




1. 什么是RAG?
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合信息检索与文本生成的技术。通过动态检索外部知识库,RAG能够在生成过程中引入实时、准确的上下文信息,从而提升生成内容的可靠性和相关性。
与传统生成模型(如纯GPT架构)相比,RAG的核心差异在于其动态检索机制。传统模型依赖预训练时学习的静态知识,而RAG通过检索模块实时获取最新或领域特定信息,解决了模型知识滞后的问题。
RAG的优势包括:
- 知识实时性:可接入动态更新的数据库或文档。
- 可解释性:生成结果基于检索到的具体内容,便于溯源。
- 灵活性:适用于开放域问答、事实核查等需要外部知识的场景。
2. RAG 的工作原理
RAG系统由检索模块和生成模块组成。检索模块从大型文档库中筛选与输入相关的片段,生成模块则基于检索结果和原始输入生成最终内容。
检索模块通常采用稠密向量检索(如DPR)或稀疏检索(如BM25)。输入查询被编码为向量,与文档库中的向量计算相似度,返回最相关的Top-K文档片段。
生成模块将检索到的片段与原始输入拼接,输入至预训练语言模型(如GPT-3)。模型通过注意力机制融合检索内容,生成连贯且信息丰富的输出。
协同机制的关键在于:
- 检索与生成共享统一的训练目标(如负对数似然损失)。
- 端到端微调时,检索模块的参数可随生成模块一同优化。
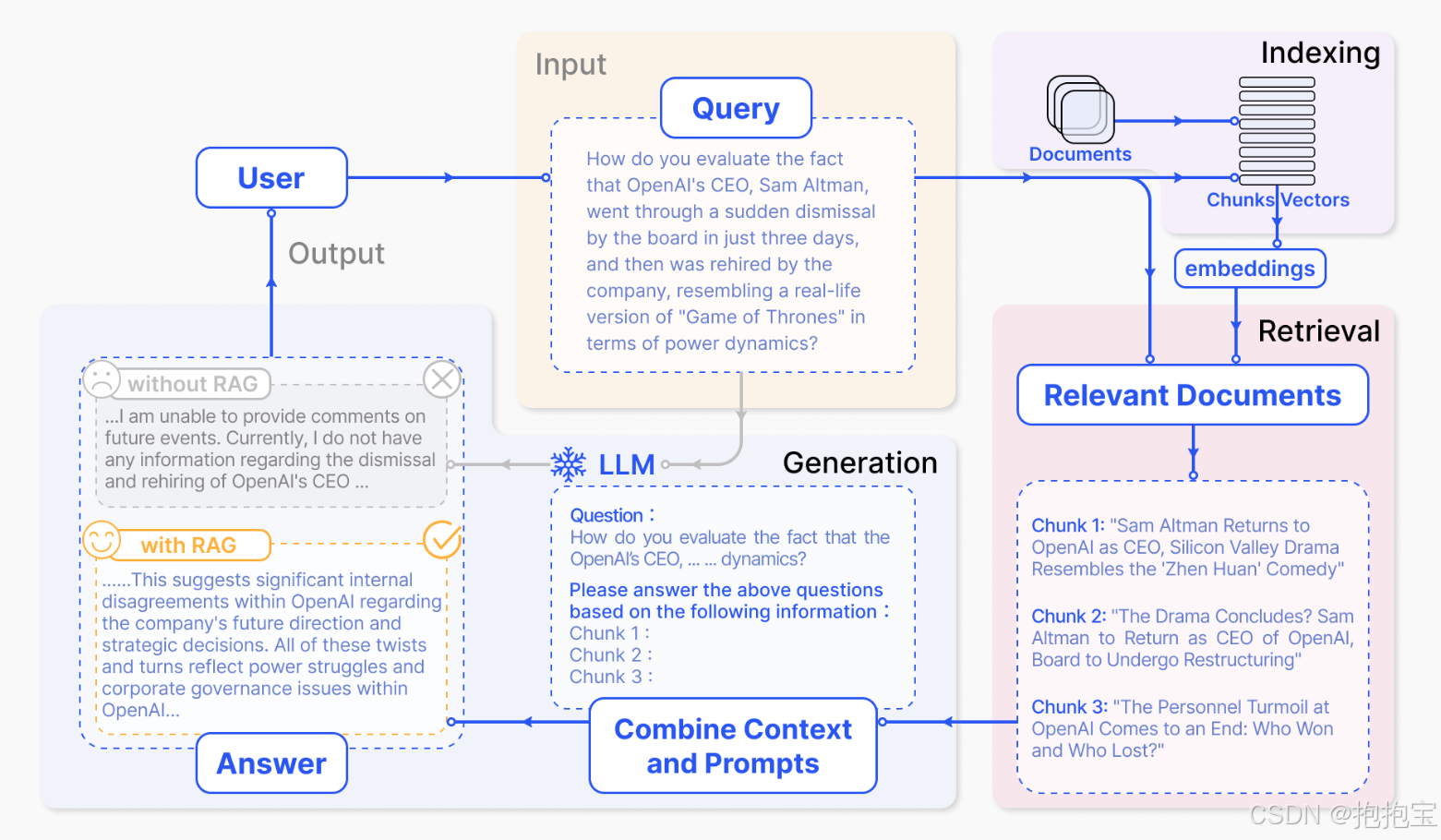
3. 构建 RAG 系统的关键技术
高效的检索方法
- 稠密检索:使用双编码器(如BERT)将查询和文档映射到同一向量空间,通过内积计算相似度。
- 公式:s(q,d)=EncoderQ(q)T⋅EncoderD(d)s(q,d) = \text{Encoder}_Q(q)^T \cdot \text{Encoder}_D(d)s(q,d)=EncoderQ(q)T⋅EncoderD(d)
- 稀疏检索:基于词频统计(如TF-IDF或BM25),适合术语明确的场景。
生成模型选择
- 通用模型:GPT系列、T5等,擅长处理多任务生成。
- 领域适配:可在特定数据上继续预训练生成模型,提升领域术语的生成质量。
数据对齐
- 检索结果需与生成任务强相关。可通过以下方式优化:
- 在训练时引入“硬负例”提升检索区分度。
- 对检索片段进行重排序(如使用Cross-Encoder)。
4. 如何实现一个简单的 RAG 系统
工具链
- 检索库:FAISS(高效向量检索)、Elasticsearch(全文检索)。
- 生成模型:Hugging Face的
transformers库(如facebook/rag-token)。
数据处理与索引构建
- 文档预处理:分块、清洗(去除HTML标签等)。
- 向量化:用预训练模型(如
sentence-transformers/all-MiniLM-L6-v2)编码文档块。 - 构建FAISS索引:将向量存入索引,支持快速近邻搜索。
端到端流程
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
# 初始化RAG组件
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq", index_name="exact")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq", retriever=retriever)
# 输入查询
input_ids = tokenizer("What is RAG?", return_tensors="pt").input_ids
outputs = model.generate(input_ids)
# 解码生成结果
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
调优建议
- 检索模块:调整Top-K值,平衡召回率与计算开销。
- 生成模块:通过Prompt工程控制输出风格。
- 评估指标:使用ROUGE、BLEU或人工评估生成质量。



















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











