






 本文介绍了主成分分析(PCA)的基本概念、原理和实现过程,包括数据预处理、协方差矩阵计算、特征值与特征向量选择、降维操作以及在图像处理中的应用示例。PCA通过线性变换降低数据维度,揭示数据的主要特征,常用于数据压缩和特征提取。
本文介绍了主成分分析(PCA)的基本概念、原理和实现过程,包括数据预处理、协方差矩阵计算、特征值与特征向量选择、降维操作以及在图像处理中的应用示例。PCA通过线性变换降低数据维度,揭示数据的主要特征,常用于数据压缩和特征提取。
一、算法简介与定义
主成分分析(Principal Component Analysis,简称PCA)是一种常用的多变量数据分析方法,用于降低数据的维度并发现数据中最重要的特征。其基本思想是通过线性变换将原始数据映射到新的坐标系,使得数据在新坐标系下的方差最大化。
在实际的数学建模中,降维操作是很常用的。
比如在图像处理中,如果要识别人脸,需要将每张图像表示为一个向量,每个元素代表图像中某个像素点的灰度值。由于每张图像的像素数量很大,可能成百上千万甚至更多,这会导致计算和存储成本非常高。
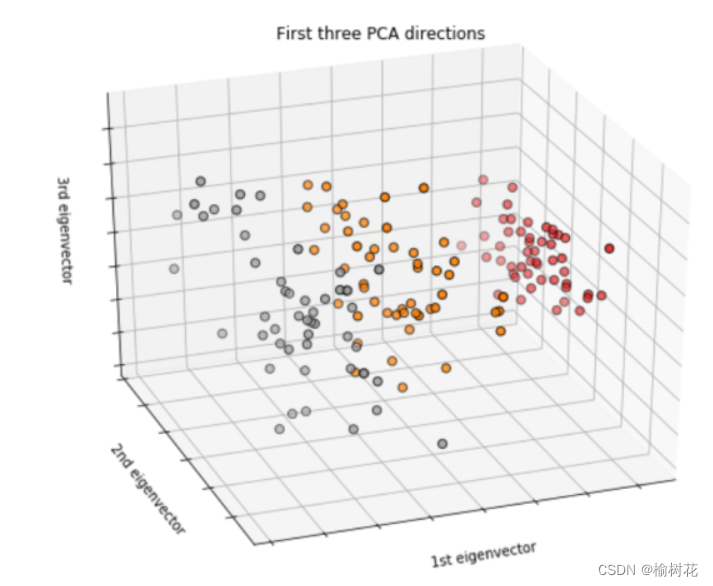
二、基本原理
PCA的基本原理是通过线性变换将原始数据映射到一个新的坐标系,使得数据在新坐标系下的方差最大化。具体而言,PCA的步骤如下:
1.数据预处理:
对原始数据进行预处理,包括去除均值、标准化或归一化等操作,以确保数据的可比性。
2.计算协方差矩阵:
根据预处理后的数据计算协方差矩阵(或相关矩阵),其中每个元素表示两个变量之间的协方差(或相关度)。
3.特征值与特征向量:
对协方差矩阵进行特征值分解(或奇异值分解),得到特征值和对应的特征向量。
4.主成分选择与排序:
根据特征值的大小选择保留哪些主成分。特征值表示了数据在对应特征向量方向上的方差,因此较大的特征值对应的特征向量表示了数据中更重要的信息。
5.数据映射:
将原始数据投影到所选的主成分上,得到降维后的数据集。这相当于在新的坐标系中重新表示原始数据。
三、PCA具体实现
1. 协方差矩阵
对于我们得到的一组数据,可以求出其样本均值
样本方差:
两个样本之间的协方差:
当协方差为0时,说明X和Y变量之间是线性无关的。
由所有的样本的列向量组成的矩阵X,根据可以得到两两数据之间的协方差矩阵:
由矩阵知识可知,协方差矩阵为对称矩阵,对角线上为样本的方差,其他为两两变量之间的协方差。我们便可以利用对称矩阵的对角化将协方差化为0,实现变量间的线性无关,并且此时对角线上选取最大的K个方差即可。
2.特征值与特征向量
根据协方差矩阵计算其特征值与特征向量,由线性代数我们知道,如果一个向量v是矩阵A的特征向量,将一定可以表示成下面的形式:
从而利用 |λE - A| = 0可解出矩阵的特征值,一个特征值便对应一组特征向量,特征向量之间是相互正交的。将所得到的特征向量对应其特征值从大到小排列,选出最大的k个向量单位化,便可作为PCA变换所需要的k个基向量,且方差最大。
通过数学方法可以证明,特征值λ即为降维后数据的方差,可以参照拉格朗日乘数法的最优化。
3.基向量变换
X是一个mxn 的矩阵,它的每一个列向量都表示一个采样点上的数据 。Y 表示转换以后的新的数据集表示。 P是他们之间的线性转换,即计算向量内积。可表示为:Y=PX
P便是由基向量组成的变换矩阵,经过线性转换,X的坐标便转换到新的基向量所决定的空间中的坐标Y,从几何上看,Y是X在新的空间中的投影。
经过基向量变换,即完成了数据的降维。
四、PCA的简单实现
1.首先我们先导入必要的库
import numpy as np
import matplotlib.pyplot as plt
2.接下来,我们可以生成一个包含100个样本的二维数据集:
np.random.seed(0)
mean = [2, 3] # 均值
cov = [[1, 0.5], [0.5, 1]] # 协方差矩阵
data = np.random.multivariate_normal(mean, cov, 100)
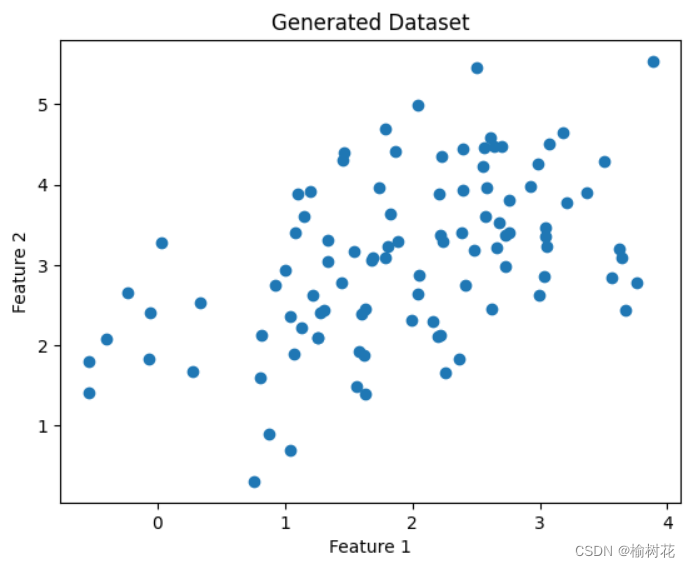
3.现在我们已经生成了一个包含100个样本的数据集,每个样本有两个特征。下面我们可以绘制散点图来可视化数据集:
plt.scatter(data[:, 0], data[:, 1])
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Generated Dataset')
plt.show()
结果图:
4.接下来,我们可以使用PCA来降低数据的维度。
首先,我们需要对数据进行标准化,以确保每个特征具有相同的尺度:
data_std = (data - np.mean(data, axis=0)) / np.std(data, axis=0)
5.然后,我们可以计算数据的协方差矩阵:
covariance_matrix = np.cov(data_std.T)
6.接下来,我们将计算协方差矩阵的特征值和特征向量:
eigenvalues, eigenvectors = np.linalg.eig(covariance_matrix)
7.然后,我们可以根据特征值的大小对特征向量进行排序,以确定最重要的主成分:
sorted_indices = np.argsort(eigenvalues)[::-1]
sorted_eigenvalues = eigenvalues[sorted_indices]
sorted_eigenvectors = eigenvectors[:, sorted_indices]
8.最后,我们可以选择前几个主成分,并使用它们来降低数据的维度。这里,我们选择保留前两个主成分:
projection_matrix = sorted_eigenvectors[:, :2]
reduced_data = np.dot(data_std, projection_matrix)
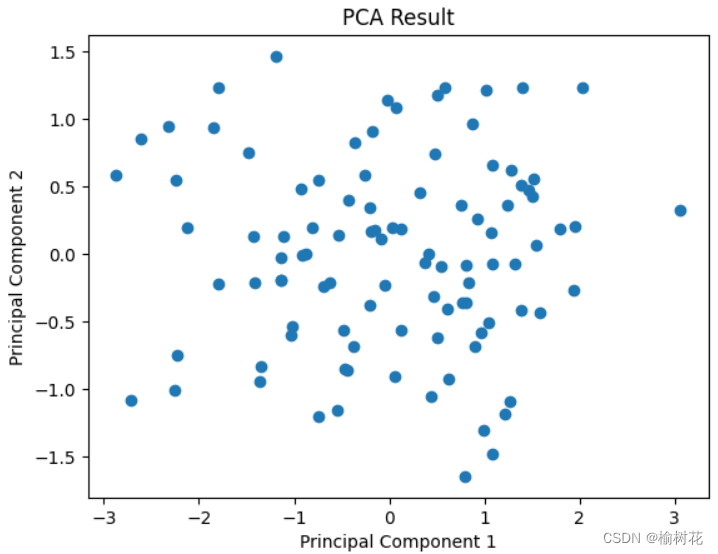
9.我们可以绘制降低维度后的数据集:
plt.scatter(reduced_data[:, 0], reduced_data[:, 1])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA Result')
plt.show()
实验结果图:
五、实验小结
PCA是一种强大的降维工具,可以在许多领域中应用。在实验中,我们可以通过计算协方差矩阵、进行特征值分解和数据转换等步骤来实现PCA降维,并通过结果分析来评估降维效果。PCA可以帮助我们理解数据中的主要方向和关系,并将高维数据降低到较低维度的表示形式。同时通过选择适当数量的主成分,我们可以在保留数据集主要信息的同时减少特征的数量。最后,PCA的成功与否取决于数据集本身的性质以及所选择的主成分数量。

















 3432
3432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









