







 本文介绍如何将二叉树结构序列化为字符串形式,并从该字符串反序列化回二叉树结构。使用前序遍历方法实现序列化,通过递归方式完成反序列化过程。
本文介绍如何将二叉树结构序列化为字符串形式,并从该字符串反序列化回二叉树结构。使用前序遍历方法实现序列化,通过递归方式完成反序列化过程。
序列化和反序列化的目的
JSON 的运⽤⾮常⼴泛,⽐如我们经常将变成语⾔中的结构体序列化成 JSON 字符串,存⼊缓存或者通过⽹络发送给远端服务,消费者接受 JSON 字符串然后进⾏反序列化,就可以得到原始数据了。
上述内容就是「序列化」和「反序列化」的⽬的,以某种固定格式组织字符串,使得数据可以独⽴于编程语⾔。
297. 二叉树的序列化与反序列化
序列化:
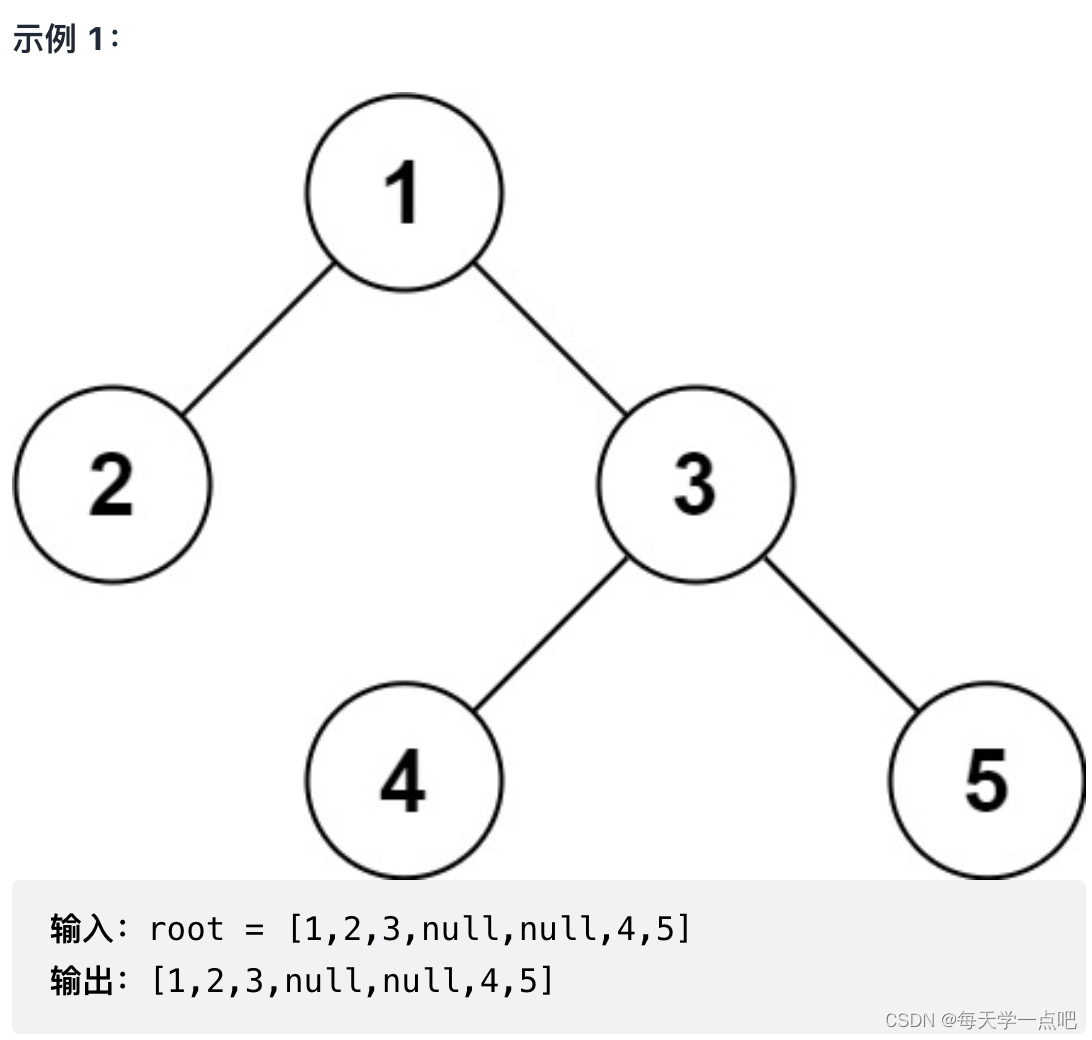
序列化实质是将二维的二叉树结构化信息转化为一维结构。例如通过遍历二叉树结构化信息转换为一维字符串。在此处,我们可以使用任意的遍历方案,例如前序、中序、后序、层序等,不过需要修改对应的反序列化代码。这里我们采用的前序遍历,依旧是使用二叉树遍历框架来求解。对子树间我们采用",“进行分隔,空指针采用”#“标识。因此对于示例1,序列化结果为"1,2,#,#,3,4,#,#,5,#,#”
反序列化:
根据使用的遍历方案不同采用特定的反序列化方案,但核心思想一直,本文以前序遍历为例。具体步骤为,先确定根节点,然后根据前序遍历的规则,递归生成左右子树即可。将序列化结果左侧字符(根节点)依次弹出。
PS:
一般语境下,单单前序遍历结果是不能还原二叉树结构的,因为缺少空指针的信息,至少要得到前、中、后序遍历中的两种才能还原二叉树。但是这里的 node 列表包含空指针的信息,所以只使用 node 列表就可以还原二叉树。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Codec:
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
if not root:
return "#"
result = str(root.val)
left = self.serialize(root.left)
right = self.serialize(root.right)
result = result + "," + left + "," + right
# print(result)
return result
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
if len(data) > 1:
data = data.split(",")
data = collections.deque(data)
return self.transform(data)
else:
return []
def transform(self, values):
val = values.popleft()
if val == "#":
return None
node = TreeNode(val)
node.left = self.transform(values)
node.right = self.transform(values)
return node
# Your Codec object will be instantiated and called as such:
# ser = Codec()
# deser = Codec()
# ans = deser.deserialize(ser.serialize(root))
884. 两句话中的不常见单词

解法:哈希表
构造单词频次字典,若在两句话中共出现1次单词即为不常见单词。
class Solution:
def uncommonFromSentences(self, s1: str, s2: str) -> List[str]:
freq = defaultdict(int)
for word in s1.split():
freq[word] += 1
for word in s2.split():
freq[word] += 1
result = []
for word in freq:
if freq[word] == 1:
result.append(word)
return result

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









