







操作前准备
create table star(
id int auto_increment,
name varchar(50) not null,
money float not null,
province varchar(30) default null,
age int unsigned not null,
sex int not null,
primary key(id)
)engine = innodb default charset = utf8;代码解释:
auto_increment是一个自增长属性,意味着每当向表中插入一条新记录时,如果不手动指定id的值,数据库系统会自动为该列分配一个依次递增的整数值,常用于作为表的主键来唯一标识每一条记录。
engine = innodb:
- 指定该表使用
InnoDB存储引擎。InnoDB是 MySQL 中常用的一种存储引擎,
default charset = utf-8:
- 规定了该表默认的字符集为
UTF-8
not null表示该值不可为空,必须填写,default null表示该值可为空,不填写默认为空
查询数据的基础语句
select * from 数据表名字;
示例:select * from star;
mysql插入数据(3中方法)
1.按顺序插入数据
insert into 表名 values(值1,值2....)
示例:insert into star values(1,'王宝强',9876,'河北省',41,0);
2.插入对应数据(常用)
insert into 表名(字段1,字段2,字段3.....) values(值1,值2....)
示例:insert into star(name,money,province,age,sex) values('郭德纲',6789,'天津',52,0);
3.插入多条数据
insert into 表名(字段1,字段2...) values(值1,值2....),(值1,值2....)
示例:
insert into star(name,money,province,age,sex) values('迪丽热巴',6789,'新疆',32,1),('于谦',6756,'北京',57,0),('王红',22323,'广西',21,1),('佟丽娅',23259,'新疆',42,1);
mysql删除数据
delete from 数据表名字 where 条件;
delete from star where id = 6;
将star表中id为6的删除
注意:where条件不能省略,条件一般选择id字段较多
mysql修改数据
update 表名 set 字段1=值1,字段2=值2,..... where 条件;
update star set name='谦爷',money=87878,province='河南' where id = 4;
mysql查询数据
基础查询
select * from 数据表名 (其中*表示所有数据)
指定字段查询
select 字段1,字段2,字段3.... from 数据表名字;
示例:
select name,province from star;
指定字段组合不重复记录
select distinct 字段名 from 数据表名字; (distinct表示去重)
示例:
select distinct name from star;
条件查询
select 字段1,字段2,字段3.... from 数据表名字 where 查询条件;
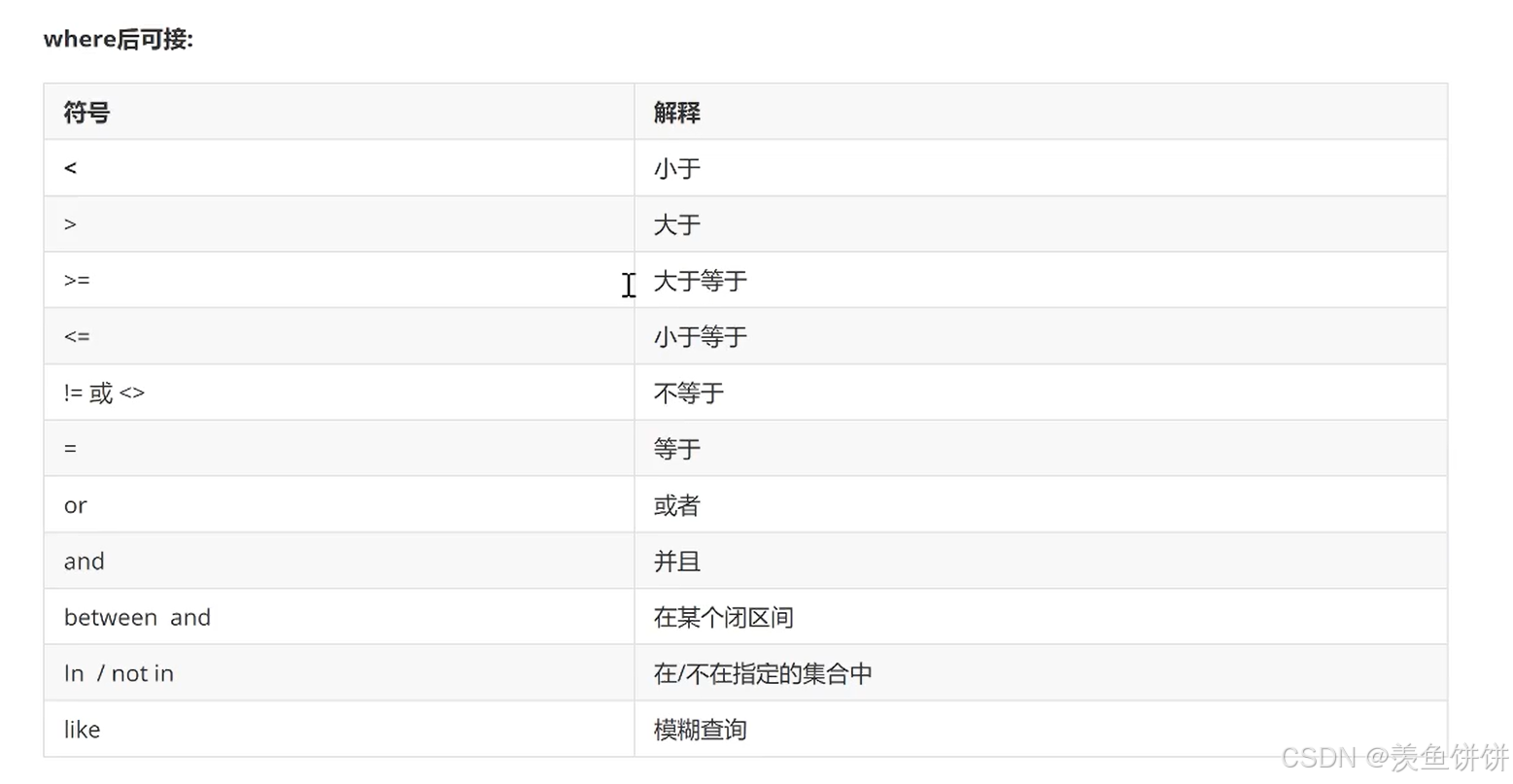
示例
= select * from star where age = 41;
< select * from star where age < 41;
> select * from star where age > 41;
>= select * from star where age >= 41;
!= select * from star where age >= 41;
or select * from star where age = 41 or province = '新疆';
and select * from star where age = 41 and province = '新疆';
between and select * from star where id between 2 and 4;
in select * from star where id in(2,3,1);
not in select * from star where id not in(2,3,1);
like(模糊查询 %表示通配符) select * from star where name like '王%';
select * from star where name like '%丽%';
结果集排序
select 字段名 from 数据表名字 order by 字段 排序关键字;
排序关键字: asc 升序(默认值),desc 降序
示例:select * from star order by money asc;
多字段排序
select 字段名 from 表名 order by 字段1 desc | asc,字段2 desc | asc;
排序关键字: asc 升序(默认值),desc 降序
示例:select * from star order by money desc,age asc;
按money降序,若money字段值一样,按age升序
限制查询的结果集
select 字段 from 表名 limit 数量;
示例:select * from star limit 3; (查询star集中的前三条信息)
限制排序后的结果集
select 字段名 from 数据表名 order by 字段 排序规则 limit 数量;
select * from star order by money desc limit 3;
找出最有钱的三个人
结果集区间选择
select 字段名 from 数据表名 order by 字段名 排序规则 limit 偏移量,数量;
select * from star order by money desc limit 2,3;
按money降序排序,从第2条开始取3条数据;
常见统计函数
sum select sum(money) as 总财富 from star;
count select count(id) as 总数 from star;
max select max(money) as 最大值 from star;
min select min(money) as 最小值 from star;
avg select avg(money) as 平均值 from star;
分组查询
select * from 数据表名 group by 字段名;
select province from star group by province;
查询总共有多少个省份
分组统计
select count(字段名),字段名 from 数据表名字 group by 字段名;
select count(*) as 数量,province from star group by province;
统计各个省份明星数量(有几个相同的省份)
结果集过滤
select count(*) as result,字段 from 数据表名字 group by 字段 having 条件;
select count(*) as result,province from star group by province having result >=2;
统计相同省份大于2的省份


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









