






一、MySQL进阶查询
1.1 常用查询介绍
在查询数据库中的数据时,有时需要对查询到的数据尽心处理,例如只显示一部分查询到的结果、对查询结果进行排序或分组等。
1.1.1 按关键字排序
通过order by语句可以完成排序效果,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段。它的语法结构为:
mysql>select 字段1,字段2... from 表名 [where 条件] order by 字段1,字段2... asc|desc;
在上面的语法中,前面的字段和后面的字段含义不同,前者代表要查询的字段名,后者为显示给用户的结果中包含哪些字段。后面的asc为将结果从上到下升序排序,desc为将结果从上到下降序排序。例如要查询一个表中A中的所有字段的数据,条件是其中一个字段level要大于12,显示结果只显示name字段和ID字段,结果以升序排序:
mysql>select * from A where level>12 order by name,ID asc;
注意,结果排序最好是对数据类型是数字类型的字段排序,上面的例子中,若去掉ID,且name字段的数据类型是字符串的话,就会根据ASCII码中,字母的顺序进行排序,先对比字符串的首字母,若相同则对比后面的字母,以此类推。
- order by A,B desc 指 A 用升序,B 用降序;
- order by A asc,B desc 指 A 用升序,B 用降序;
- order by A desc,B desc 指 A 用降序,B 用降序;
1.1.2 对结果进行分组
对于查询的结果可以根据某些条件进行分组。使用group by语句可对结果进行分组,通常是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN)。其语法结构如下:
mysql>select 字段,函数(字段) from 表名 [where 条件表达式] group by 字段;
前面的字段指定要查询哪些字段的数据,函数中的字段作为函数的参数,例如count(字段A)就会显示字段A中有多少个数据,最后面的字段则是将显示的结果根据该字段中多行数据进行分组,相同数据的记录会分为一组。例如,要对表A进行查询,level大于12的有多少人,且根据level进行分组,相同level的分为一组:
mysql>select count(name),level from A where level>12 group by level;
语句中的count(name)用于统计人数,name作为可以用其他字段代替,因为本意只是为了计数name字段中有多少行记录,结果的表现形式如下图: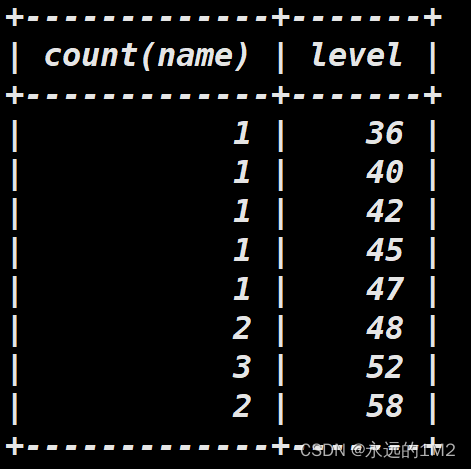
如果去掉前面的level,就不会显示level这一列。
1.1.3 限制结果条目
有时候查询只需要查询结果的某几行,就像查询日志文件,一般不会查看所有的日志内容,这时就需要用limit子句限制显示的结果。它的使用减少了数据结果的返回时间,提高了执行效率,也解决了由于数据量过大从而导致的性能问题。具体语法为:
mysql>select 字段1,字段2...... from 表名 limit [起始行数,] number;
可以指定从哪一行开始显示(起始行数),一共显示几行,或只指定显示的行数number。 例如查询表A中name和id字段中第10行开始,总共20行的数据:
mysql>select name,id from A limit 10,20;
该子句也可以结合排序order by子句使用,先将结果排序,再限制显示的行数,反过来则不行,例如查询A表中所有数据,根据id进行升序排序,只显示前10行:
mysql>select * from A order by id limit 10L; #order by不设置排序方法时,默认升序排序。
1.1.4 设置别名
在查询时,有些字段或表的名字较长,为了方便书写,会给其修改一个便于书写的别名,可以使用as语句设置,具体格式如下:
mysql>select 字段 as 字段别名 from 表名; #字段别名设置
mysql>select 字段 from 表名 as 表别名; #表的别名设置
注意,别名只在当前这句SQL语句中生效,之后不会再生效。
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。
列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
例子:要查询表A中的authtication_string字段的值,且对该字段进行条件判断,排序,再将结果分组:
mysql>select authtication_string as auth from A where auth=‘111111’ order by auth group by auth; #因为where的原因,此次查询的分组结果只有一个auth组。
1.1.5 通配符
-
% :百分号表示零个、一个或多个字符,可在一条语句中多次使用。
-
_:下划线表示单个字符,可在一条语句中多次使用。
例如,查询表A中name字段以s开头,以d结尾的记录:
mysql>select name from A where name like ‘s%d’;
或者查询表A中name字段以s开头,以d结尾,中间有两个字符的记录:
mysql>select name from A where name like ‘s__d’;
后者查询表A中name字段以一个字符开头,后面是d,以d结尾的记录:
mysql>select name from A where name like ‘_s%d’;
1.1.6 子查询
通常子查询会和in配合使用,in的语法结构如下:
主语句 [not] in (子查询)
当表达式与子查询返回的结果集中的某个值相等时,返回TRUE,否则返回FALSE。
1. 子查询在select语句中的使用
例如在A表查询level大于12的人,并判断A表内的name是不是在这个结果集内:
mysql>select name from A where name in (select name from A where level>12);
2. 子查询在insert语句中的使用
子查询的结果集可以通过INSERT语句插入到其他的表中,例如筛选表B中的内容,将其插入到A表中:
mysql>insert into A select * from B where level<12;
#将B表中level字段值小于12的记录插入到A表中
3. 子查询在update语句中的使用
UPDATE内的子查询,在set更新内容时,可以是单独的一列,也可以是多列。例如将B表中level大于45的记录更新到A表中同一id的记录中。
mysql>update A set level= a.level where id in (select level,id from B where level>45) a;
4. 子查询在delete语句中的使用
例如使用delete删除level为12的用户删除:
mysql>delete from A where id in (select id from A where level=12);
后者删除level不为12的用户删除:
mysql>delete from A where id not in (select id from A where level=12);
也可以使用exists判断子查询是否有结果,若子查询没有结果则主查询不会有结果。
1.2 NULL值
在SQL语句中,通常用NULL值表示字段中某一行里缺失的值,也就是在该表中该字段是没有值的。如果要限制一些字段不能为NULL,则可以使用NOT NULL关键字,不适用默认为空。需要注意的是NULL值和0或者空白是不同的,值为NULL的字段虽然也占有空间但是没有值,而0是一个值,单纯空白是没有值,不占用空间。在SQL语句中可以使用is null判断某个字段是不是NULL值,相反的用is not null可以判断不是NULL值。例如创建一个A表,address字段可以为NULL:
mysql>create table A (id int(10) not null,name char(20) not null,level int(2) not null,address char(50) );
注意,在通过 count()计算有多少记录数时,如果遇到NULL值会自动忽略掉,遇到空值会加入到记录中进行计算。
1.3 正则表达式
在mysql语句中也可以用正则表达式匹配符合要求的特殊字符串,在语句中添加regexp即可使用正则表达式,支持的匹配模式如下:
|
^
|
匹配文本的开始字符
|
‘^bd’
匹配以
bd
开头的字符串
|
|
$
|
匹配文本的结束字符
|
‘qn$’
匹配以
qn
结尾的字符串
|
| . |
匹配任何单个字符
|
‘s.t’
匹配任何
s
和
t
之间有一个字符的字符串
|
| * |
匹配零个或多个在它前面的字符
|
‘fo*t’
匹配
t
前面有任意个
o
|
| + |
匹配前面的字符
1
次或多次
|
‘hom+’
匹配以
ho
开头,后面至少一个 m 的字符串
|
| 字符串 |
匹配包含指定的字符串
|
‘clo’
匹配含有
clo
的字符串
|
| 字符串1|字符串2 |
匹配字符串
1或字符串
2
|
‘bg|fg’
匹配
bg
或者
fg
|
| [……] |
匹配字符集合中的任意一个字符
|
‘[abc]’
匹配
a
或者
b
或者
c
|
| [^……] |
匹配不在括号中的任何字符
|
‘[^ab]’
匹配不包含
a
或者
b
的字符串
|
| {n} |
匹配前面的字符串
n
次
|
‘g{2}’
匹配含有
2
个
g
的字符串
|
| {n,m} |
匹配前面的字符串至少
n
次,至多m次
|
‘f{1,3}’
匹配
f
最少
1
次,最多
3
次
|
例如要查找A表中,name字段里以a开头,中间包含任意数量的a到z字符且最后以b结尾的记录:
mysql>select * from A where name regexp '^a[a-z]d$';
1.4 运算符
MySQL 的运算符用于对记录中的字段值进行运算。MySQL 的运算符共有四种,分别是:算术运算符、比较运算符、逻辑运算符和位运算符。
1.4.1 算数运算符
就是加+、减-、乘*、除/以及取余%。使用方法:
mysql>select 值1 运算符 值2;
注意,某些字符串类型的字段存储的数字型字符串,这些字段在进行算术运算时将会被自动转换为数字的值。如果字符串的开始部分是数字,在转换时将被转换为这个数字。如果是既包含字符又包含数字得的混合字符串,无法转换为数字时,将被转换为 0。
1.4.2 比较运算符
| 运算符 | 描述 | 运算符 | 描述 |
| = | 等于 | is not null | 判断一个值是否部位null |
| > | 大于,不能判断null | between and | 两者之间 |
| < | 小于,不能判断null | in | 在集合中 |
| >= | 大于等于,不能判断null | like | 通配符匹配 |
| <= | 小于等于,不能判断null | greatest | 两个或多个参数时返回最大值 |
| !=或<> | 不等于,不能判断null | least | 两个或多个参数时返回最小值 |
| is null | 判断一个值是否为null | regexp | 正则表达式 |
对于"=",相等则返回 1,如果不相等则返回 0。如果比较的两者有一个值是 NULL,则比较的结果就是 NULL。字符的比较是根据 ASCII 码来判断的,如果 ASCII 码相等,则表示两个字符相同。还需要注意的是:
-
如果两者都是整数,则按照整数值进行比较。
-
如果一个整数一个字符串,则会自动将字符串转换为数字,再进行比较。
-
如果两者都是字符串,则按照字符串进行比较。
-
如果两者中至少有一个值是 NULL ,则比较的结果是 NULL 。
mysql>select 数字或字符 between 数字或字符 and 数字或字符;
least和grantest的语法为:
mysql>select least/grantest(数值1,数值2,……);
1.4.3 逻辑运算符
| not 或! |
逻辑非
|
| and或&& |
逻辑与
|
| or 或 || |
逻辑或
|
| xor |
逻辑异或
|
1.4.4 位运算符
位运算符实际上是对二进制数进行计算的运算符。运算时会将十进制转为二进制,结束后再转换回来。mysql支持6中位运算符:
| & |
按位与
|
| | |
按位或
|
| ~ |
按位取反
|
| ^ |
按位异或
|
| << |
按位左移
|
| >> |
按位右移
|
运算符之间也有自己的优先级:
| 优先级 | 运算符 | 优先级 | 运算符 |
| 1 | ! | 8 | | |
| 2 | ~ | 9 |
=,>=,>,<=,<,<>,!=,is,like,regexp,in
|
| 3 | ^ | 10 |
between,case,when,then,else
|
| 4 | *,/,% | 11 | not |
| 5 | +,- | 12 | &&,and |
| 6 | >>,<< | 13 | ||,or,xor |
| 7 | & | 14 | := |
1.5 连接查询
mysql>select 字段1,字段2,…… from 表1 inner join 表2 on 表1.字段=表2.字段;
#显示所有表1字段中的值与表2字段中的值相同的表1的字段1,字段2…….
内连接是系统默认的表连接,所以在from子句后可以省略inner关键字,只使用关键字join。 用一张图来表示的话就是: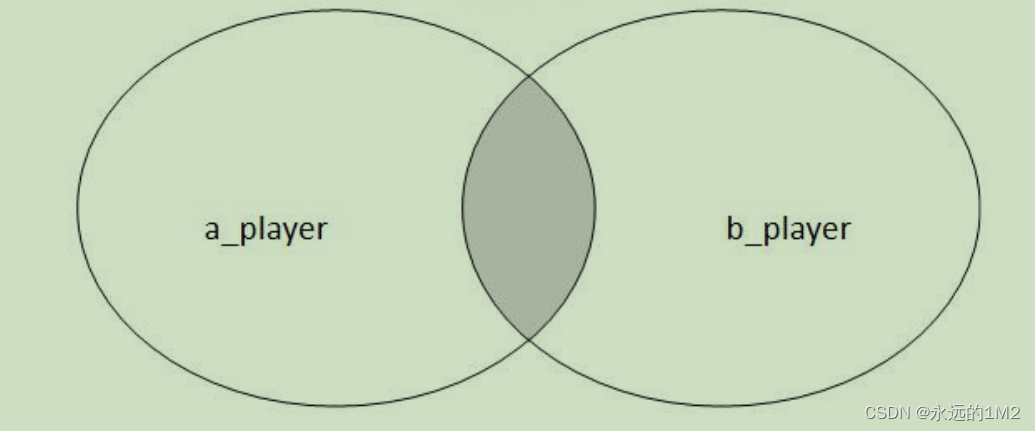
左连接也被称为左外连接,在from子句中使用left join或者left outer join关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。例如查询A表和B表中,查询出A表中所有的内容和B表中与A表id相同的部分:
mysql>select * from A left join B on A.id=B.id;
用一张图来表示的话就是: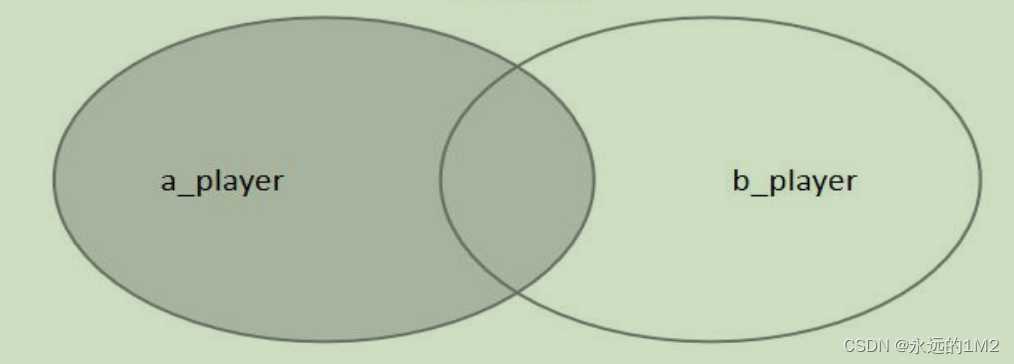
右连接也被称为右外连接,与左连接大致相同,查询的就是右边的部分,语法是:
select * from A right join B on A.id=B.id;
用一张图来表示的话就是: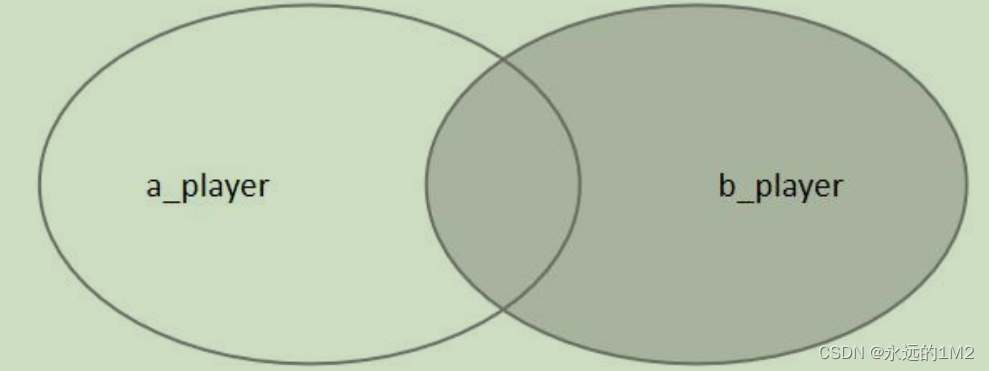
二、数据库函数
2.1 数学函数
mysql支持的函数有:
| abs(x) |
返回
x
的绝对值
|
| rand() |
返回
0
到
1
的随机数
|
| mod(x,y) |
返回
x
除以
y
以后的余数
|
| power(x,y) |
返回
x
的
y
次方
|
|
round(x)
|
返回离
x
最近的整数
|
|
round(x,y)
|
保留
x
的
y
位小数四舍五入后的值
|
|
sqrt(x)
|
返回
x
的平方根
|
|
truncate(x,y)
|
返回数字
x
截断为
y
位小数的值
|
|
ceil(x)
|
返回大于或等于
x
的最小整数
|
|
floor(x)
|
返回小于或等于
x
的最大整数
|
|
greatest(x1,x2...)
|
返回集合中最大的值
|
|
least(x1,x2...)
|
返回集合中最小的值
|
使用函数的语法为:
mysql>select 函数名(参数);
2.2 聚合函数
| avg() |
返回指定列的平均值
|
| count() |
返回指定列中非
NULL
值的个数
|
| min() |
返回指定列的最小值
|
| max() |
返回指定列的最大值
|
| sum(x) |
返回指定列的所有值之和
|
例如查询A表中level大于12的人的个数:
mysql>select count(*) from A where level=12;
2.3 字符串函数
常用的字符串函数如下:
|
length(x)
|
返回字符串
x
的长度
|
|
trim()
|
返回去除指定格式的值
|
|
concat(x,y)
|
将提供的参数
x
和
y
拼接成一个字符串
|
|
upper(x)
|
将字符串
x
的所有字母变成大写字母
|
|
lower(x)
|
将字符串
x
的所有字母变成小写字母
|
|
left(x,y)
|
返回字符串
x
的前
y
个字符
|
|
right(x,y)
|
返回字符串
x
的后
y
个字符
|
|
repeat(x,y)
|
将字符串
x
重复
y
次
|
|
space(x)
|
返回
x
个空格
|
|
replace(x,y,z)
|
将字符串
z
替代字符串
x
中的字符串
y
|
|
strcmp(x,y)
|
比较
x
和
y
,返回的值可以为
-1,0,1
|
|
substring(x,y,z)
|
获取从字符串
x
中的第
y
个位置开始长度为 z
的字符串
|
|
reverse(x)
|
将字符串
x
反转
|
调用函数的方法与数学函数的调用方法相同。
2.4 日期时间函数
|
curdate()
|
返回当前时间的年月日
|
|
curtime()
|
返回当前时间的时分秒
|
|
now()
|
返回当前时间的日期和时间
|
|
month(x)
|
返回日期
x
中的月份值
|
|
week(x)
|
返回日期
x
是年度第几个星期
|
|
hour(x)
|
返回
x
中的小时值
|
|
minute(x)
|
返回
x
中的分钟值
|
|
second(x)
|
返回
x
中的秒钟值
|
|
dayofweek(x)
|
返回
x
是星期几,
1
星期日,
2
星期一
|
|
dayofmonth(x)
|
计算日期
x
是本月的第几天
|
|
dayofyear(x)
|
计算日期
x
是本年的第几天
|
三、存储过程
MySQL数据库存储过程是一组为了完成特定功能的SQL语句的集合,类似于脚本。存储过程在数据库中创建并保存,它不仅仅是 SQL 语句的集合,还可以加入一些特殊的控制结构,也可以控制数据的访问方式。以下存储过程的优点:
-
存储过程执行一次后,生成的二进制代码就驻留在缓冲区,之后如果再次调用的话,将直接调用二进制代码,使得存储过程的执行效率和性能得到大幅提升。
-
存储过程是 SQL 语句加上控制语句的集合,有很强的灵活性,可以完成复杂的运算。
-
存储过程存储在服务器端,客户端调用时,直接在服务器端执行,客户端只是传输的调用语句,从而可以降低网络负载。
-
存储过程被创建后,可以多次重复调用,它将多条 SQL 封装到了一起,可随时针对 SQL语句进行修改,不影响调用它的客户端。
-
存储过程可以完成所有的数据库操作,也可以通过编程的方式控制数据库的信息访问权限。

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









