










博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为优快云特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
目录
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!
承诺所有开发的项目,全程售后陪伴!!!

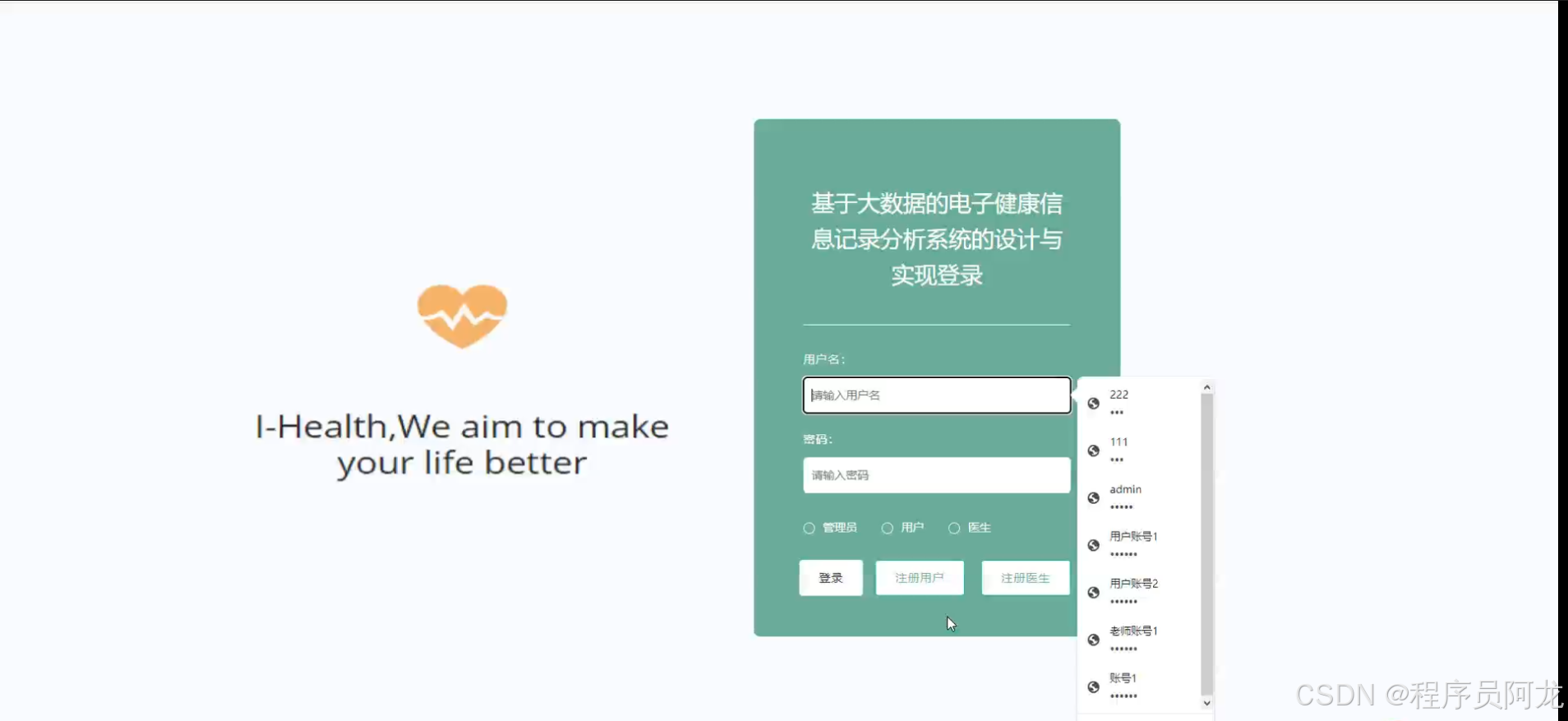
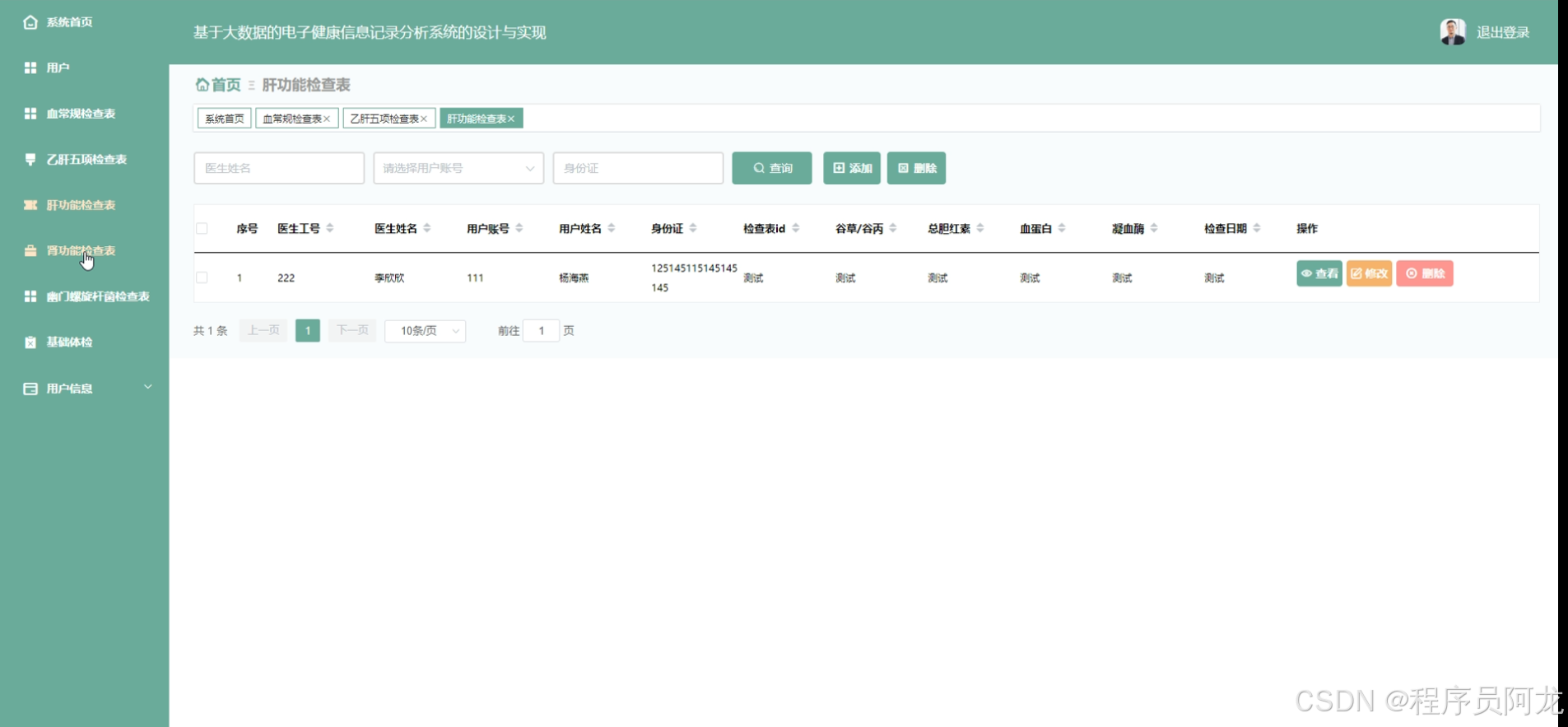
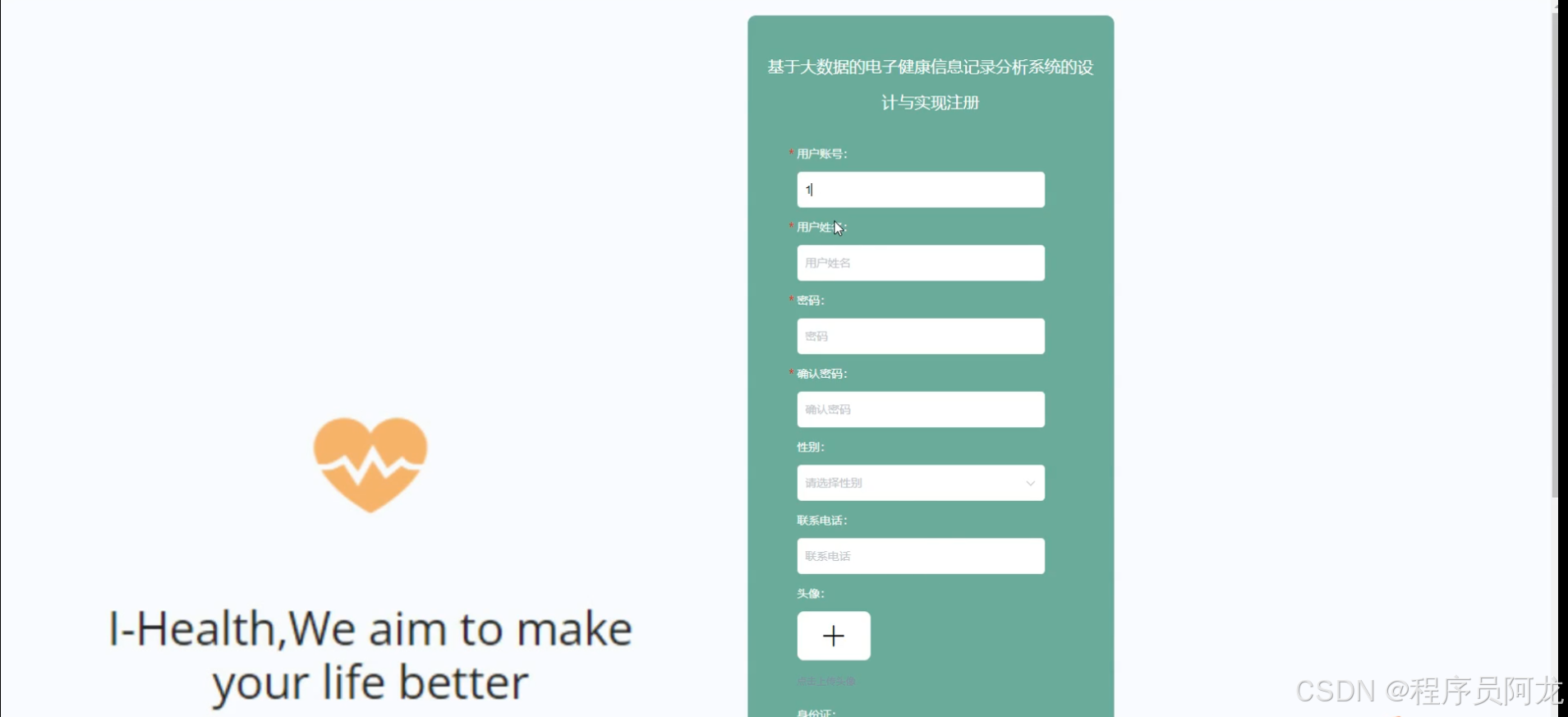
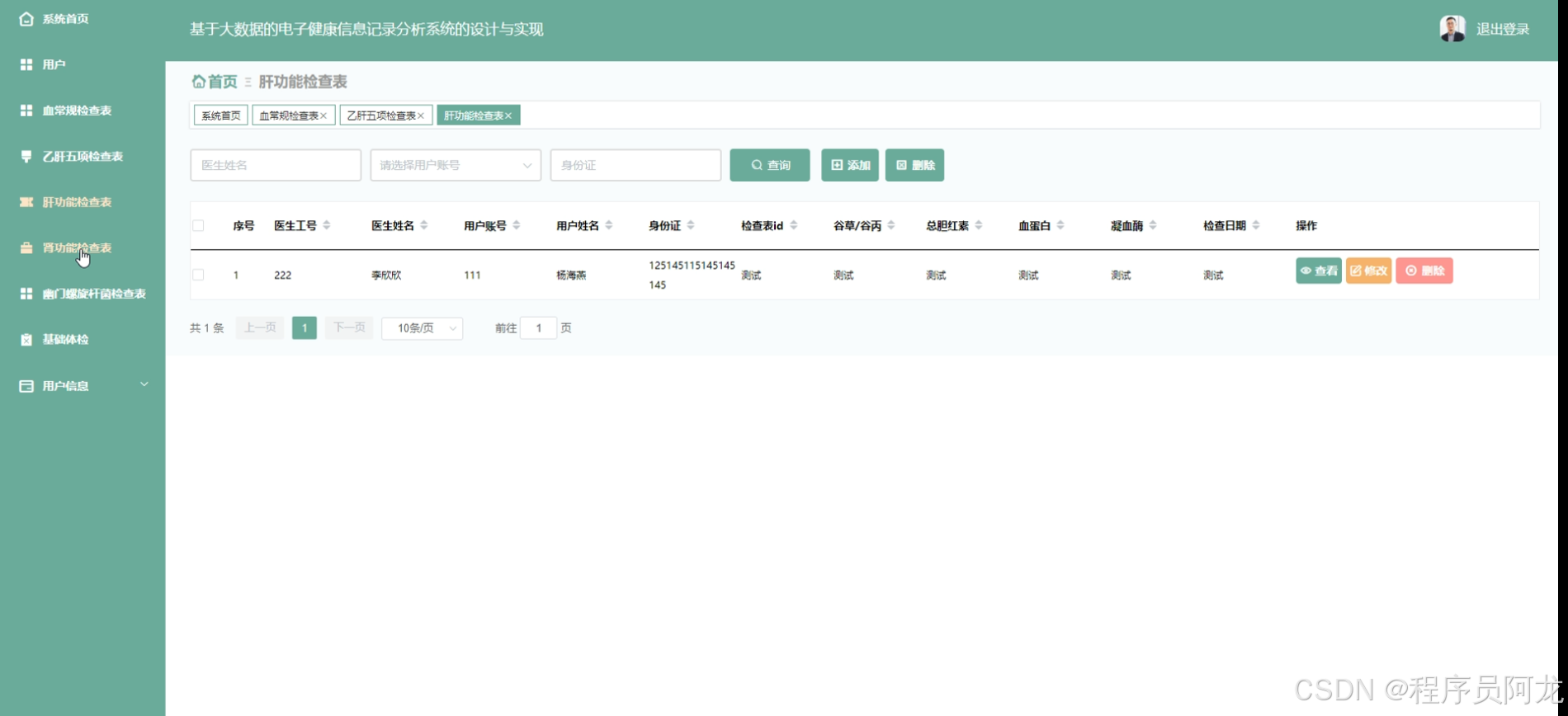
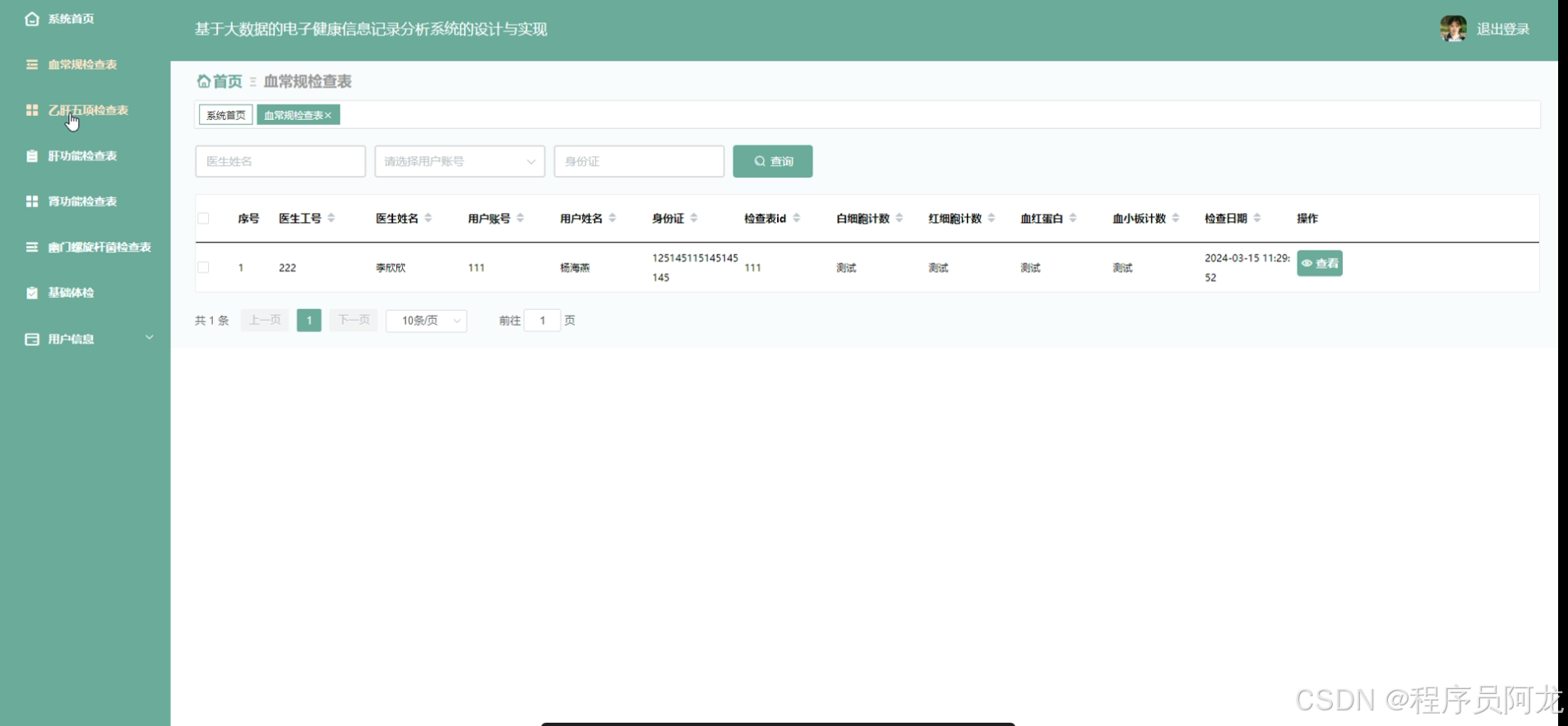
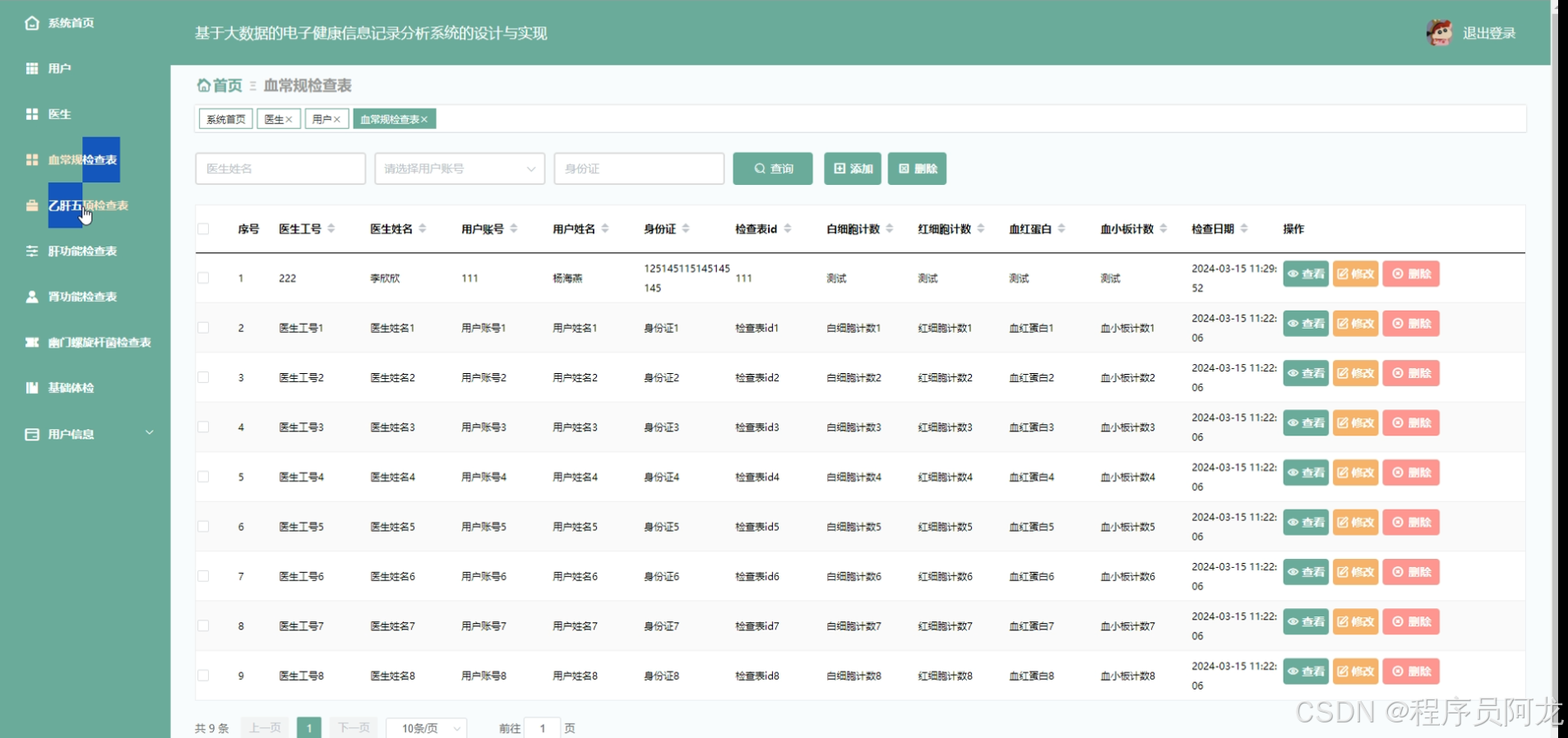
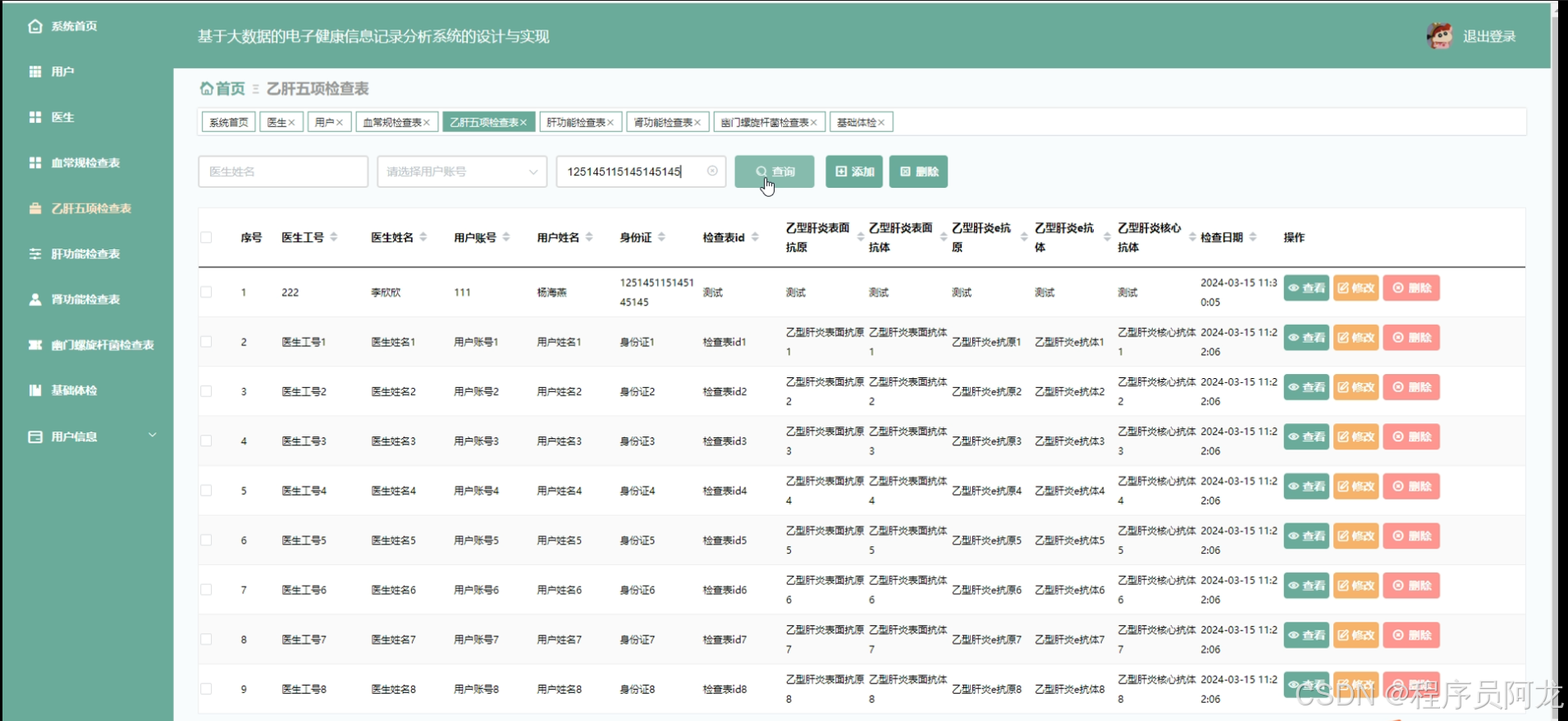
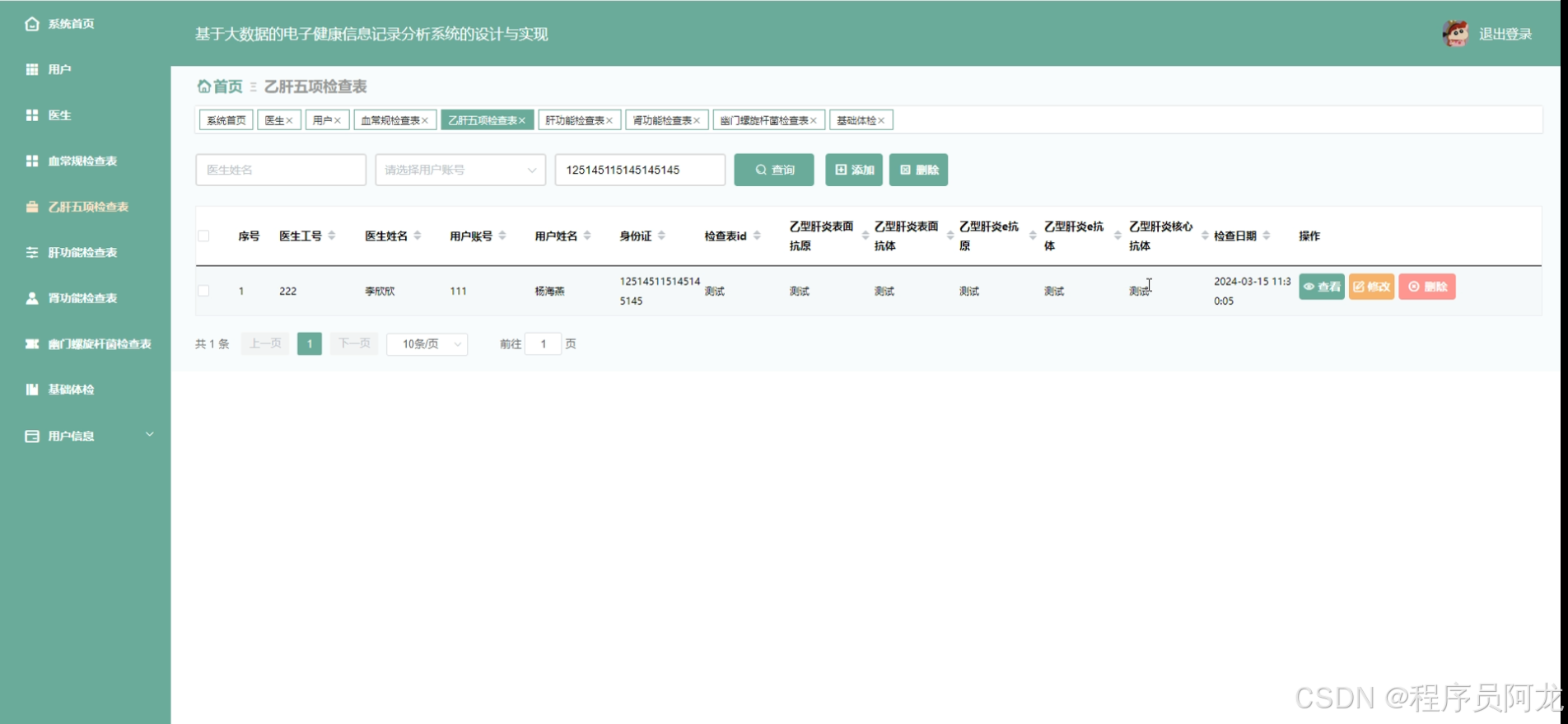

HIVE核心代码介绍:
# coding: utf-8
__author__ = 'ila'
from impala.dbapi import connect
import configparser
from convert_mysql_to_hive import ConvertMySQLToHive
def hive_func(sql_list: list):
cp = configparser.ConfigParser()
cp.read('../config.ini', encoding="utf-8")
dbName = cp.get("sql", "db")
cv = ConvertMySQLToHive(dbName)
for sql_str in sql_list:
hive_list = cv.convert_mysql_to_hive(sql_str)
if len(hive_list) > 0:
hive_execute(hive_list)
def hive_execute(hive_list: list):
try:
conn = connect(host='127.0.0.1', port=10086, user="", password="",timeout=1)
except Exception as e:
print(f"{hive_execute} error : {e}")
return
cur = conn.cursor()
for hive_sql in hive_list:
try:
cur.execute(hive_sql)
except Exception as e:
print("Exception======>", e)
print("hive_sql=====>", hive_sql)
conn.close()
数据处理核心代码:
# coding: utf-8
__author__ = 'ila'
import configparser
from hdfs.client import Client
def upload_to_hdfs(filename):
try:
port = 50070
cp = configparser.ConfigParser()
cp.read('config.ini',encoding="utf-8")
client = Client(f"http://{cp.get('sql','host')}:{port}/")
user_dir = "tmp"
client.upload(hdfs_path=f'/{user_dir}/{filename}', local_path=filename, chunk_size=2 << 19, overwrite=True)
except Exception as e:
print(f'upload_to_hdfs eror : {e}')Spark数据处理函数:
# coding: utf-8
__author__ = 'ila'
import json
from flask import current_app as app
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.sql import SparkSession
def spark_read_mysql(sql, json_filename):
'''
排序
:param sql:
:param json_filename:
:return:
'''
df = app.spark.read.format("jdbc").options(url=app.jdbc_url,
dbtable=sql).load()
count = df.count()
df_data = df.toPandas().to_dict()
json_data = []
for i in range(count):
temp = {}
for k, v in df_data.items():
temp[k] = v.get(i)
json_data.append(temp)
with open(json_filename, 'w', encoding='utf-8') as f:
f.write(json.dumps(json_data, indent=4, ensure_ascii=False))
def linear(table_name):
'''
回归
:param table_name:
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
training = spark.read.format("libsvm").table(table_name)
lr = LinearRegression(maxIter=20, regParam=0.01, elasticNetParam=0.6)
lrModel = lr.fit(training)
trainingSummary = lrModel.summary
print("numIterations: %d" % trainingSummary.totalIterations)
print("objectiveHistory: %s" % str(trainingSummary.objectiveHistory))
trainingSummary.residuals.show()
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("r2: %f" % trainingSummary.r2)
result = trainingSummary.residuals.toJSON()
spark.stop()
return result
def cluster(table_name):
'''
聚类
:param table_name:
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
dataset = spark.read.format("libsvm").table(table_name)
kmeans = KMeans().setK(2).setSeed(1)
model = kmeans.fit(dataset)
centers = model.clusterCenters()
for center in centers:
print(center)
return centers
def selector(table_name, Cols):
'''
分类
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
data = spark.read.table(table_name)
assembler = VectorAssembler(inputCols=Cols, outputCol="features")
data = assembler.transform(data).select("features", "label")
train_data, test_data = data.randomSplit([0.7, 0.3], seed=0)
lr = LogisticRegression(featuresCol="features", labelCol="label")
model = lr.fit(train_data)
predictions = model.transform(test_data)
return predictions.toJSON()

《基于大数据的电子健康信息记录分析系统的设计与实现》是一个非常有意义的项目,涉及到电子健康信息的管理与分析。系统的目的是收集和分析大量健康数据,以帮助医疗决策、疾病预防和健康管理。以下是你提到的技术栈的详细介绍,并解释这些技术在该系统中的应用:
1. 开发语言:Python
Python是一种广泛使用的高级编程语言,尤其适用于数据分析、机器学习和Web开发。对于电子健康信息记录分析系统,Python可以方便地处理大数据,利用数据分析库(如Pandas、NumPy)进行健康数据的处理、统计分析和模式挖掘。此外,Python的简单语法使得开发过程更加高效,能够快速实现复杂的功能。
2. 框架:Flask
Flask是一个轻量级的Web应用框架,它以简单、灵活为特点,适合快速开发小型到中型的Web应用。在该系统中,Flask负责处理用户请求、与数据库交互、提供API接口等功能。Flask的模块化特性使得你能够根据需要逐步添加不同的功能模块,并且由于Flask不带太多预设的复杂功能,非常适合用来构建定制化的健康信息分析平台。
3. Python版本:3.7.7
你选择的Python 3.7.7版本支持较多的现代特性,包括异步编程、类型注解等,同时与许多数据科学相关库兼容良好。在这个版本下,你可以使用Python中的现代库,确保系统的稳定性和高效性。
4. 数据库:MySQL 5.7
MySQL是一个广泛使用的开源关系型数据库管理系统,适用于存储和管理电子健康信息。MySQL 5.7版本提供了许多性能提升和新的功能(如JSON支持),可以帮助高效地存储和查询大量的健康数据。在系统中,MySQL将负责存储用户的健康记录、诊断信息、医疗历史等数据。
5. 数据库工具:Navicat 11
Navicat是一个非常强大的数据库管理工具,支持MySQL数据库的设计、管理和查询。它具有图形化界面,简化了数据库表结构的创建、数据的管理和SQL查询的执行。使用Navicat 11,可以帮助你在开发过程中更高效地进行数据的操作和调试。
6. 开发软件:PyCharm
PyCharm是一个专为Python开发设计的IDE,提供了丰富的功能,如智能代码提示、调试工具、版本控制集成、虚拟环境支持等。使用PyCharm开发Flask应用程序可以提高开发效率,特别是在处理Python代码时,PyCharm的强大功能会帮助你快速定位问题并提升代码质量。
7. 浏览器:谷歌浏览器
谷歌浏览器(Chrome)是开发过程中常用的Web浏览器,因其开发者工具的强大功能而广受开发者喜爱。你可以利用Chrome的开发者工具来调试前端页面、查看请求和响应、检查WebSocket连接等。对于系统的Web界面,Chrome可以帮助你高效地进行性能测试和错误排查。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











