









目录
8-1 HBase的安装与简单操作
第1关:Hbase数据库的安装
相关知识
在安装HBase之前你需要先安装Hadoop和Zookeeper,如果你还没有安装可以通过这两个实训来学习:Hadoop安装与配置,Zookeeper安装与配置。 本次实训的环境已经默认安装好了Hadoop,接下来我们就开始安装配置HBase吧。
HBase安装
HBase的安装也分为三种,单机版、伪分布式、分布式;我们先来安装单机版。
单机版安装
首先我们去官网下载好HBase的安装包;
接下来,将压缩包解压缩到你想安装的目录(安装包在平台已经下载好了,在/opt目录下,无需你再进行下载,我们统一将HBase解压到/app目录下):
mkdir /app
cd /opt
ulimit -f 1000000
tar -zxvf hbase-2.1.1-bin.tar.gz -C /app
安装单机版很简单,我们只需要配置JDK的路径即可,我们将JDK的路径配置到conf/下的hbase-env.sh中。
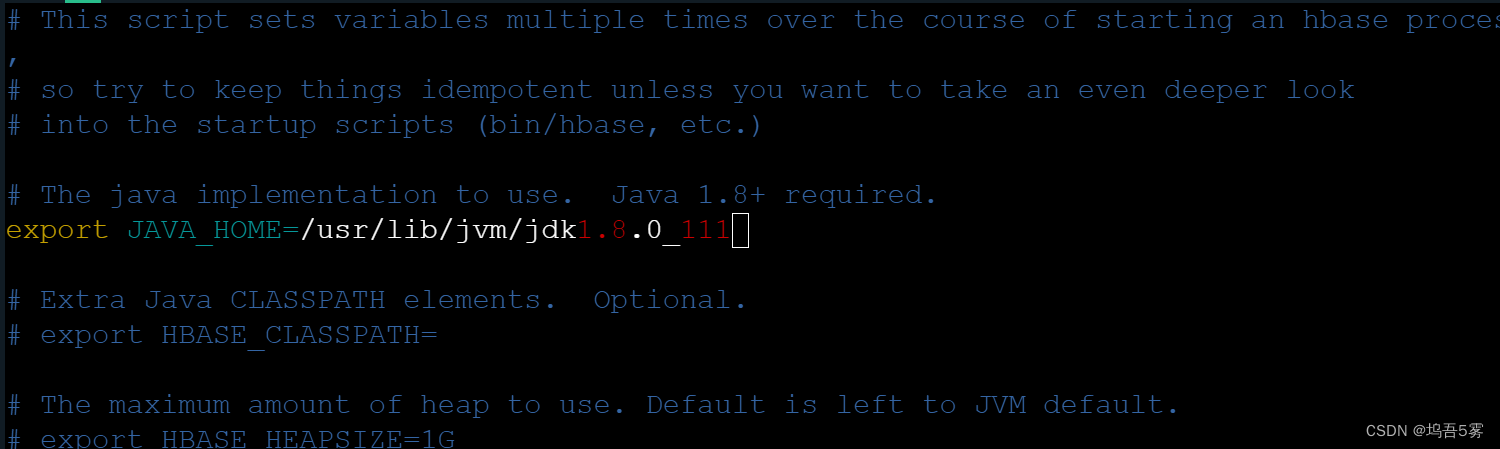
我们先输入echo $JAVA_HOME来复制JAVA_HOME的路径,以方便之后的配置;
接着我们编辑`HBase conf`目录下的`hbase-env.sh`文件,将其中的`JAVA_HOME`指向到你`Java`的安装目录,最后保存设置:

然后编辑hbase-site.xml文件,在<configuration>标签中添加如下内容:
![]()
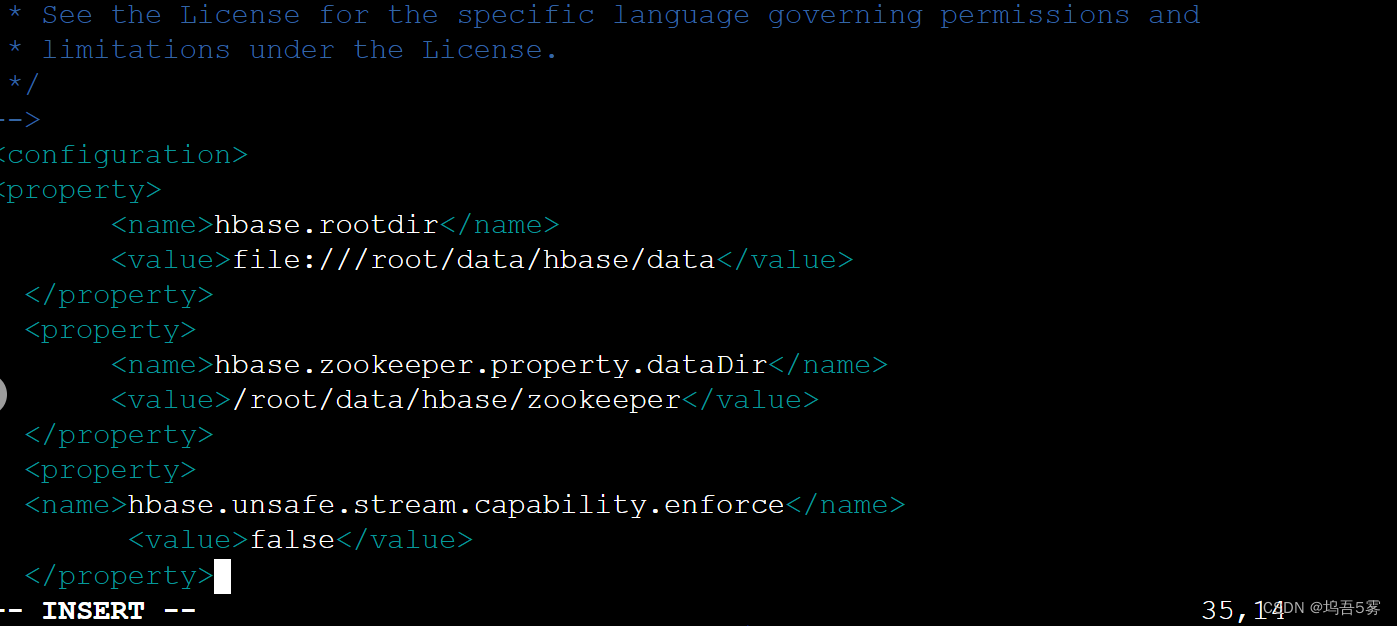
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///root/data/hbase/data</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/root/data/hbase/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>以上各参数的解释:
hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase。URL需要是'完全正确'的,还要包含文件系统的scheme。例如,要表示hdfs中的/hbase目录,namenode运行在namenode.example.org的9090端口。则需要设置为hdfs://namenode.example.org:9000 /hbase。默认情况下Hbase是写到/tmp的。不改这个配置,数据会在重启的时候丢失;
hbase.zookeeper.property.dataDir:ZooKeeper的zoo.conf中的配置。快照的存储位置,默认是:${hbase.tmp.dir}/zookeeper;
hbase.unsafe.stream.capability.enforce:控制HBase是否检查流功能(hflush / hsync),如果您打算在rootdir表示的LocalFileSystem上运行,那就禁用此选项。
配置好了之后我们就可以启动HBase了,在启动之前我们可以将Hbase的bin目录配置到/etc/profile中,这样更方便我们以后操作。 在etc/profile的文件末尾添加如下内容:
# SET HBASE_enviroment
HBASE_HOME=/app/hbase-2.1.1
export PATH=$PATH:$HBASE_HOME/bin
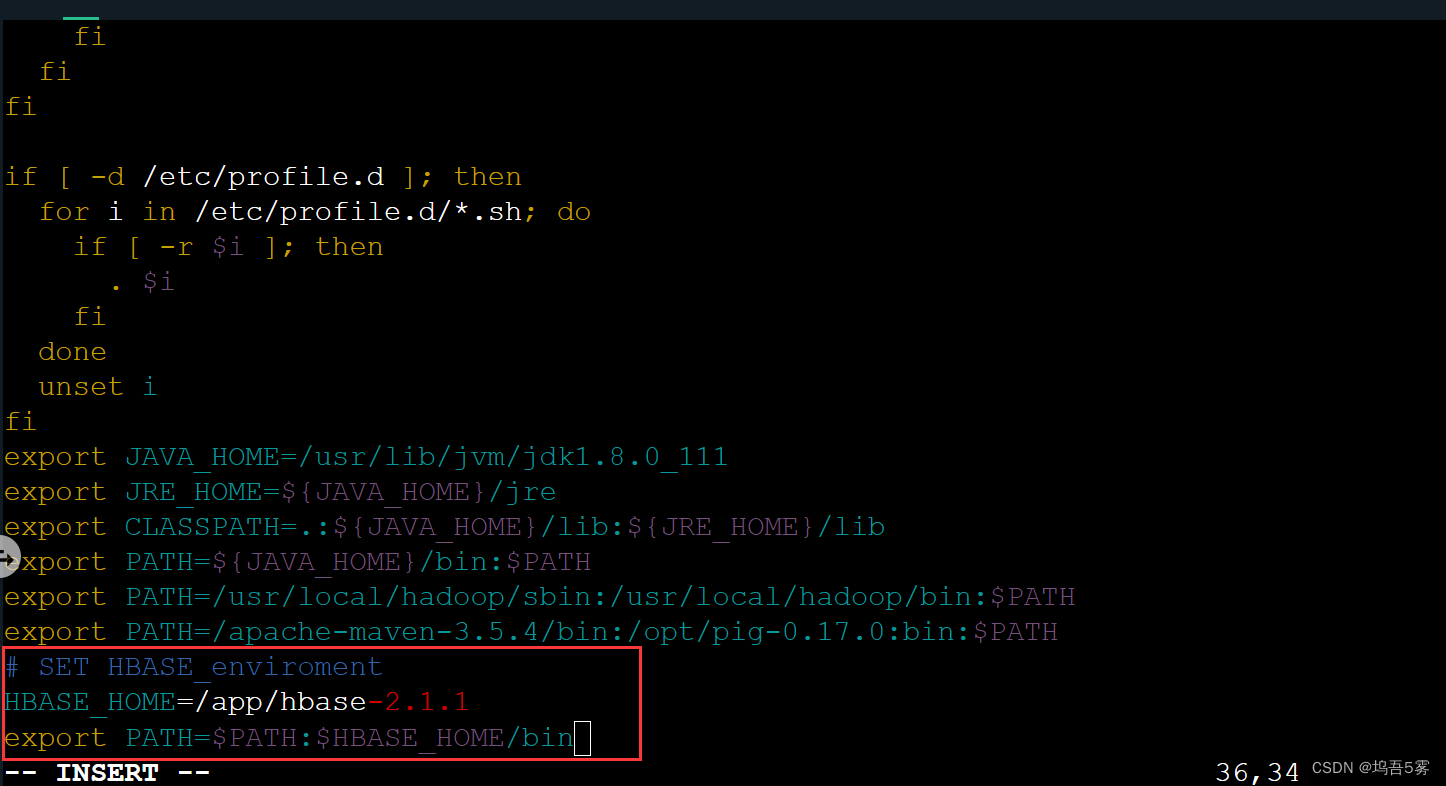
HBASE_HOME为你自己本机Hbase的地址。
不要忘了,source /etc/profile使刚刚的配置生效。
![]()
接下来我们就可以运行HBase来初步的体验它的功能了:
在命令行输入start-hbase.sh来启动HBase,接着输入jps查看是否启动成功,出现了HMaster进程即表示启动成功了。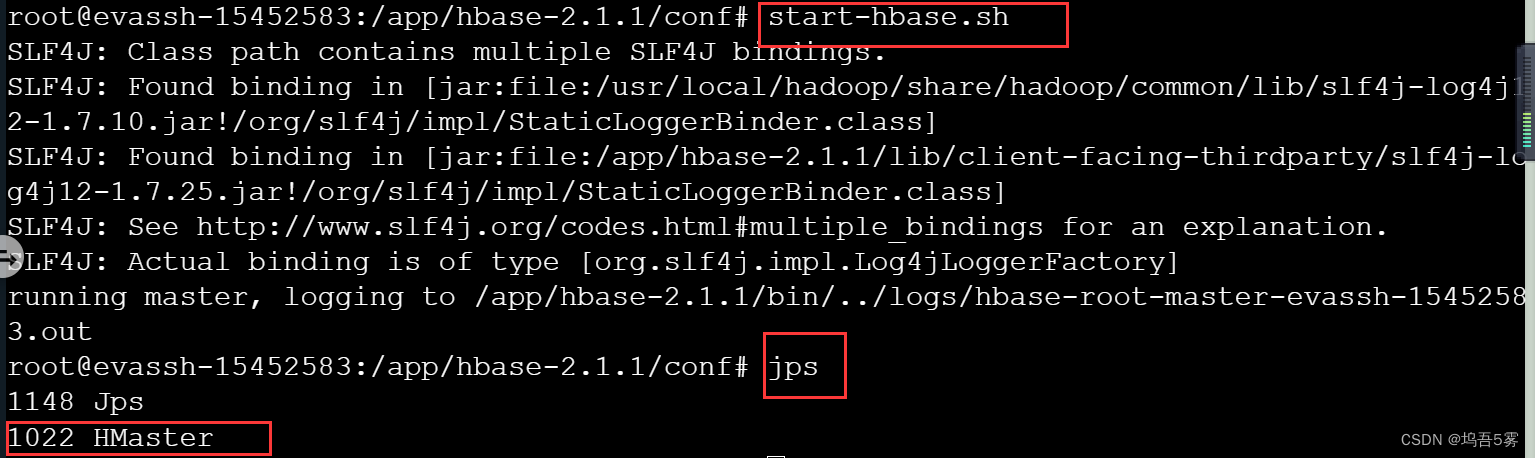
启动成功之后,咱们就可以对Hbase进行一些基本的操作了。
在之后的实训中,我们将会实现伪分布式与分布式HBase数据库的安装。
第2关:创建表
Hbase shell操作
启动HBase之后,我们输入hbase shell进入到Hbase shell命令行窗口:
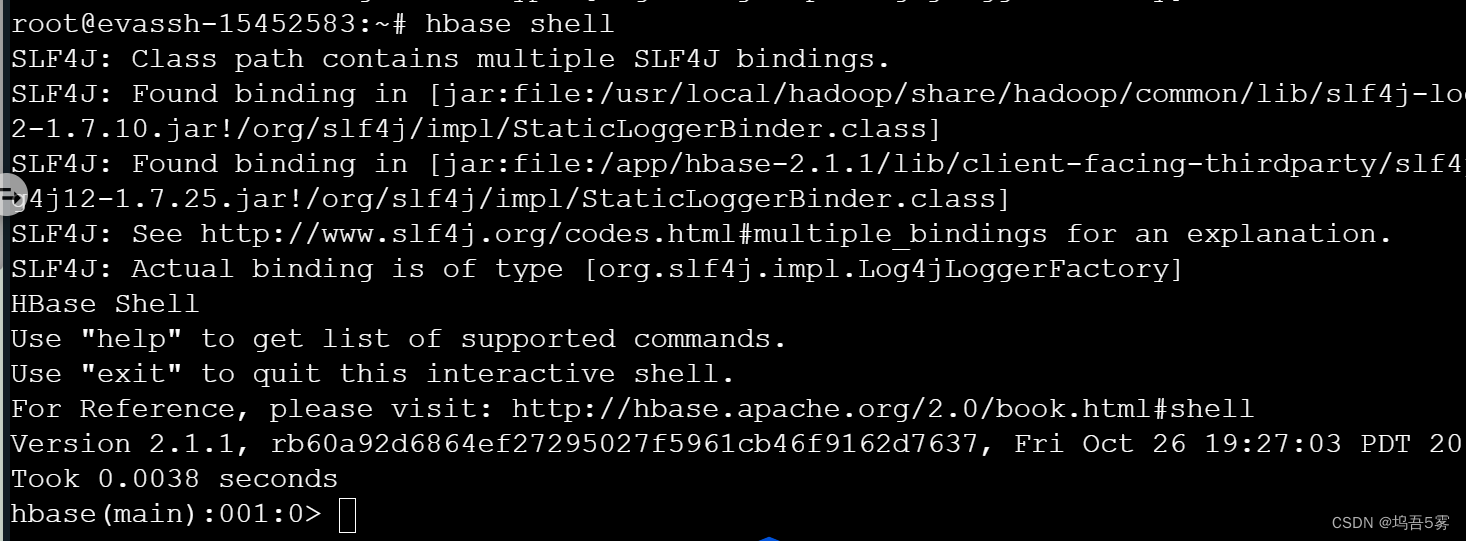
在这里我们输入hbase shell会启动一个加入了一些Hbase特有命令的JRuby JRB解释器,输入help然后按回车键可以查看已分组的shell环境的命令列表。
现在,我们来创建一个简单的表。
要新建一个表,首先必须要给它起个名字,并为其定义模式,一个表的模式包含表的属性和列族的列表。
例如:我们想要新建一个名为test的表,使其中包含一个名为data的列,表和列族属性都为默认值,则可以使用如下命令:
创建完毕之后我们可以输入list来查看表是否创建成功: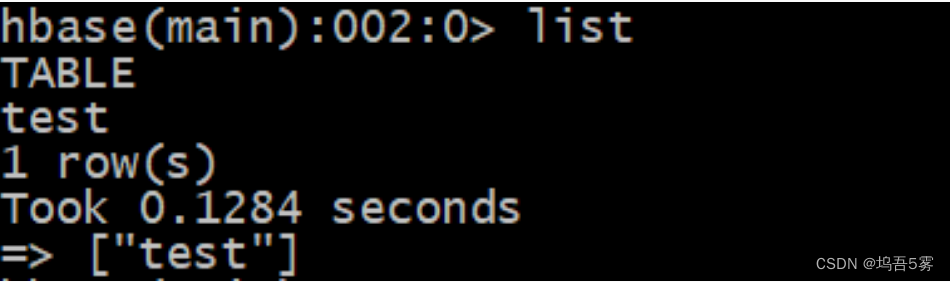
编程要求
好了,该你了,依照上文步骤创建test表,然后继续在HBase中创建两张表,表名分别为:dept,emp,列都为:data。
create 'dept','data'
create 'emp','data'第3关:添加数据、删除数据、删除表
添加数据
我们来给上一关创建的test表的列data添加一些数据:
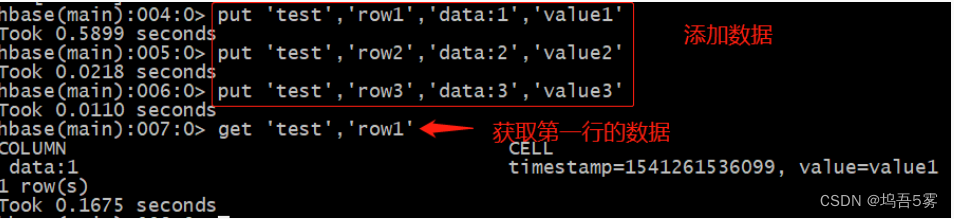
从上面例子我们可以看出,使用put命令可以用来添加数据,使用get命令可以获取数据。
当然我们肯定还会有一个需求:查看所有的数据。

输入scan命令就可以查看所有的数据了。
删除数据、删除表
我们经常会添加错数据,想要删除然后重新添加应该怎么做呢?
删除整行数据:
deleteall 'test','row1'指令:deleteall 表名,行名称 即可删除整行数据。有时候我们还想将创建好的表删除,怎么做呢?
为了移除test这个表,首先我们要把它设为禁用,然后在删除:
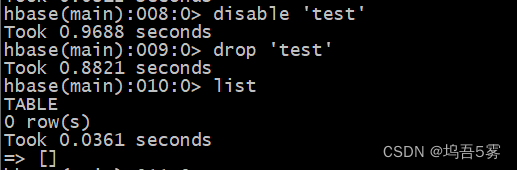
可以发现删除表需要两个步骤:
disable 表名
drop 表名接着我们ctrl + c或者 输入exit退出HBase shell命令行。
编程要求
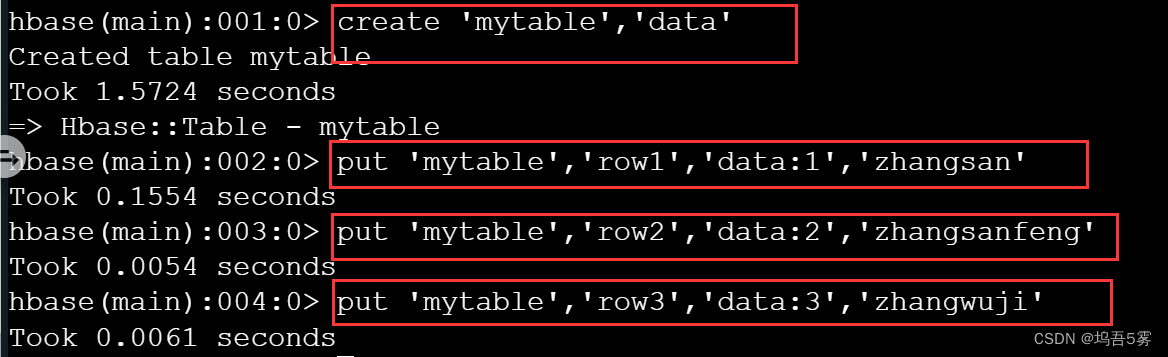
好了,到你啦,在HBase中创建表mytable,列为data,并在列族data中添加三行数据:
- 行号分别为:
row1,row2,row3; - 列名分别为:
data:1,data:2,data:3; - 值分别为:
zhangsan,zhangsanfeng,zhangwuji。
8-2 HBase 伪分布式环境搭建
第1关:伪分布式环境搭建
本关任务:安装伪分布式HBase。
相关知识
上次实训中我们已经完成了单机版HBase的安装,单机版意味着我们的HBase数据仍然是存放在本地,而没有存放在Hadoop集群中,本关我们来学习如何配置一个伪分布式的HBase环境,伪分布式意味着HBase仍然在单个主机上运行,但每个HBase的守护程序(HMaster、HRegionServer和Zookeeper)作为单独的进程运行;在伪分布式的环境下,我们会将HBase的数据存储在HDFS中,而不是存放在本地了,接下来我们就来一起搭建环境吧。
实验环境:
hadoop2.7; JDK8; HBase2.1.1; hadoop已安装; JDK已安装,环境变量已配置; HBase压缩包已下载,存放在/opt目录下。
在搭建环境之前我们首先来了解一下HBase分布式环境的整体架构:
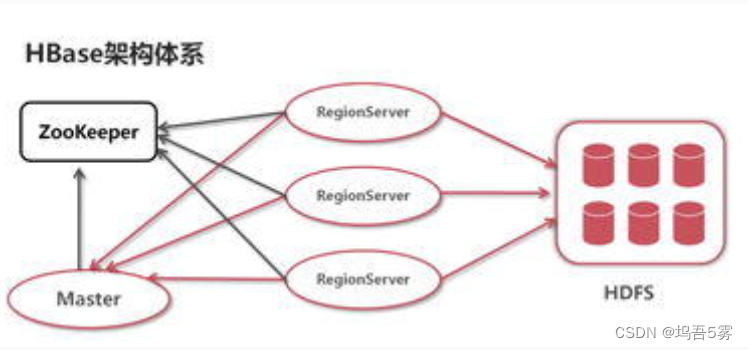
我们来简单认识一下与HBase的相关组件:
Zookeeper:
Zookeeper能为HBase提供协同服务,是HBase的一个重要组件,Zookeeper能实时的监控HBase的健康状态,并作出相应处理。
HMaster:
HMaster是HBase的主服务,他负责监控集群中所有的HRegionServer,并对表和Region进行管理操作,比如创建表,修改表,移除表等等。
HRegion:
HRegion是对表进行划分的基本单元,一个表在刚刚创建时只有一个Region,但是随着记录的增加,表会变得越来越大,HRegionServer会实时跟踪Region的大小,当Region增大到某个值时,就会进行切割(split)操作,由一个Region切分成两个Region。
HRegionServer:
HRegionServer是RegionServer的实例,它负责服务和管理多个HRegion 实例,并直接响应用户的读写请求。
总的来说,要部署一个分布式的HBase数据库,需要各个组件的协作,HBase通过Zookeeper进行分布式应用管理,Zookeeper相当于管理员,HBase将数据存储在HDFS(分布式文件系统)中,通过HDFS存储数据,所以我们搭建分布式的HBase数据库的整体思路也在这里,即将各个服务进行整合。
接下来,我们就一起来搭建一个伪分布式的HBase。
配置与启动伪分布式HBase
如果你已经完成了单节点HBase的安装,那伪分布式的配置对你来说应该很简单了,只需要修改hbase-site.xml文件即可:(前面的步骤还是和8-1第一关一样,只是以下这些地方有所改动)

vim /app/hbase-2.1.1/conf/hbase-site.xml在这里主要有两项配置:
1.开启HBase的分布式运行模式,配置hbase.cluster.distributed为true代表开启HBase的分布式运行模式:
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>2.是设置HBase的数据文件存储位置为HDFS的/hbase目录,要注意的是在这里我们不需要在HDFS中手动创建hbase目录,因为HBase会帮我们自动创建。
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>修改之后hbase-site.xml的<configuration>代码:
标红部分为我们需要注意的配置。我们在设置单节点的时候将hbase.unsafe.stream.capability.enforce属性值设置为了false,在这里我们需要注意设置它的值为true,或者干脆删除这个属性也是可以的。
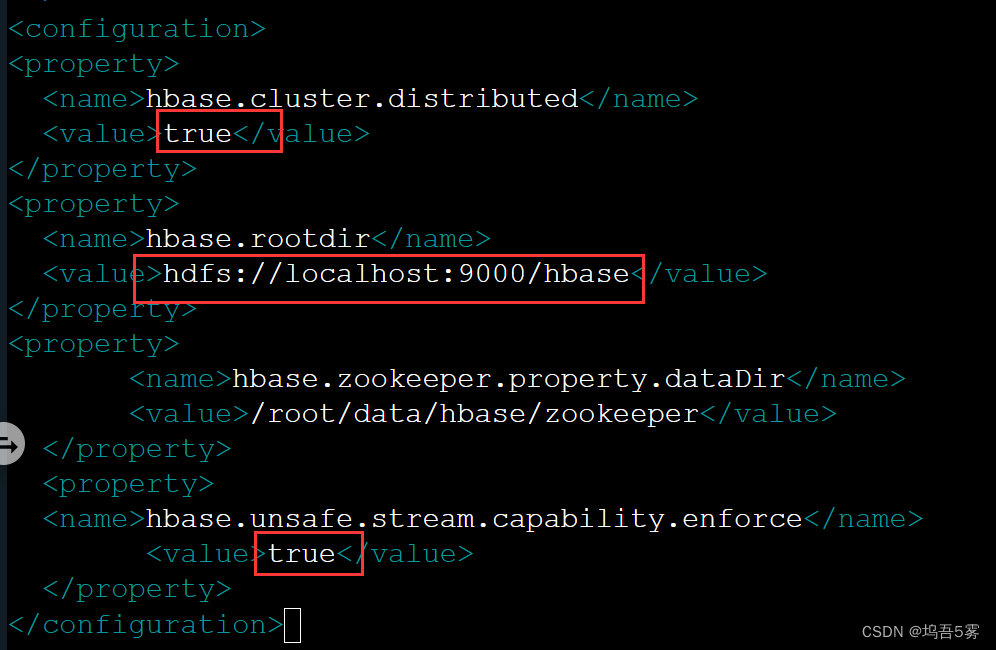
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/root/data/hbase/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>true</value>
</property>
</configuration>配置完成之后(/etc/profile也要配置,参照上面8-1第一关,凡是报错就去看一下8-1第一关是不是有哪一步漏掉了),我们需要先启动Hadoop,然后启动HBase,最后输入jps查看启动的进程:
 如果出现
如果出现HMaster和HRegionServer以及HQuorumPeer三个服务则代表伪分布式环境已经搭建成功。
start-dfs.sh #启动Hadoop
start-hbase.sh #启动hbase
jps
在HDFS中验证
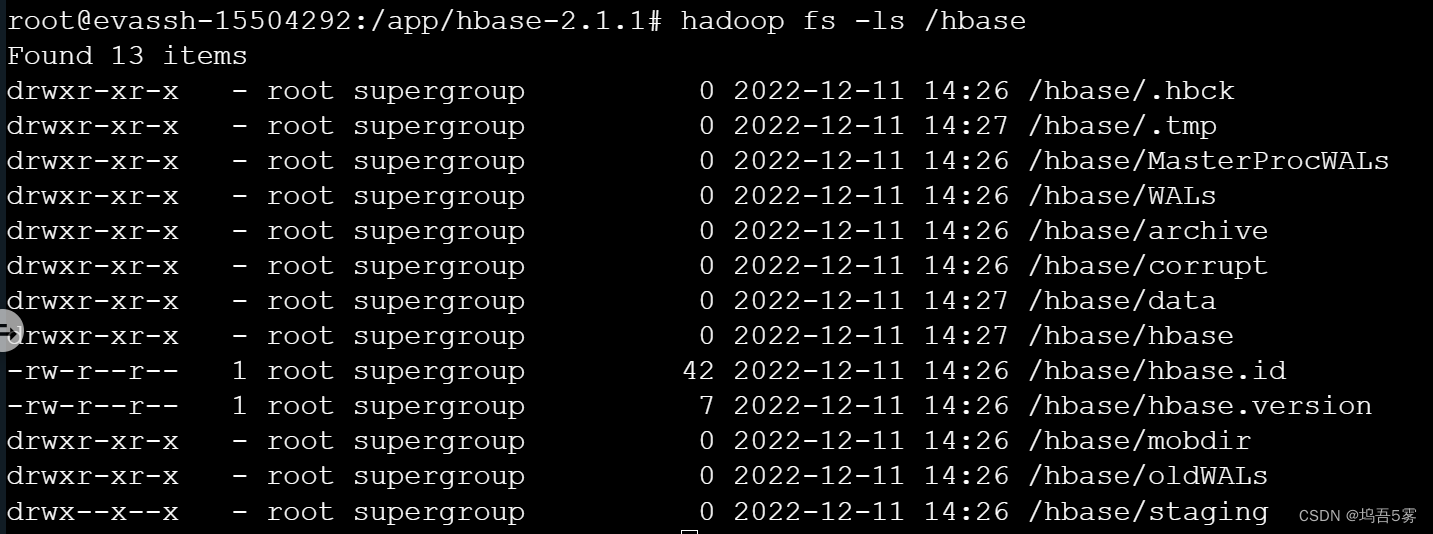
接下来我们进一步验证:在HDFS中检查HBase文件。
如果一切正常,HBase会在HDFS中自动建立自己的文件,在上述配置文件中,设置的文件位置为/hbase,我们输入hadoop fs -ls /hbase即可查看,如下图所示,分布式文件系统(HDFS)中hbase文件夹已经创建了:
编程要求
好了,到你啦,你需要先按照上次实训——HBase单节点安装的方式将HBase安装在/app目录下,然后根据本关知识配置好伪分布式的HBase,这里需要重启hbase服务:先stop-hbase.sh stop-dfs.sh,然后再重新启动hdfs和hbase,最后点击测评即可通关。
Victory!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









