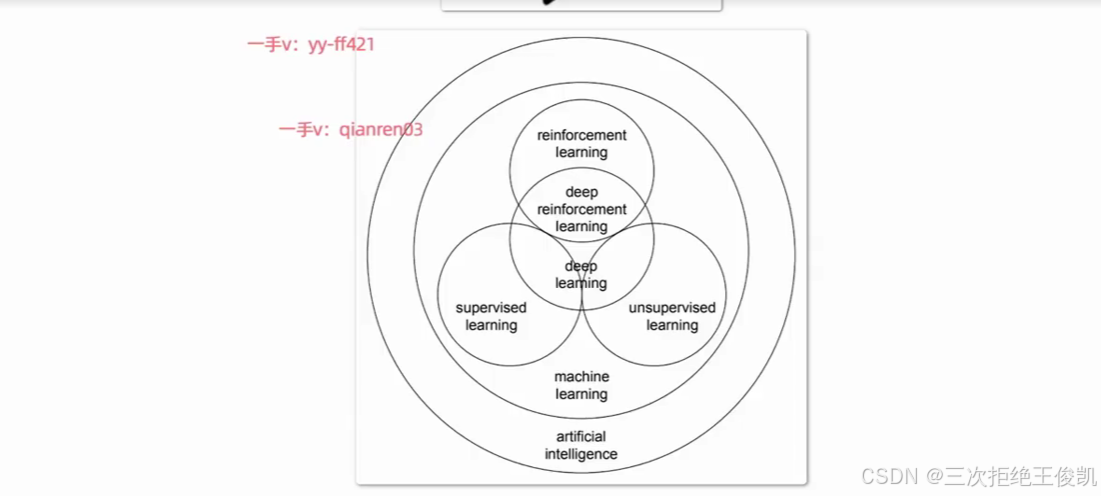
2.1 问题2:人工智能,机器学习,深度学习,强化学习。那这些词汇它们有什么样的关系啊?那它们互相之间啊,是包含关系呢,还是它们是并排的关系呢啊?
那这个其实就是我们这节课要给大家去聊的一个重点啊,那这些其实都是可以称之为叫做人工智能的基本概念了啊。那咱们说人工智能,它里面的核心是什么?其实是机器学习。那这里面我们可以看到这就这张图啊,大家看到最外面这个圈儿,实际上叫做这个artificial intelligence,那这个就是人工智能的意思嘛啊。那里面这一个圈儿呢,实际上叫做machine learning呃,那这个就是机器学习的意思嘛呃,那这里面其实机器学习是人工智能的核心。啊,那主要原因就是机器学习,它研究的是各种各样的,各种各样的算法啊,那咱们说。前面讲流程的时候,咱们也提到了算法是核心啊,那你没有算法,你就不知道如何从数据里面去挖掘规律对不对?所以算法是核心。那机器学习呢,这个名字起的呀,其实顾名思义就是让机器可以像人一样具备学习的能力啊,从数据里面来挖掘规律嘛啊,来去找到这个数据的规律,并且发挥数据的价值嘛。所以说机器学习是核心呃,那也就是这些算法是核心,但是人工智能不仅仅是算法,咱们前面聊过呃,那事实上还包括数据的处理,模型的上线,那包括这个模型的压缩啊,然后包括这个等等,甚至一些相关的硬件。啊,那这里面如果咱们想让这个智能体它变得智能啊,那我们其实就要是有什么呢,我们就要有这个机器学习算法啊,来赋予它相对应的思维方式。呃,然后让它变得智能。
2.2问题3: 这个机器学习呢?可以分为什么样的不同的方式呢?
就是这个算法,它如何从数据里面挖掘规律啊?有有不一样的学习方式,那这里面分为这个supervised learning。那这个我们叫做有监督的机器学习然后它里面也分为unsupervised learning,叫做无监督的机器学习。然后还有一种学习方式呢,叫做reinforcement learning呃,强化学习呃,强化学习,所以说我们的机器学习。可以分为不同的学习方式啊,有有监督学习,无监督学习,还有强化学习的方式。
 2.3 问题4:那下面咱们就具体来去聊一聊这些不同的学习方式,它们之间有什么样的区别?
2.3 问题4:那下面咱们就具体来去聊一聊这些不同的学习方式,它们之间有什么样的区别?
那这里面咱们说。这张图啊,大家看到这前面有一个老师,后面有黑板,在这授课对吧?然后那左边有一个这个学生呢,他事实上就认真的在听老师讲课啊,那这个叫什么呢?这个叫做有监督的机器学习。呃,有监督的机器学习supervised learning。啊,那我们怎么来理解他呢?其实就是老师在讲课过程当中啊,这个学生呢,会吸收老师讲课这个内容,然后他在脑海中会去找到相对应的这个。啊,知识里面的规律,那这个知识里面的规律,它是否正确?那它事实上会及时的得到老师的反馈,因为他在听老师讲课嘛,那他们之间实际上会有一定的沟通,比如说老师问问题,他会回答啊,那回答错了,老师会告诉他回答错了,回答正确,老师会给予肯定啊,
那右边儿这个学生呢,是让他戴着耳机,没有在听老师讲课。那她自己在这儿看书呃,她自己在看书,当然并不是看课外书啊,是看这个呃,课内的这个课程书。那等于他自己在这什么呀,自己在这自学,那这个我们称之为叫做无监督的机器学习啊,它并没有得到这个反馈,它是直接什么呀?它是直接自己来去自学,自己来从数据当中来去找规律啊,自己来去从数据当中来去找规律,那这个就是所谓的无监督的机器学习。那往往咱们说这个有监督的机器学习会用的比较多呃,有监督机器学习会用的比较多,为什么呢?因为你在数据里面。你可以得到相对应的这个标签,你从数据里面可以得到相对应的正确的反馈的这个标签,那这样的话往往会加速你学习的这个过程加速你。调整脑海中这个模型的一个过程啊,那右边这个无监督学习呢,它只能是自己看完一本儿书之后再来去看下一本儿书,然后进行自我的一个纠正。啊,进行自我一个纠正。
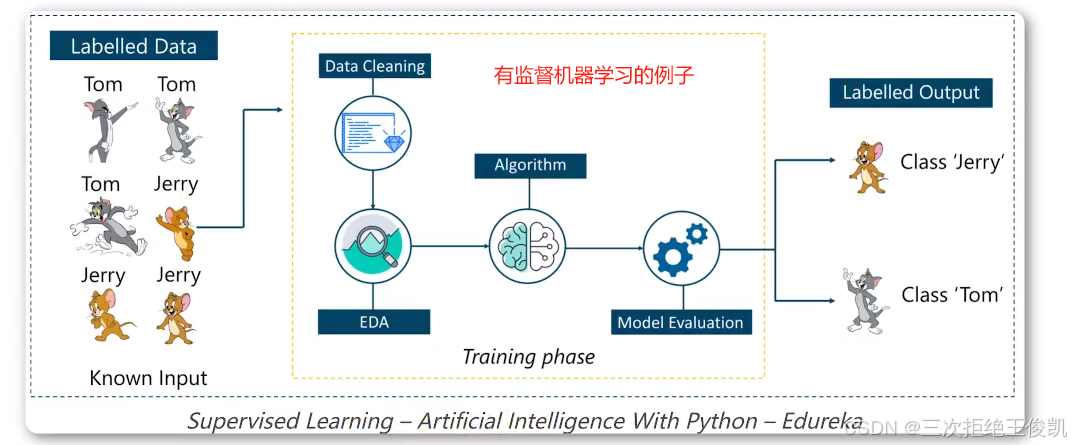
2.4 有监督和无监督具体的例子
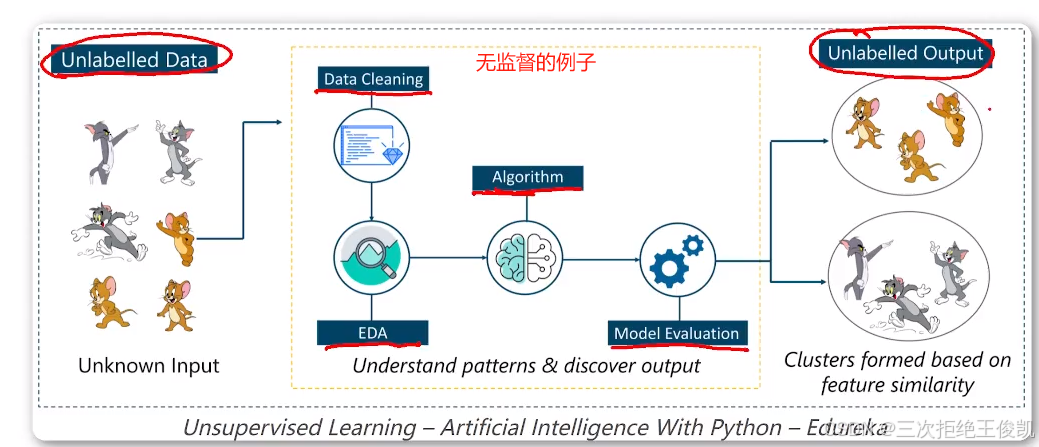

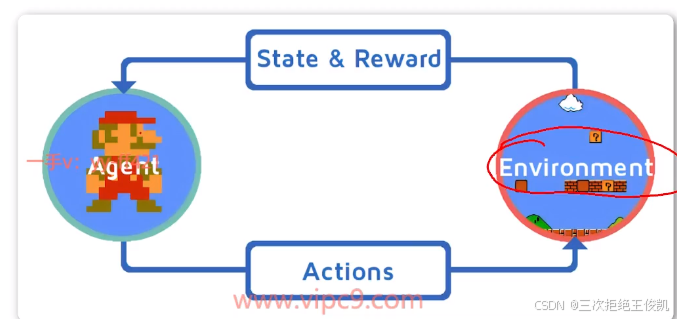
2.5 下面这张图是强化学习,那强化学习什么呢?
强化学习实际上是要有environment环境。呃,是要有environment的环境,然后还有一个agent智能体,然后呢,对于这个强化学习来说,那这个环境事实上是不变的啊。然后那我们就通过呃,我们的智能体跟环境,它们之间来去进行互动。来去进行交互啊,然后使得这个智能体呢,它变得越来越聪明啊,就好比是这个人在玩游戏啊,然后那这个地方呢,他可以玩的越来越好,他可以玩的越来越好,当然我们是希望他玩的越来越。好,然后呢?这个过程就是我们的智能体会去采取相对应的行为。然后这个行为呢,交给我们的环境啊,比如说往前走一步,往上跳一下,这个都叫某种具体的行为。然后呢?这个环境呢?就会变换状态,因为你跳一步往前走一步,那这个界面就变了,那这个状态就变了。啊,然后呢?你往上跳一步,很有可能会啊,获得奖励啊,那你或许呢,也有可能会被这个小乌龟,比如说这个超级玛丽,可能会被小乌龟碰掉,然后呢?失去一条命,然后在这个里面,它就会得到reward啊,其实这个地方不单单是reward的奖励啊,其实。应该叫做奖惩啊,叫奖惩。那它就会得到这样的反馈,它会得到环境的反馈,就是咱们智能体会得到环境的反馈啊,那它就会使得这个智能体呃可以最终得到这个呃,尽可能得到这个高的分数,那它就会去让这个智能体不断的去来调整。啊,或者说不断的去来学习这个策略啊,不断的来去学习策略来调整策略啊,使得什么呢?使得啊,未来他去选择行为的时候可以使得他得到更高的分数呃,得到更高的分数呃,那这个强化学习简单来说就是让智能体呃,通过跟环境进行互动。然后不断的来去学习调整策略的这么一个过程啊,这么一个流程,这么一个过程OK?
所以说,对于不同的什么呀,对于不同的场景呃,对于不同的需求,我们会用不同的学习方式来去做。我们会用不同的学习方式来去做啊,那对应的咱们说机器学习里面有很多很多的算法,那其实对应的有监督机器学习就会有很多相关的算法。那无监督记忆学习呢,也会有很多的算法,然后强化学习呢,也会有很多很多的算法,很多很多算法啊,那不同的算法是让他们的学习方式事实上很有可能是不一样的。呃,很有可能是不一样的呃,那这是咱们把机器学习按照不同的学习方式来去进行划分。
三 深度学习比传统的机器学习更有优势
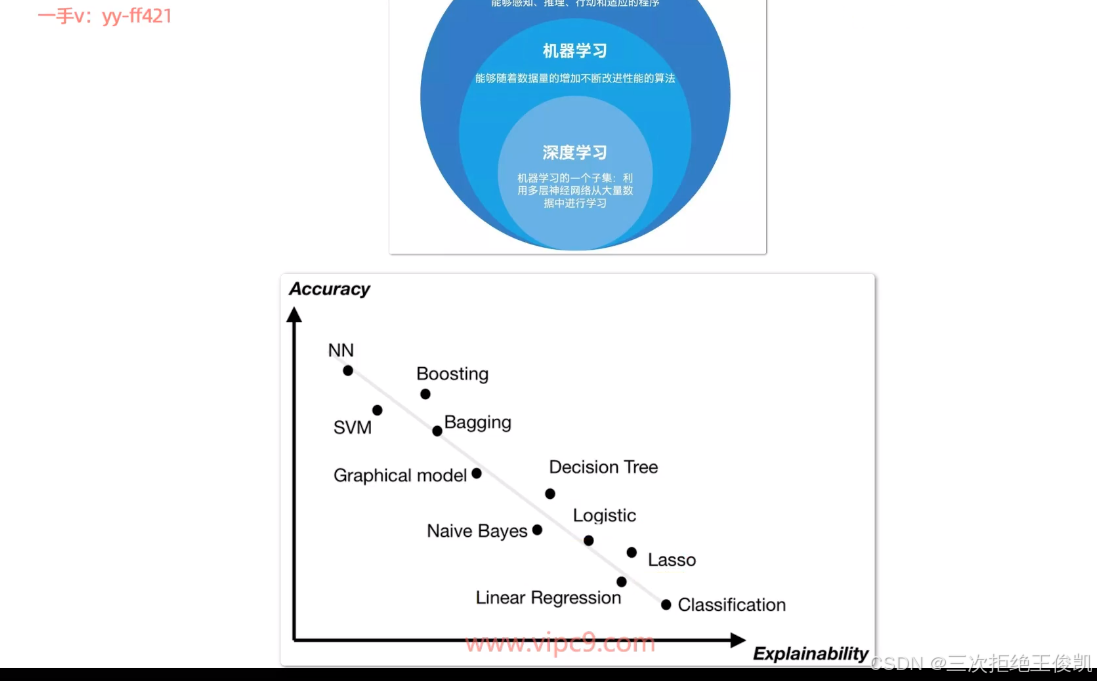

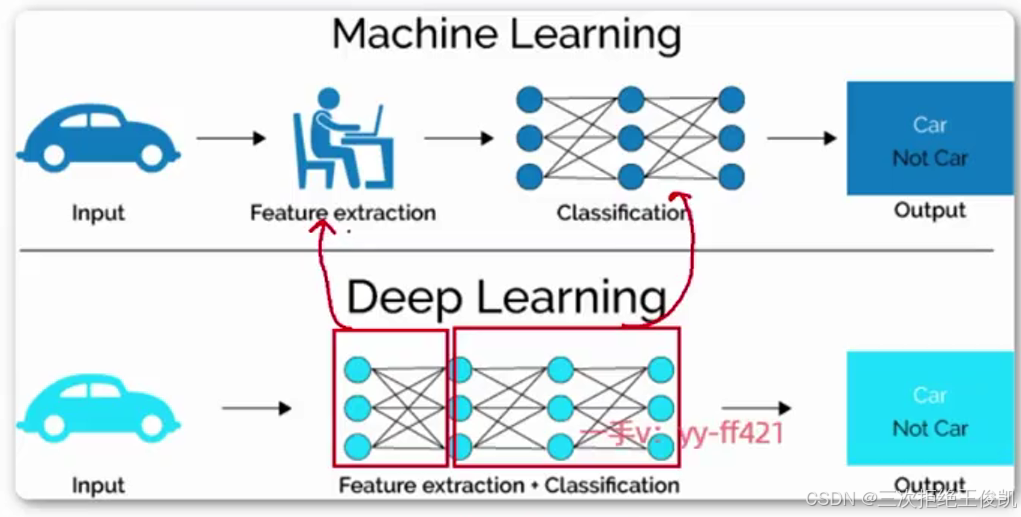
2.7 问题5:那下面咱们来稍微聊一下,咱们说这个机器学习和这个深度学习啊,它们有什么样的区别,或者换过来说,咱们说深度学习啊,为什么这么流行,它有什么样的优势,它有什么样的好处?
啊好,那上下这两张图,大家可以看到呃,同样都是小汽车,这个输入那这个机器学习干什么事情呢?机器学习拿到这个输入。会去做特征的一个抽取,那这个特征抽取在这个地方特意画了一个小人儿坐在电脑前,那也就是说在机器学习的年代啊,那人们更多的事实上会把数据拿过来去做特征的一个抽取特征,一个处理。那这个过程当中,更多的会有人为的参与。呃人为来去选择用什么样的算法来去做这个特征的抽取人为的来去选择哎,这个这个数据该要哪些重要的维度重要的特征?呃,人为的更多的来去参与这个数据的一个预处理,然后再把预处理之后的数据交给后面,具体的这个算法。啊,来去生成这个算法,里面的参数啊,那对于这个神经网络来说啊,那这么画很明显,它是一个神经网络,那对神经网络来说就是去计算这里面的每一个连接上面的数值。啊去来计算,每个连接上的数值。然后呢?未来来新的数据,它也得首先经过特征的提取,然后再去呃带入到我们算好的模型,再来给出相对应的一个预测啊,一个输出,一个预测。呃,那这是机器学习,
那对于深度学习来说,你可以发现它在这里面从输入到输出。它中间只用了一个相对上面来说,更大的一个神经网络呃层次,更深的一个神经网络来去做呃,那首先这第一点就它更好的做到什么呢?它更好的做到了这个端到端的一个业务处理,就是你只需要把输入带给这个神经网络的模型。这个神经网络模型呢,就可以直接给出你输出,这里面不再需要分阶段的,先去做特征处理,再去带入这个具体的这个。呃,算法呃,那这个跟机器学习相比就更加的端到端,那第二点来说什么呢?第二点来说就是它。可训练的参数。实际上,更多。可训练的这个参数。那咱们说这个上面这张图machine learning那这里面刚才老师告诉大家,每根线上面都会有一个参数。呃,那如果你的层次呃,只有这么三层呃,那这之间的参数有多少个?实际上大家可以很容易的数出来。那到深度学习的年代呢,你可以呢,这个网络层次更深,那那会有更多的参数可以去来训练,可以去来学习啊,那这更多的参数来去训练,来去学习的是什么呢?那我们可以把它拆成两部分,前面这框一下,后面这框一下,那后面这个对应就是上面这个三层的网络,那前面这个呢?对应就是。他要干的事情就是特征的一个抽取特征的提取,也就是说站在深度学习的年代,我们会更多的通过设计更好的神经网络。让它自动的来去学到如何进行更好的特征,抽取特征的一个转换特征,
一个处理为了什么呢?为了最终可以预测识别的更准。呃,为了最终可以预测识别更准,那这个就相当于是更加的智能呃,那它就减少了一些人为的这个参与。啊,减少一些人为参与啊,那如果是之前的话,这些年代那很多时候需要特定的对这个领域的数据有所了解的这个专家。然后他们更加的了解这个数据,才能更好的把这数据进行特征的提取啊,那放到深度学习年代呢,那我们可以设计更好申请网络。让这个网络自动的来去学习呃,
我们如何更好的来去对数据进行转换,然后为了后面的。这个分类识别预测呢,可以变得更准确呃,那这个就是咱们再去讲。机器学习,深度学习跟人工智能的关系的同时,老师来去说明一下深度学习的优势啊,首先咱们说。人工智能里面的核心是机器学习,然后里面的子集是深度学习okay呃,那其次咱们说深度学习跟机器学习相比,它的好处那第一点就是更加的端到端啊,那第二点呢就是什么呢?第二点就是它可以更加智能的去学习如何更好的来去对特征进行转换,对特征来去进行提取。

四 有监督机器学习任务与本质
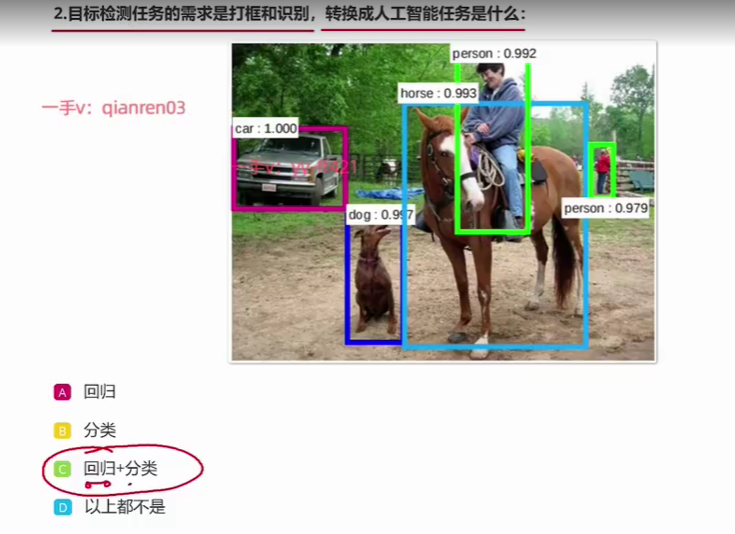
好来,同学们大家好,那这一节呢?咱们来去聊一下人工智能的任务,那我们为什么会去聊人工智能任务呢?是因为人工智能很多应用,我们首先第一步要干的事情就是把这些应用给它转换成人工智能里面的一些任务。呃,然后呢?我们再去寻找相对应的算法,合适的算法来去完成这件事情。然后呢?本节呢?我们也会去顺带首说一下这些人工智能任务的本质是什么?OK啊,
咱们说追求知识,咱们要追求知识的灵魂嘛,咱们把它学透嘛。那这里面咱们上一节说过了,人工智能呢,它里面的核心是机器学习的算法,那机器学习的算法呢,咱们也知道了,它可以有监督的学习方式,无监督的学习方式,还有增强学习的方式啊,那这里面咱们这一节呢,就重点来去看一下,有监督机器学习,它可以去做哪些任务?呃,那无监督记忆学习,它可以去做哪些任务?那至于这个增强学习,咱们后面有专门的阶段来去聊它,因为它相对来说呢,比较特殊。好,那咱们这一节就专注于这个有监督记忆学任务和无监督记忆学习的任务啊,
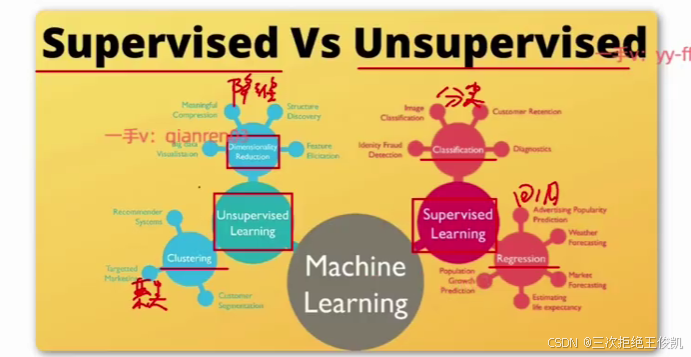
那这里面这张图呢,实际上也是在表达这件事情啊啊supervised有监督;unsupervised无监督。我们可以看到,在supervised learning这一块啊,它分为了这个classification和regression。呃,那一个对应的就是去做分类任务。那另外对应的就是去做回归任务。
啊,那左边这边写的是unsupervised learning啊,那无监督机忆学习里面呢啊,这里面它有写着像clustering啊,那clustering呢,我们叫做聚类。啊,然后呢?还有这个dimensionality reduction啊,这个dimensionality reduction呢?我们叫做降维。啊,
那也就是说有监督机器学习往往要做的事情是回归或者是分类啊,那无监督机器学习呢,往往要去做的任务或者说做的事情呢,是聚类。或者叫降维
4.1 回归任务的本质
好,那咱们下面就来去剖析一下它们的本质是干什么?这些任务的本质是去做什么?
我们首先来去说一下回归。啊,回归任务的本质呢?实际上是要去拟合历史已有的数据。然后呢,根据拟合出来的这个函数走势来去进行预测。好,
那它的特点是什么呢?它的特点是它的这个数据,这个目标变量啊,这个目标变量,它所对应的区间范围是负无穷到正无穷之间的这个值。啊,是具体的这个值啊啊,那它可以是连续型的值,那它可以是连续型的值continuous。好,那回归呢?它可以有哪些应用呢?
比如说我们如果要去预测某只股票,它具体的股票的价格,那我们可以把它转换成是一个回归任务。啊,那如果咱们要去预测这个房价,具体的房子的这个价格,那咱们可以把它呃转换成是一个回归的任务啊,然后再去找回归的相对应的一些。机器学习或者深度学习算法来去做。
好,那这里面咱们说回归属于什么呢?刚才咱们前面讲过了,回归事实上是属于有监督的机器学习。所以那这个地方就意味着,如果是有监督的机器学习,那我们的数据里面既有x也有y,就是我们的目标变量y。那刚才这里面提到的这个目标是负无穷到正无穷之间的值,
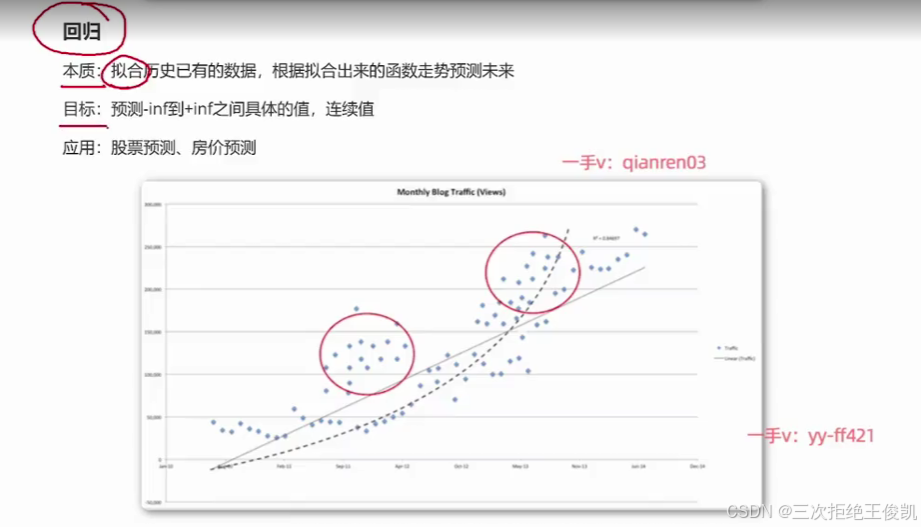
就指的这个y事实上是负无穷到正无穷之间的值。啊,那这里面的y呢?实际上它是连续型的,比如说它可以是几点几OK嗯。好,那咱们拿下面这张图来去举个例子,比如说如果咱们要去预测这个每个月的博客的一个浏览量啊,是多大啊?啊,那比如说咱们在数据里面有x有y,那y是什么呢啊y实际上就是我们的历史上面这个博客,它的这个。随着时间的这个浏览量,那x呢?那x就可以是比如说时间。
啊,这个y呢就可以是这个浏览量啊,所以下面这张图大家看到这个横轴实际上是时间这个纵轴呢,实际上是这个浏览量。啊,那这样的话,咱们拿到一条条历史上的数据,比如说某一个时间点,它的浏览量是多少?下一个时间点,它的浏览量是多少?那咱们就可以把这样的数据,这一条条的这个数据。咱们给它映射到这个高维空间里面去啊,那这里面这图里面的每一个蓝色的点就好比是我们的数据本身。
然后呢?我们去做回归任务,我们要干的事情是拟合OK,干的事情是拟合,那也就是说我们要根据这已有的数据来去拟合出相对应的函数。那这个函数呢?是尽可能的穿过了,我们已有的这个数据,那当然,这里面你可以去选择,比如说这里面你可以看到这个地方是直线。啊,那这个直线就相当于是说你在去用线性的模型,线性的算法来去拟合你已有的数据啊,那你也可以是这种抛物线或者更加复杂的曲线。啊,来一句什么呢?来一句你和你这个。已有的这个数据啊,来去拟合出这个模型啊,那这个我们可以叫做非线性的模型。啊,非线性的模型。那线性的模型就会对应着一些线性的算法,那非线性的模型就会对应着一些非线性的算法OK啊?好,那这里面大家需要记住的就是回归任务,它要做的。事情的本质实际上是要去进行拟合啊,那它所对应的数据啊,
里面的这个目标变量y实际上是负无穷到正无穷之间的。具体的值啊,并且是连续型的值OK,并且是连续型的值。
4.2 分类任务的本质
好,那接下来呢?咱们来去聊一下分类啊,那分类任务呢?实际上它的这个本质呢?实际上是要去找到分界。
啊,然后找到分界之后,未来去进行预测的时候,我们就可以根据这个分界来去对新来的数据来去进行分类。那这个分界呢?可以是分界线啊,可以是分界面啊,甚至是超平面对吧啊,更高的这个空间里面啊,更高维度的空间里面,甚至可以超平面。啊曲面对吧啊。好,那这个分类呢?它的目标是什么呢?就是对新的数据预测出属于各个类别的一个概率值。啊,那我们预测出的这个概率呢?它越正确就越好啊,它就是说这条样本,它本身属于这个类别,我们预测出它属于这个类别的概率。越大实质上就越好。就说明你猜的准嘛,对吧啊,然后呢?我们最后呢?就可以通过这个概率啊来去选择最终。未来预测的时候,这条样本它就属于哪一个类别?呃,那这里面特点是这个目标变量呢?实际上是离散型的值。是离散型的纸啊。因为什么呢?
因为咱们说这个分类,它也是有监督的机器学习对吧啊?那它里面既有x也有y。那这一段的目标指的就是这里面的目标变量y,实际上它是离散型的值,那比如说从零开始,零一二三什么的啊那。那这里面实际上零一二三这种就是离散型的值,那往往这种离散型的值是什么呢?往往这种离散型的值实际上就是类别号。啊,往往离这种离散型的值,实际上就是类别号,就是类别号。好,
那我们这里面的这个分类任务,它能具体去做哪些事情呢?比如说图像识别啊,识别这个人,他有没有带安全帽?啊,识别这个人呢?他有没有戴口罩?那这些事情事实上都是可以用分类任务来去做的,或者说把这些应用可以给他转化成分类任务来去做。那比如说像情感分析啊,来分析出这个是正面的情感还是负面的情感,那这个也可以把它转化为分类的任务来去做。
呃,那比如说像这个银行的风控呃,来去识别出来呃,这个人呢?他这个。是承受什么样的风险?比如高风险呀,中风险低风险啊,来去预测出来,这个人可以承受什么样的风险,然后可以给他去推荐不同的理财产品。
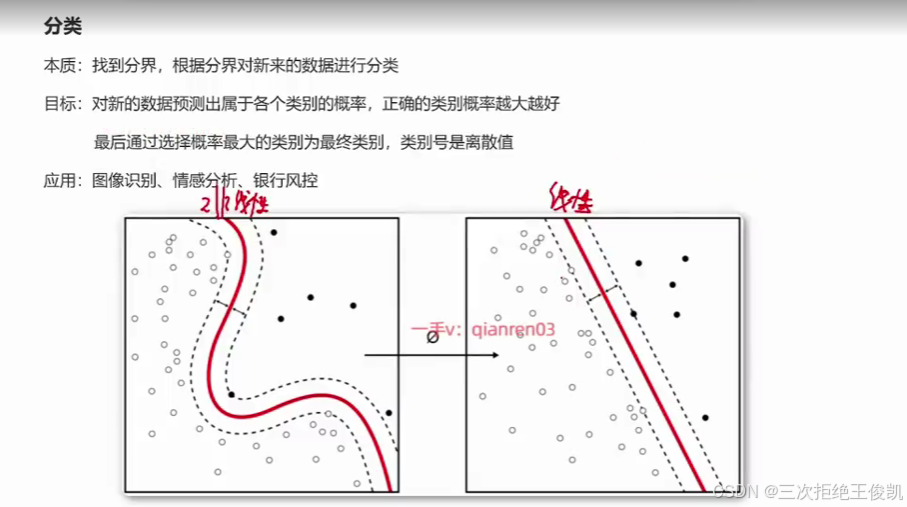
OK啊,那咱们拿下面这张图来举例子的话,也就是说咱们有数据xy,然后那我们的这个数据xy呢啊,那事实上它可以里面有具体的历史的值,比如说零和一。呃,两个类别号那每行实际上是一条样本,那比如第一条样本的标签是零,第二样本标签是一,那以此类推,后面也是一些零一这样的。啊,那比如说我们可以把这里面图里面的空心点啊,看成是属于某一个类别的点,实心点呢,给它看成是属于另外一个类别的点。啊,那这样的话,咱们就可以什么呀?这样的话,
咱们就可以根据x当然这个地方的x肯定有不同的维度,比如说我们的x1。是一个轴,我们的x2。是一个轴。那这样的话,咱们可以根据我们的x1x2每条样本里面的x1x2把数据映射到高维空间里面去,它会落到某个点,落到某个位置,对吧?会落到某个位置。然后咱们可以根据这个这个标签y给它给它做成是空心的还是实心的,
然后呢,下一步呢,我们就可以通过机器学习的算法。然后来去生成相应的模型啊,这个模型的目的就是把已有的数据给它尽可能的分开呃,那这样的话,未来我们来一条新的样本,比如说打五角星这个位置。那我们就可以根据这个我们之前训练好的这个模型,这个分界线。来去干嘛呢?来去这个判别这个五角星新来这个样本,它是属于哪个类别的?那对于这张图来说,那五角星这个类别很就很明显,它属于实心这个类别嘛,对吧啊,
然后那做分类任务的时候,咱们也可以去使用,比如说非线性的模型。啊,那咱们也可以去使用线性的模型。啊线性的模型啊,那大家看右边这张图,右边这张图就相当于是我们去使用线性的算法,去生成线性的模型,然后这个时候。我们在图里面所呈现的,实际上就是一条直线。作为分界线,把这两个类别的数据给它进行分开。OK,
把它进行分开。那这个就是分类任务的,这个本质呃,要去找到这个分界线呃,要去找到这个分界线。
五 无监督机器学习的任务与本质
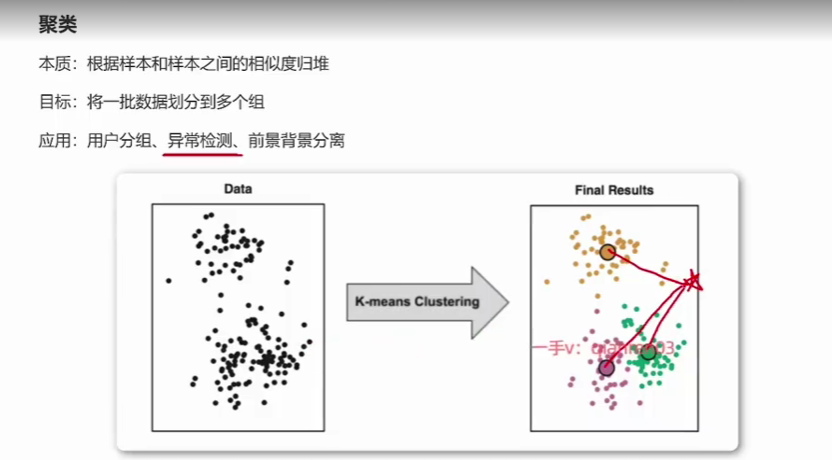
好同学们,那下面咱们来去说一下聚类。啊,那聚类呢?首先呢,它是属于无监督的记忆学习,那这个时候就指着我们在去构建数据的时候,我们数据只有x没有标签啊,没有y。啊,那聚类是什么呢?聚类的本质啊,它就是根据样本和样本之间的相似度来去对我们已有的数据呢。对我们已有的样本呢,来去进行归堆,或者说来去进行分组。哎,或者说来去进行分组okay啊,那它的目标就是将一批数据给它划分到多个组里面去。啊,那什么样的应用可以去给它转化成聚类的任务呢?比如说用户的分组啊,比如说咱们有很多用户的这个。数据啊,那咱们可以把用户的数据呢,给它映射到高维空间里面去啊。比如说这里面一堆黑色的点,然后呢,这个时候因为它没有标签,所以这些点没有什么空心实心,这么也会说啊,那这个时候我们就可以通过聚类的算法,比如说图里面这里面写的k means clustering。k means clustering是聚类里面,其中比较流行的一个算法之一。那通过聚类的算法,可以把这些点呢给它划分为一堆儿一堆儿的,比如说黄色点啊,比如说绿色点。啊,比如说这个粉色点啊,它会把这些数据给它划分成一堆儿一堆儿的OK,那怎么划分的呢?就是根据这个样本之间的相似度啊,比如说比较常用的就是根据距离来去做啊,根据距离来去做。啊,比如说它挨着越近,那它就越是一组的,它挨着越远,它就越不是一组的啊,那这样的话,咱们也可以去做异常检测。呃,咱们也可以去做异常检测,这样的应用啊,
那比如说我们有一个点在这个位置,在五角星这个位置,那这个点它离每一个类别。我们都可以去来计算它距离,每个组距离,每个簇就距离,每个墩它所定的一个距离的远近。那它离哪一组越近,那我们就可以把它划分为到哪一组里面去啊,那如果它离每一组都相对来说比较远,那咱们可以把它识别为是一个异常样本。啊,所以说那异常检测我们也可以通过给它转化成聚类任务来去做这件事情,那比如说图像里面前景背景的分离。那咱们就可以把像素啊给它进行聚类,因为因为一张图片里面啊啊,这个高乘以宽,实际上可以得到很多个像素点嘛,那我们可以根据像素点里面的这个。相就是这个相似度,来去把前景背景给它分成两个堆儿对吧啊,然后那这个时候我们就可以区分出来哪些位置是前景,哪些位置是背景?
好,那下面呢?咱们来去说这个降维那降维呢?首先它也是属于无监督的机器学习,那也就是这个数据里面只有x没有y。啊,那其实这里面我们光听降维这两个字,你应该都能猜出来,因为它只是来降低维度,就是降低最后影响结果的因素啊,所以其实跟y没什么关系。
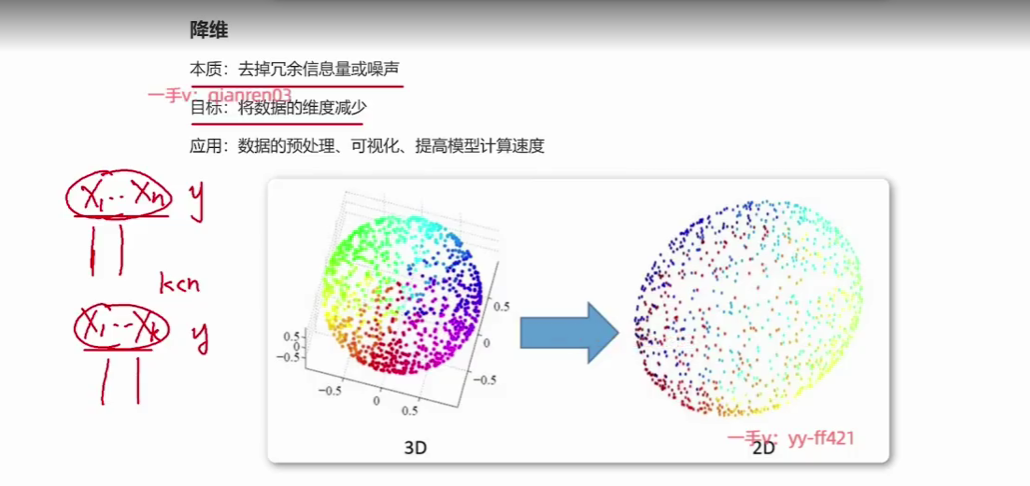
它只是对x来去进行操作啊,那降维任务的本质事实上是要去掉融余信息或者噪声啊,就是我们呃,比如说有很多个这个影响,最后结果y的这个因素啊,那这里面咱们说这个影响,最后结果y因素有很多。那这个时候呢,咱们想去掉一些,因为有些时候有些影响最后y结果因素呢,它可能会相对来说比较重复,比如说x1。呃和其中的比如说呃某一列,那它们之间的这个信息量有可能会有重复,
有可能会有重复的呃。那咱们可以把这些更主要的信息给它去提取出来,那那些重复信息呢?咱们可以把它丢掉啊,那这样的话呢,当我们把减呃,就是把这个影响最后结果y的因素给它减少了,比如说从x1到xn。给它变成了从x1到xk啊,那这个地方x1到xk可以是从x1到xn里面找出来的,其中k个。啊,那也可以什么呢?也可以是把x1到xn给它进行某种转换啊,转换成了新的k个影响最后y结果的因素。啊,那这个地方k是小于n的嘛?那这个就叫做降维了啊,这个就叫做降维了啊,那它要去做的。这个目标呢,就是将数据的维度给它进行减少。那应用的这个场景啊,是让比如说我们去对数据进行预处理的时候,减少一些融余信息或者噪声啊,那我们会去使用降维。啊,我们会把这个数据处理转换成降维任务,来去选择一些降维的算法嘛啊,比如说我们在去做可视化的时候,
如果我们数据维度太高啊,比如说。三维的啊,当然三维并不算高啊,比如说四维五维,那这个时候我们把它去画出来啊,甚至更高维度,上千个维度,咱们把它画出来,那其实人也不太能看懂,对吧?人也看不懂。那这个时候我们就需要把它映射到,比如说二维空间或者三维空间啊,这样的话可以更好来去进行可视化来去进行展示。
啊,那还有一点就是我们为了去提高模型的一个训练速度啊,那么往往会减少这个数据量,咱们来通过降维来保证更有用的信息给它带入到算法里面去。那那些融余信息和噪声就不呃就就不再倒入到这个算法里面去啊,那这个地方就也是降维。它的这个应用场景啊



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









