







 本文介绍了决策树的基本概念,包括根节点、中间节点、叶节点的定义,并详细阐述了特征选择、信息熵、信息增益等核心概念。通过代码展示了如何计算信息熵、信息增益以及如何按照信息增益选择最佳切分列来构建决策树。同时,还提供了数据集划分、决策树构建及准确度评估的方法,帮助读者理解并实现决策树算法。
本文介绍了决策树的基本概念,包括根节点、中间节点、叶节点的定义,并详细阐述了特征选择、信息熵、信息增益等核心概念。通过代码展示了如何计算信息熵、信息增益以及如何按照信息增益选择最佳切分列来构建决策树。同时,还提供了数据集划分、决策树构建及准确度评估的方法,帮助读者理解并实现决策树算法。
http://t.csdn.cn/NdlCs next()and iter()函数
http://t.csdn.cn/tRN4I sort_values and value_counts()函数
http://t.csdn.cn/Uqmtt pandas库
决策树
根节点: 没有进只有出
中间节点:有进有出,进边只有一条,出边可以很多条
叶节点:只有进,每个叶节点都是一个类别标签
父节点和子节点:相对而言
每一个实例都被有且只有一条路径或者规则所覆盖。
特征选择选取:选择纯度高的节点(分支节点所包含的样本尽可能属于同一类别)
常常衡量不纯度的指标有:熵(香农熵),增益率,基尼指数


创造数据:
关于鱼类的分类表 {水生 有无脚蹼}
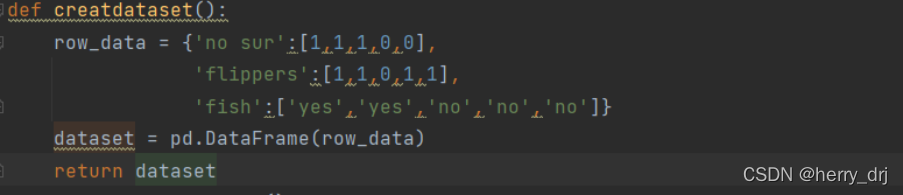
计算信息熵
代码实现:
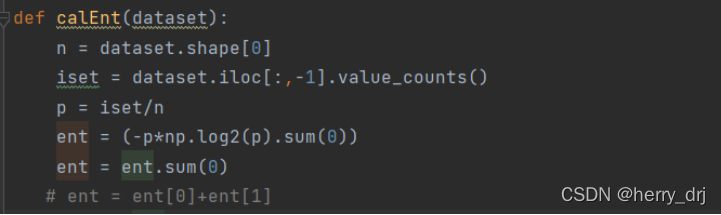
信息增益:


代码实现:
计算信息增益即寻找最佳切分列代码实现如下
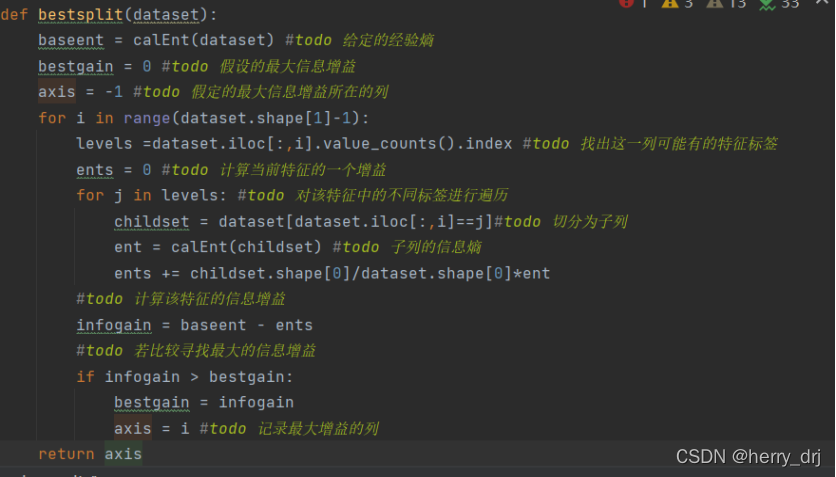
按照给定序列切分数据集
代码实现:

主体代码:递归构建决策树
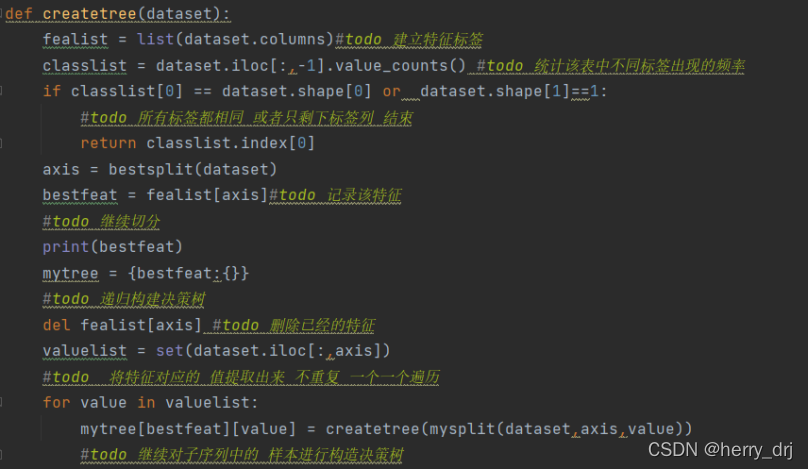
对已给数据集进行分类:

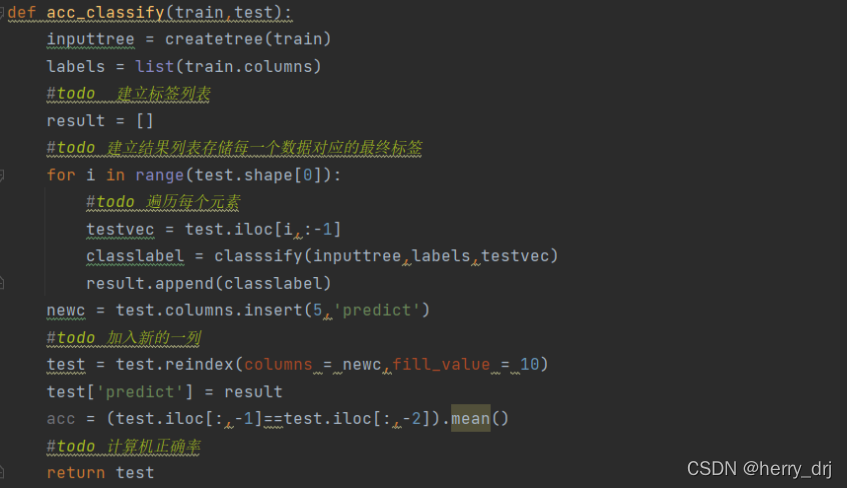
切分已经给定数据集为训练集和测试集:

计算生成的决策树的准确度



















 2587
2587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











