






spark分区
1.spark可以分成两代,第一代是rdd,主要是用来分析日志文件比较多,rdd里面就涉及到了分区的概念,spark是怎么去执行一个程序的。到了第二代,sparksql,已经没有需要个人自己去分区了,更多是操纵表,写sql。
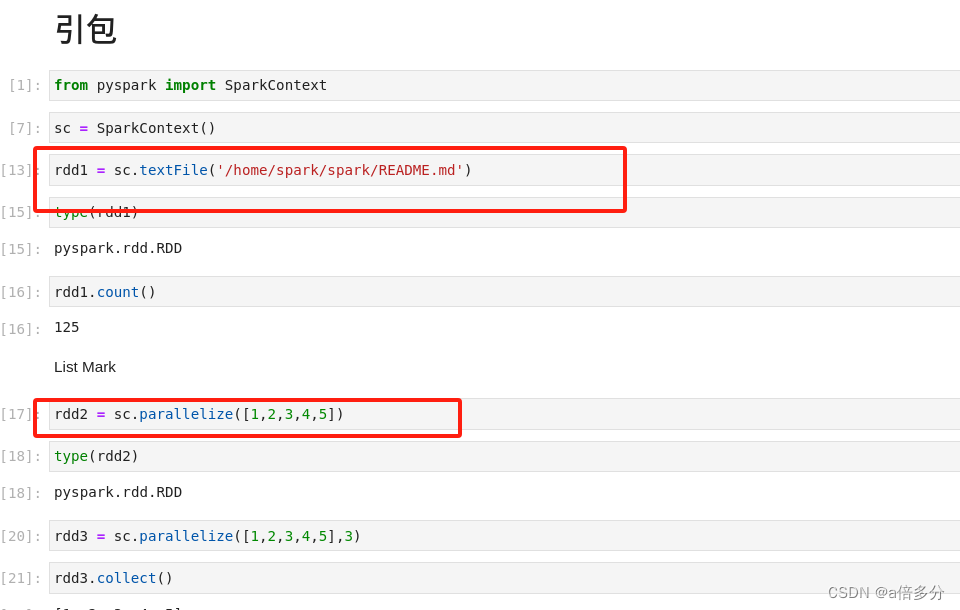
2.spark分区原则: (1)rdd分区的原则是尽量利用集群中的cpu数量,比如一个wordcount任务,一开始根据整个集群中cpu的个数,分成的份数尽量等于cpu核数,就可以充分利用cpu的资源。 (2)rdd在有两种创建方法,分别是parallelize()方法和textFile()方法,两种方法都可以设置分区。
3.parallelize()创建rdd分区分析
在创建rdd的时候,parallelize()中有个numSlices参数,是输入分区数的。比如想分成5个分区就填5。
下面是Spark的俩种换创建方式:

















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









