









“如何能让软件拥有更高的性能?”我想这是一个大部分开发者都思考过的问题。性能往往决定了一个软件的质量,如果你开发的是一个互联网产品,那么你的产品性能将更加受到考验,因为你面对的是广大的互联网用户,他们可不是那么有耐心的。严重点说,页面的加载速度每增加一秒也许都会使你失去一部分用户,也就是说,加载速度和用户量是成反比的。那么用户能够接受的加载速度到底是多少呢?
如果页面加载时间超过 10s 那么用户就会离开,如果 1s--10s 的话就需要有提示,但如果我们的页面没有提示的话需要多快的加载速度呢?是的,1s 。
当然,这是站在一个产品经理的角度来说的,但如果站在一个技术人员的角度来说呢?加载速度和用户量就是成正比的,你的用户数量越多需要处理的数据当然也就越多,加载速度当然也就越慢。这是一件很有趣的事,所以如果你的产品如果是一件激动人心的产品,那么作为技术人员你需要做的事就是让软件的性能和用户的数量同时增长,甚至性能增长要快于用户量的增长。
数据库性能对软件整体性能的影响是不言而喻的,那么,当我们使用 MongoDB 时改如何提高数据库性能呢?
目录
第1关:MongoDB 查询优化原则
查询优化原则
-
在查询条件、排序条件、统计条件的字段上选择创建索引,可以显著提高查询效率;
-
用 $or 时把匹配最多结果的条件放在最前面,用 $and 时把匹配最少结果的条件放在最前面;
-
使用 limit() 限定返回结果集的大小,减少数据库服务器的资源消耗,以及网络传输的数据量;
-
尽量少用 $in,而是分解成一个一个的单一查询。尤其是在分片上,$in 会让你的查询去每一个分片上查一次,如果实在要用的话,先在每个分片上建索引;
-
尽量不用模糊匹配查询,用其它精确匹配查询代替,比如 $i 、$nin;
-
查询量大、并发大的情况,通过前端加缓存解决;
-
能不用安全模式的操作就不用安全模式,这样客户端没必要等待数据库返回查询结果以及处理异常,快了一个数量级;
-
MongoDB 的智能查询优化,判断粒度为 query 条件,而 skip 和 limit 都不在其判断之中,当分页查询最后几页时,先用 order 反向排序;
-
尽量减少跨分片查询,balance 均衡次数少;
-
只查询要使用的字段,而不查询所有字段;
-
更新字段的值时,使用 $inc 比 update 效率高;
-
apped collections 比普通 collections 的读写效率高;
-
server-side processing 类似于 SQL 查询的存储过程,可以减少网络通讯的开销;
-
必要时使用 hint() 强制使用某个索引查询;
-
如果有自己的主键列,则使用自己的主键列作为 id,这样可以节约空间,也不需要创建额外的索引;
-
使用 explain ,根据 exlpain plan 进行优化;
-
范围查询的时候尽量用 $in、$nin 代替;
-
查看数据库查询日志,具体分析的效率低的操作;
-
mongodb 有一个数据库优化工具 database profiler,能够检测数据库操作的性能。可以发现 query 或者 write 操作中执行效率低的,从而针对这些操作进行优化;
-
尽量把更多的操作放在客户端,当然这就是 mongodb 设计的理念之一。
测试说明
1、以下哪些优化原则是正确的:
A、用$or和$and时把匹配最多结果的条件放在最前面。
B、尽量用$in,尤其是在分片上。
C、在查询条件、排序条件、统计条件的字段上选择创建索引,可以显著提高查询效率。
D、使用limit()限定返回结果集的大小,减少数据库服务器的资源消耗,以及网络传输的数据量。
2、以下哪些优化原则是正确的:
A、MongoDB的智能查询优化,判断粒度为query条件,而skip和limit都不在其判断之中,当分页查询最后几页时,先用order反向排序。
B、查询时查询所有字段。
C、多使用模糊匹配进行查询
D、尽量减少跨分片查询,balance均衡次数少。
3、以下哪些优化原则是正确的:
A、用$or时把匹配最多结果的条件放在最前面,用$and时把匹配最少结果的条件放在最前面。
B、最好不要使用hint()强制使用某个索引查询。
C、尽量不用模糊匹配查询,用其它精确匹配查询代替,比如$in、$nin。
D、尽量把更少的操作放在客户端。
4、以下哪些优化原则是正确的:
A、尽量少用$in,而是分解成一个一个的单一查询。尤其是在分片上,$in会让你的查询去每一个分片上查一次,如果实在要用的话,先在每个分片上建索引。
B、使用explain,根据exlpain plan进行优化。
C、更新字段的值时,使用update比$inc效率高。
D、只查询要使用的字段,而不查询所有字段。5、以下哪些优化原则是正确的:
A、collections比普通apped collections的读写效率高。
B、能不用安全模式的操作就不用安全模式,这样客户端没必要等待数据库返回查询结果以及处理异常,快了一个数量级。
C、查询量大、并发大的情况,通过前端加缓存解决。
D、如果有自己的主键列,则使用自己的主键列作为id,这样可以节约空间,也不需要创建额外的索引。6、以下哪些优化原则是正确的:
A、范围查询的时候尽量用$in、$nin代替。
B、必要时使用hint()强制使用某个索引查询。
C、mongodb有一个数据库优化工具database profiler,能够检测数据库操作的性能。可以发现query或者write操作中执行效率低的,从而针对这些操作进行优化。
D、更新字段的值时,使用$inc比update效率高。
7、以下哪些优化原则是正确的:
A、尽量使用模糊匹配进行查询。
B、尽量多使用跨分片查询。
C、server-side processing类似于SQL查询的存储过程,可以减少网络通讯的开销。
D、查看数据库查询日志,具体分析的效率低的操作。8、以下哪些优化原则是正确的:
A、尽量把更多的操作放在客户端,当然这就是mongodb设计的理念之一。
B、尽量多用$in,尤其是在分片上。
C、尽量不要使用hint()强制使用某个索引查询。
D、apped collections比普通collections的读写效率高。






第2关:MongoDB 的 Profiling 工具(一)
一、本关任务:完成慢查询设置。
二、相关知识
为了完成本关任务,你需要掌握:
1.Profiling 是什么工具; 2.如何启用 Profiling 工具。
Profiling 工具
在很多情况下, DBA(数据库管理员)都要对数据库的性能进行分析处理,找出降低性能的根源。而 Profiling 就是 Mongo 自带的一种分析工具来检测并追踪影响性能的慢查询。
慢查询日志一般作为优化步骤里的第一步。通过慢查询日志,定位每一条语句的查询时间。比如超过了50ms,那么查询超过50ms 的语句需要优化。然后它通过 .explain() 解析影响行数是不是过多,所以导致查询语句超过50ms。
所以优化步骤一般就是:
-
用慢查询日志(system.profile)找到超过50ms 的语句;
-
然后再通过 .explain() 解析影响行数,分析为什么超过50ms;
-
决定是不是需要添加索引。
Profiling 级别说明:
-
0:关闭,不收集任何数据;
-
1:收集慢查询数据,默认是100毫秒;
-
2:收集所有数据。
启用 Profiling 工具
Profiling 有两种开启方式,一种是启动服务时配置启动,一种是 mongoshell 中进行实时配置。
mongo shell 中启动配置
-
查看状态,如图所示:级别和时间;

-
查看级别,如图所示:

-
设置级别,如图所示:

-
设置级别和时间,如图所示:

注意:
-
以上要操作要是在 test 集合下面的话,只对该集合里的操作有效,要是需要对整个实例有效,则需要在所有的集合下设置或则在开启的时候开启参数;
-
每次设置之后返回给你的结果是修改之前的状态(包括级别、时间参数)。
全局开启 Profiling
-
可以在 mongod 启动时加上以下参数:
mongod --profile=1 --slowms=50 -
或在配置文件里添加两行,如下所示:
profile = 1 slowms = 50
关闭 Profiling 工具
只需要将收集慢查询数据的时间设置为0就可以关闭,如图所示:

编程要求
根据提示,在右命令行进行操作,在 mydb 数据库中开启 Profiling,设置级别为1,时间为50ms。
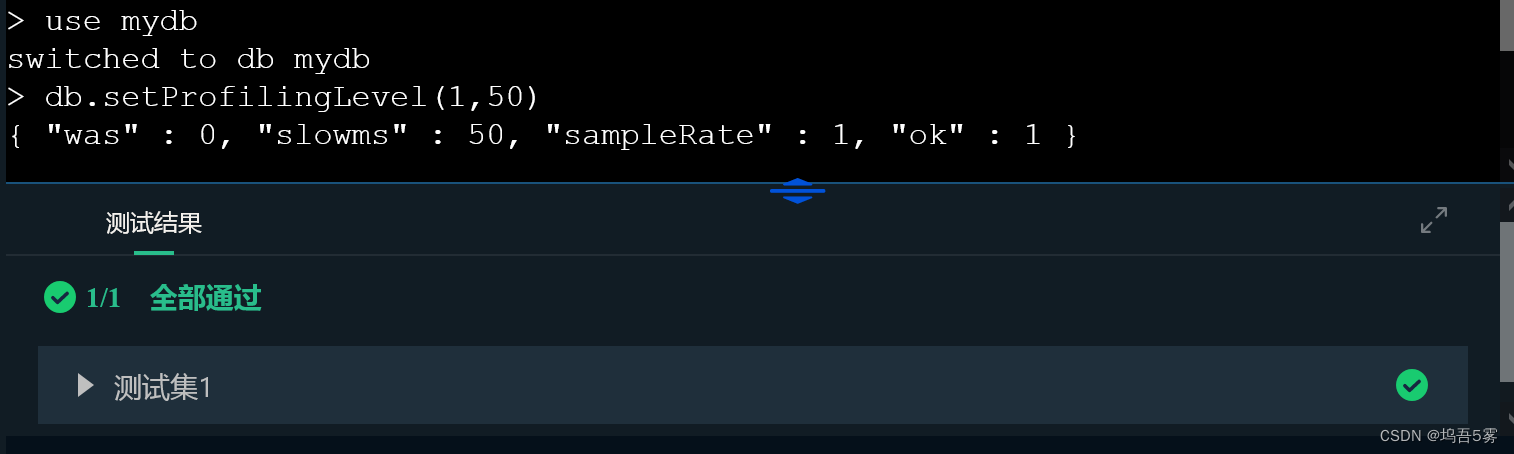
> use mydb
switched to db mydb
> db.setProfilingLevel(1,50)
{ "was" : 0, "slowms" : 50, "sampleRate" : 1, "ok" : 1 }第3关:MongoDB 的 Profiling 工具(二)
一、本关任务:完成慢查询设置并自行分析慢查询结果。
二、相关知识
为了完成本关任务,你需要掌握:
1.如何进行慢查询分析; 2.如何进行性能分析; 3.常用的慢日志查询命令。
慢查询分析
要进行慢查询分析,首先,要如第二关一样启用 Profiling 工具,以下例子 Profiling 级别设置为1,时间设置为50ms。其次,要进行过超过 50ms 的操作才会记录到慢查询日志中,存在记录结果。
-
首先,我们在 test 数据库启用 Profiling 工具:
use test db.setProfilingLevel(1,50) # 设置级别为1,时间为50ms,意味着只有超过50ms的操作才会记录到慢查询日志中 -
然后在 test 数据库的 items 集合中循环插入100万条数据:
> for(var i=0;i<1000000;i++)db.items.insert({_id:i,text:"Hello MongoDB"+i}) WriteResult({ "nInserted" : 1 }) //等待时间较长 -
返回所有结果:
db.system.profile.find().pretty()
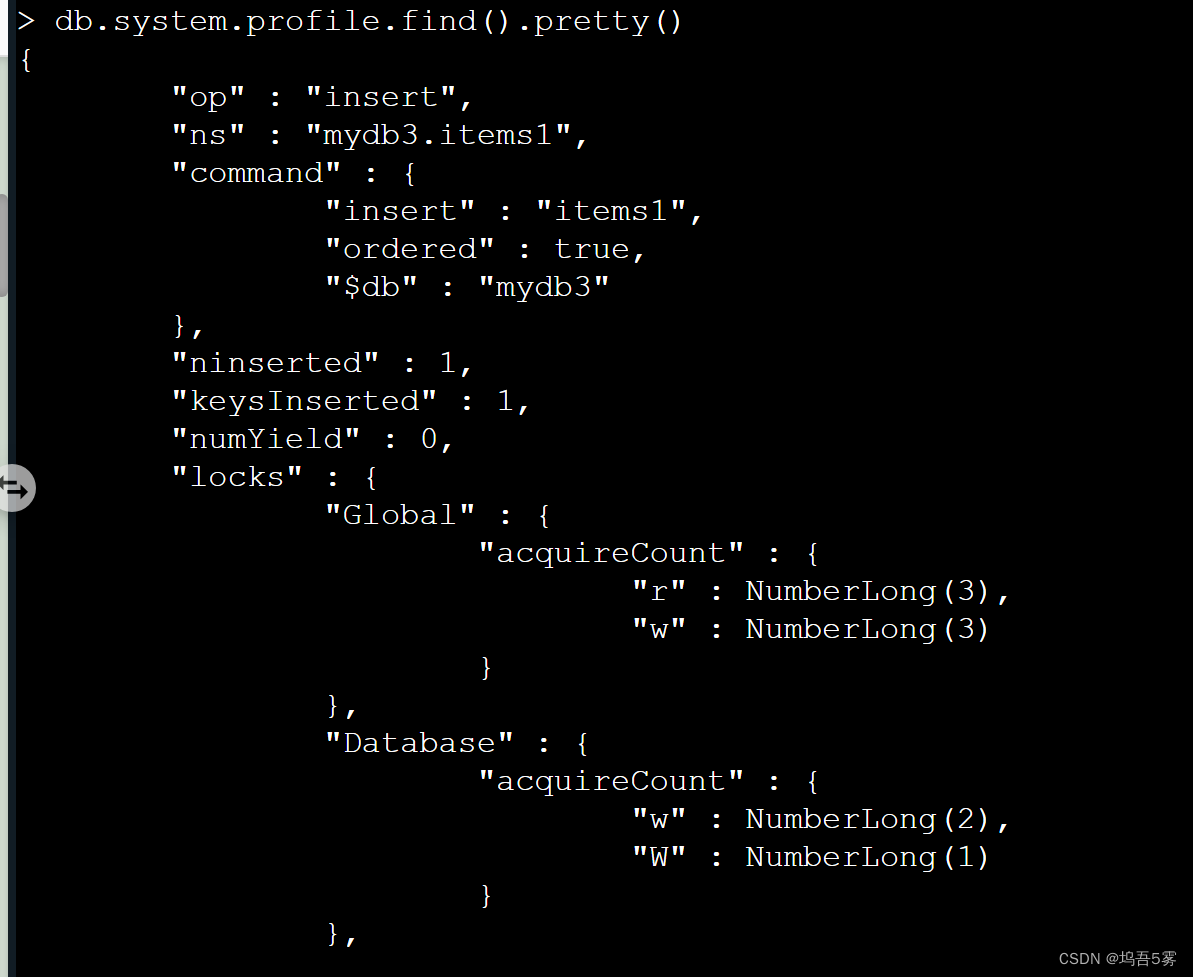
{
"op" : "insert", #操作类型,有insert、query、update、remove、getmore、command
"ns" : "test.items", #操作的集合
"command" : {
"insert" : "items",
"ordered" : true,
"$db" : "test"
},
"ninserted" : 1,
"keysInserted" : 1,
"numYield": 0, #该操作为了使其他操作完成而放弃的次数。通常来说,当他们需要访问还没有完全读入内存中的数据时,操作将放弃。这使得在MongoDB为了放弃操作进行数据读取的同时,还有数据在内存中的其他操作可以完成
"locks": { #锁信息,R:全局读锁;W:全局写锁;r:特定数据库的读锁;w:特定数据库的写锁
"Global" : {
"acquireCount" : {
"r" : NumberLong(1),
"w" : NumberLong(1)
}
},
"Database" : {
"acquireCount" : {
"w" : NumberLong(1)
}
},
"Collection" : {
"acquireCount" : {
"w" : NumberLong(1)
}
}
},
"responseLength" : 45, #返回字节长度,如果这个数字很大,考虑值返回所需字段
"protocol" : "op_msg",
"millis" : 60, #消耗的时间(毫秒)
"ts" : ISODate("2018-12-07T08:19:11.997Z"), #该命令在何时执行
"client" : "127.0.0.1", #链接ip或则主机
"appName" : "MongoDB Shell",
"allUsers" : [ ],
"user" : ""
}
profile 部分字段解释:
-
op :操作类型;
-
ns :被查的集合;
-
commond :命令的内容;
-
docsExamined :扫描文档数;
-
nreturned :返回记录数;
-
millis :耗时时间,单位毫秒;
-
ts :命令执行时间;
-
responseLength :返回内容长度。
常用的慢日志查询命令
自己在命令行尝试输入以下命令,分析查看返回结果:
-
返回最近的10条记录:
db.system.profile.find().limit(10).sort({ ts : -1 }).pretty() -
返回所有的操作,除 command 类型的:
db.system.profile.find( { op: { $ne : 'command'} }).pretty() -
返回特定集合:
db.system.profile.find( { ns : 'test.items' } ).pretty() -
返回大于5毫秒慢的操作:
db.system.profile.find({ millis : { $gt : 5 } } ).pretty() -
从一个特定的时间范围内返回信息:
db.system.profile.find({ts : {$gt : new ISODate("2018-12-09T08:00:00Z"),$lt : new ISODate("2018-12-10T03:40:00Z")}}).pretty() -
特定时间,限制用户,按照消耗时间排序:
db.system.profile.find({ts : {$gt : new ISODate("2018-12-09T08:00:00Z") ,$lt : new ISODate("2018-12-10T03:40:00Z")}},{ user : 0 }).sort( { millis : -1 } ).pretty() -
查看最新的 Profile 记录:
db.system.profile.find().sort({$natural:-1}).limit(1).pretty() -
显示5个最近的事件:
show profile
编程要求
在右侧命令行中,进行以下操作:
-
使用 MongoDB 的 mydb3 数据库;
-
开启并设置其慢查询日志功能,设置为模式1,时间限制为 5ms;
-
循环插入10万条数据到集合 items1 中,格式如下:
{_id:i,text:"Hello MongoDB"+i}(插入方法不记得的同学,可参考 游标 这一节内容)
-
循环插入10万条数据到集合 items2 中,格式如下:
{_id:i,text:"Hello MongoDB"+i}
> use mydb3
switched to db mydb3
> db.setProfilingLevel(1,5)
{ "was" : 0, "slowms" : 100, "sampleRate" : 1, "ok" : 1 }
> for(var i=0;i<100000;i++)db.items1.insert({_id:i,text:"Hello MongoDB"+i})
WriteResult({ "nInserted" : 1 })
> for(var i=0;i<100000;i++)db.items2.insert({_id:i,text:"Hello MongoDB"+i})
WriteResult({ "nInserted" : 1 })
以上操作计入测评,请同学们进行完以上操作后对以下几条命令进行练习(不计入测评):
-
查看最新的 Profile 记录;
-
显示最近的慢查询事件;
-
特定时间(你自己操作时间段内),按照消耗时间排序的慢查询;
-
返回大于7毫秒慢的操作;
-
返回 items1 集合的慢查询。

















 3519
3519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









