







xpath基础
from lxml import etree
tree=etree.parse("./baidu.html")
r = tree.xpath("/html/head/title")
/从根目录开始寻找 /html/head/title /html//title
//在所有源码中进行寻找 //div
//div[@class="song"]
//div[@class="song"]//li[5]/a/text() 从1开始算
//li[5]/text() 取出文本内容
//li[5]/@src 取出属性值
需要注意的点: xpath返回的是一个列表,要字符串的话要在()[0]
实战1,爬取58同城二手房名称
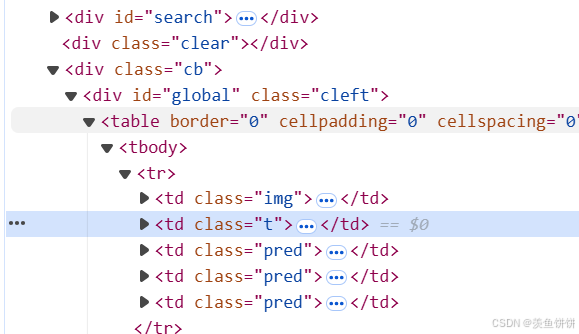
tr_list = tree.xpath('//div[@class="cb"]/div[@id="global"]/table') print(tr_list)有值,
但是tr_list = tree.xpath('//div[@class="cb"]/div[@id="global"]/table/tbody') print(tr_list)没有是怎么回事,这个是因为
- 在 HTML 中,
tbody元素是table元素的一个子元素,但在很多情况下,浏览器在解析 HTML 表格(table)时会自动添加tbody元素。
所以可以直接
tr_list = tree.xpath('//div[@class="cb"]/div[@id="global"]/table/tr')
import requests
from lxml import etree
url="https://www.58.com/ershoufang/"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
page_text = requests.get(url,header).text
tree = etree.HTML(page_text)
tr_list = tree.xpath('//div[@class="cb"]/div[@id="global"]/table/tr')
fp = open('58.txt','w',encoding='utf-8')
for tr in tr_list:
title = tr.xpath('./td[@class="t"]/a/text()')[0]
print(title)
fp.write(title+'\n')实战2,爬取4k美女图片(我没爬出来)
乱码处理方法
如果爬取的网页是乱码用这两种方法试试
respond = requests.get(url=url,headers=headers) respond.encoding='utf-8' page_text=respond.text
img_title = img_title.encode('iso-8859-1').decode('gbk')
# 我爬不到,爬取到的内容不是开发者工具显示的网页代码
# 可以自己尝试一下,li_list = tree.xpath('//div'),只有三个没有slist的属性值,但是网页源码里面有,不知道为啥
import requests
from lxml import etree
import os
if not os.path.exists('./piclibs'):
os.mkdir('./piclibs')
url="https://pic.netbian.com/4kmeinv/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
respond = requests.get(url=url,headers=headers)
page_text=respond.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="list"]/ul/li')
for li in li_list:
img_url='https://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_title=li.xpath('./a/img/@alt')[0]+'.jpg'
img_title = img_title.encode('iso-8859-1').decode('gbk')
img_data=requests.get(url=img_url,headers=headers).content
img_path= './piclibs'+img_title
with open(img_path,"wb") as fp
fp.write(img_data)
# https://pic.netbian.com/uploads/allimg/241119/090438-1731978278e0f6.jpg
# print(li_list)实战3,爬取全国城市
第三个也爬不到。。。。。
import requests
from lxml import etree
url="https://pic.netbian.com/4kmeinv/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
respond = requests.get(url=url,headers=headers)
page_text=respond.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//div/@class')
print(li_list)
# //div[@class='bottom']/ul/li/a
# //div[@class='bottom']/ul/div[2]/li/a
# tree.xpath('//div[@class='bottom']/ul/li/a | //div[@class='bottom']/ul/div[2]/li/a')

















 4357
4357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









