







beautifulsoup基础
from bs4 import BeautifulSoup
fp=open('./baidu.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
# 定位标签
# print(soup)
# print(soup.a)
# print(soup.div)
# print(soup.find("div"))
# print(soup.find_all('div')) 返回一个列表,含有所以div
# print(soup.find('div',class_='tang')) 找到div,class=‘lan’的div块
# print(soup.select(".tang")) 可以放某种选择器,id选择器,class类选择器,标签选择器,返回的是一个列表
# 层级选择器
# print(soup.select('.tang>ul>li>a')[0]) #返回列表,在这个层级下的所有a
# print(soup.select('.tang>ul a')[1]) #空格表示多个层级
# 获取文本属性值 soup.div.text/get_text()/string
# print(soup.div.text) 返回第一个div下的所有文本数据
# print(soup.find('div',class_='tang').text) #找到div,class=‘lan’的div块中所有的文本数据
# soup.div.text/get_text()/string的区别
# text和get_text()能返回所有文本数据,string只能返回该标签下的一个文本数据
# 获取标签属性值 soup.div['song']
# print(soup.select('.tang>ul a')[1]['href'])实战:爬取诗词名句网的三国演义
import requests
from bs4 import BeautifulSoup
url = "https://www.shicimingju.com/book/sanguoyanyi.html"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
# 获取网页内容,先以二进制形式获取
response = requests.get(url=url, headers=header)
# 因为我爬取的不知道为啥是乱码,用这个就不会
response.encoding = 'UTF-8'
page_text = response.text
soup = BeautifulSoup(page_text, 'lxml')
# 定位标题的标签位置,返回一个列表
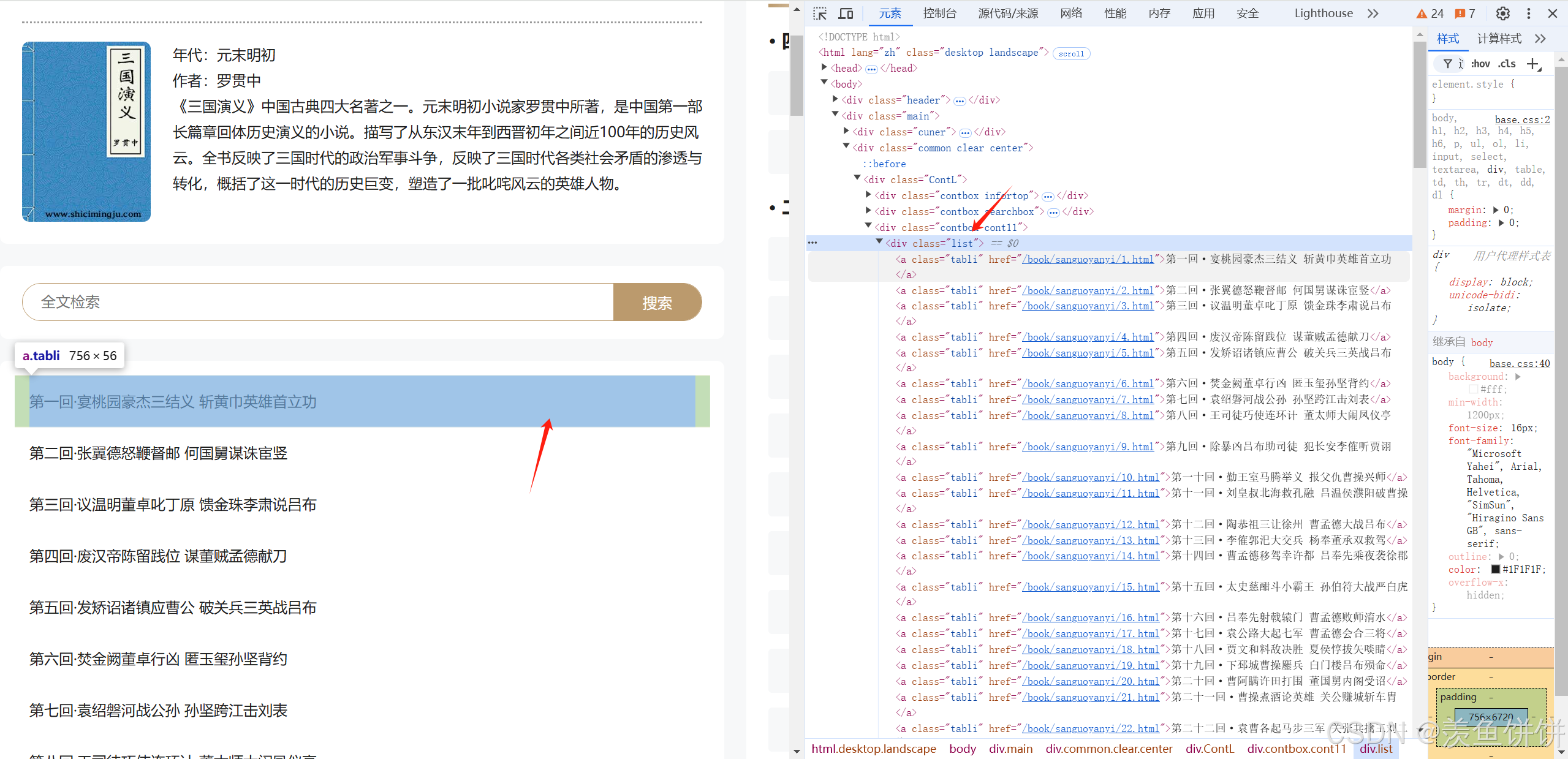
li_list = soup.select('.list>a')
with open('./sanguo.txt','w',encoding='utf-8') as fp:
for li in li_list[0:9]:
title = li.string #当前标签的文本内容
detail =li['href'] #当前标签中的属性
detail_url = 'https://www.shicimingju.com/'+detail #详情页网址
detail_response = requests.get(url=detail_url, headers=header)
detail_response.encoding = 'UTF-8'
detail_text = detail_response.text
detail_soup = BeautifulSoup(detail_text, 'lxml')
# 先定位标签
detail_tag=detail_soup.find('div',class_='text p_pad')
# 再爬取文本 两个一起执行会出错,不知道为啥
detail_data = detail_tag.text
fp.write(title+':'+detail_data+'\n')
print(title,'爬取成功')
#爬取到的文件会有 ,看了下网页源码是有这个的,没办法,自己删一下吧
def remove_from_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 删除所有的 "sbsp" 字符串
modified_content = content.replace(" ", "")
with open(file_path, 'w', encoding='utf-8') as file:
file.write(modified_content)
print(f"已成功从文件 {file_path} 中删除所有 ' ' 字符串。")
except FileNotFoundError:
print(f"文件 {file_path} 未找到,请检查文件路径是否正确。")
except Exception as e:
print(f"发生了其他错误: {e}")
remove_from_file("./sanguo.txt")代码解释,这里为了方便我只爬取了第一回到第九回,速度更快一点,然后最后加了一个乱码处理的代码,那个乱码是网页自带的缩进好像
li_list = soup.select('.list>a')这个只能自己一个个找,没啥好办法好像
其他的注释代码里面都有


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









