



文章目录
链路追踪Zipkin
一个看起来很简单的应用,背后可能需要数十或数百个服务来支撑,一个请求就要多次服务调用。当请求变慢、或者不能使用时,我们是不知道是哪个后台服务引起的。这时,我们使用 Zipkin 就能解决这个问题。由于业务访问量的增大,业务复杂度增加,以及微服务架构和容器技术的兴起,要对系统进行各种拆分。微服务系统拆分后,我们可以使用 Zipkin 链路,来快速定位追踪有故障的服务点。
Zipkin/SkyWalking 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),能够收集服务间调用的时序数据,提供调用链路的追踪。
Zipkin 其主要功能是聚集来自各个异构系统的实时监控数据,在微服务架构下,十分方便地用于服务响应延迟等问题的定位。
Zipkin 每一个调用链路通过一个 trace id 来串联起来,只要你有一个 trace id ,就能够直接定位到这次调用链路,并且可以根据服务名、标签、响应时间等进行查询,过滤那些耗时比较长的链路节点。
Zipkin 分布式跟踪系统就能非常好地解决该问题,主要解决以下3点问题:
-
- 动态展示服务的链路;
-
- 分析服务链路的瓶颈并对其进行调优;
-
- 快速进行服务链路的故障发现;
在优化前通过Zipkin链路追踪进行查看接口耗时
-
在
service-util工具模块pom.xml中新增Zipkin相关依赖<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-tracing-bridge-brave</artifactId> </dependency> <dependency> <groupId>io.zipkin.reporter2</groupId> <artifactId>zipkin-reporter-brave</artifactId> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-observation</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> <version>2.2.8.RELEASE</version> </dependency> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-micrometer</artifactId> <version>12.5</version> </dependency> -
在Nacos配置
common.yaml中新增配置(已完成)management: zipkin: tracing: endpoint: http://192.168.200.6:9411/api/v2/spans tracing: sampling: probability: 1.0 # 记录速率100% -
解决异步任务+多线程导致异步Feign请求无法被链路追踪,故需要未线程池设置装饰器(将当前线程内上下文中trace_id传递到子线程中),故将当日资料中复制到
service-util且设置Spring线程池对象装饰器//设置解决zipkin链路追踪不完整装饰器对象 taskExecutor.setTaskDecorator(new ZipkinTaskDecorator(zipkinHelper)); -
访问接口、或查看页面进行测试
-
通过Zipkin管理页面查看接口耗时
Redisson
EL表达式自定义缓存注解(通用)
RedissonConfig
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.config.SingleServerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author : 戚欣扬
* @Description :
*/
@Configuration
public class RedissonConfig {
@Value("${spring.data.redis.host}")
private String host ;
@Value("${spring.data.redis.password}")
private String pasword;
@Value("${spring.data.redis.port}")
private String port;
private String timeout;
private static String ADDRESS_PREFIX = "redis://";
@Bean
RedissonClient redissonSingle(){
Config config = new Config();
if (host.isEmpty()){
throw new RuntimeException("Redisson Host is empty!");
}
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress(ADDRESS_PREFIX + host + ":" + port);
if (timeout!=null) {
serverConfig.setTimeout(Integer.parseInt(timeout));
}
if (!pasword.isEmpty()){
serverConfig.setPassword(pasword);
}
return Redisson.create(config);
}
}
Json| RedisConfig
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.*;
/**
* Redis配置类
*/
@Configuration
@EnableCaching
public class RedisConfig {
@Bean
@Primary
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
//String的序列化方式
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// 使用GenericJackson2JsonRedisSerializer 替换默认序列化(默认采用的是JDK序列化)
GenericJackson2JsonRedisSerializer genericJackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//序列号key value
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setValueSerializer(genericJackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(genericJackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
Annotation
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.util.concurrent.TimeUnit;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyCacheEL {
String prefixKey() default "";
String suffixKey() default "";
long expireTimeMills() default 7L;
TimeUnit unit() default TimeUnit.DAYS;
}
Aspect
import com.fqxiny.aop01.annotation.MyCacheEL;
import jakarta.annotation.Resource;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.core.ParameterNameDiscoverer;
import org.springframework.core.StandardReflectionParameterNameDiscoverer;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.expression.ExpressionParser;
import org.springframework.expression.spel.standard.SpelExpressionParser;
import org.springframework.expression.spel.support.StandardEvaluationContext;
import org.springframework.stereotype.Component;
import org.springframework.util.ObjectUtils;
import java.lang.reflect.Method;
@Aspect
@Component
public class ELCacheAspect {
@Resource
RedisTemplate redisTemplate;
@Resource
RedissonClient redissonClient;
private final ExpressionParser parser = new SpelExpressionParser();
private final StandardEvaluationContext context = new StandardEvaluationContext();
private static final ParameterNameDiscoverer PARAMETER_NAME_DISCOVERER = new StandardReflectionParameterNameDiscoverer();
@Around("@annotation(myCacheEL)")
public Object doAround(ProceedingJoinPoint joinPoint, MyCacheEL myCacheEL) throws Throwable {
// 获取方法签名和参数名
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
Object[] args = joinPoint.getArgs();
// 获取参数名称数组(需要编译时保留 -parameters)
String[] paramNames = PARAMETER_NAME_DISCOVERER.getParameterNames(method);
// 创建 EvaluationContext 并注册参数
StandardEvaluationContext evalContext = new StandardEvaluationContext();
if (paramNames != null && args != null) {
for (int i = 0; i < paramNames.length; i++) {
evalContext.setVariable(paramNames[i], args[i]);
}
}
// 解析 suffixKey 中的 SpEL 表达式(如 #id)
String suffixKey = myCacheEL.suffixKey();
Object suffixValue = parser.parseExpression(suffixKey).getValue(evalContext, Object.class);
// 构造最终缓存 key
String bussinessKey = myCacheEL.prefixKey() + suffixValue;
// 先从缓存取值
Object result = redisTemplate.opsForValue().get(bussinessKey);
if(result != null && ObjectUtils.isEmpty(result)){
return result;
}
// 执行原方法,从数据库取值(先用Redisson加锁)
// 获取分布式锁key
String lockKey= bussinessKey+UUID.randomUUID();
RLock lock = redissonClient.getLock(lockKey);
//除了lock()都不会触发看门狗续期
if(lock.tryLock()){
try {
result = joinPoint.proceed();
redisTemplate.opsForValue().set(bussinessKey, result, myCacheEL.expireTimeMills(), myCacheEL.unit());
return result;
} catch (Throwable e) {
throw new RuntimeException(e);
} finally {
//释放锁
lock.unlock();
}
}else{
//自旋,可能已被放入缓存中。
return this.doAround(joinPoint, myCacheEL);
}
}
}
Redisson源码Mermind图
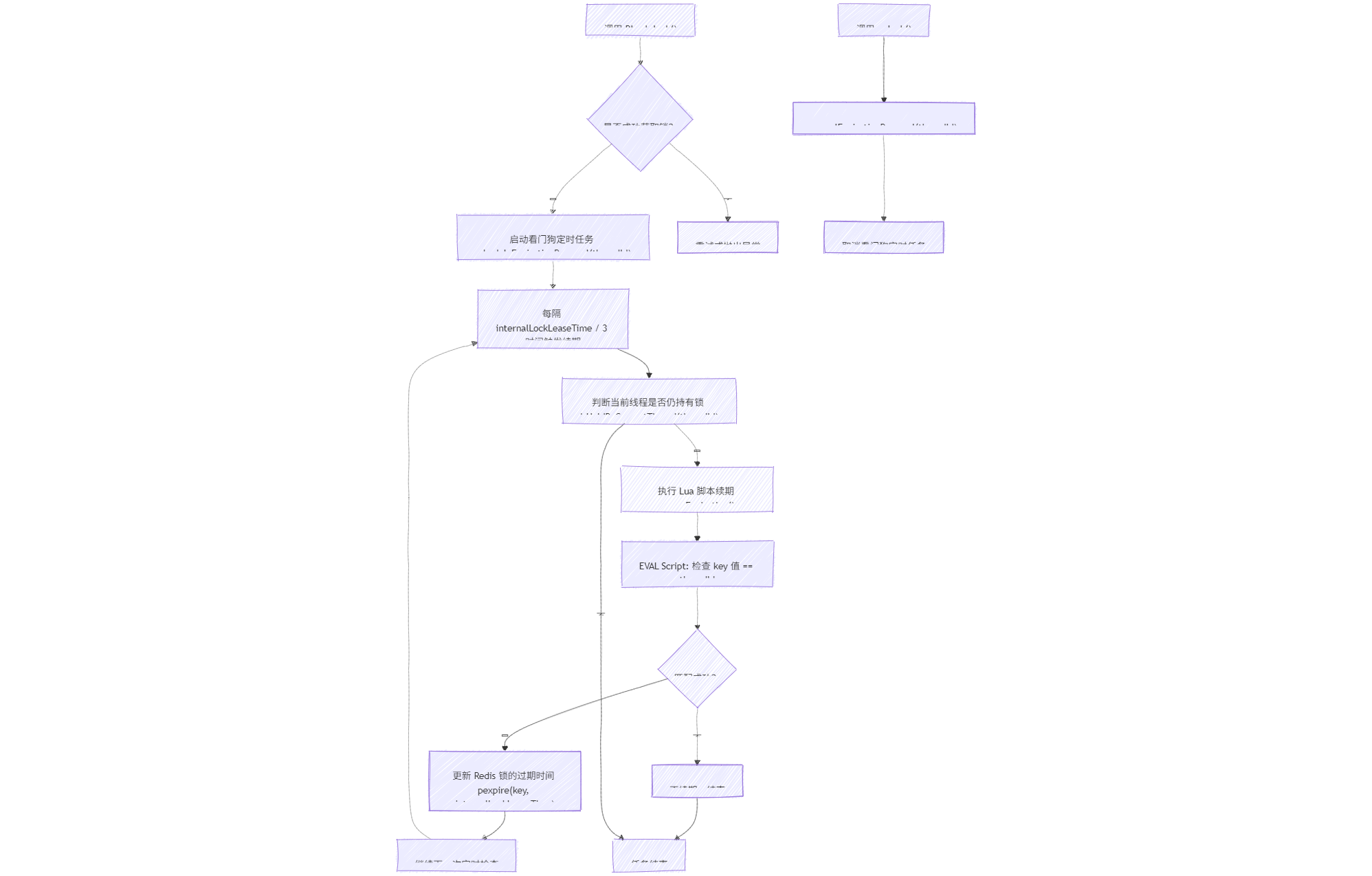
为什么脚本快的同时还能保证原子性?
✅ 为什么脚本能 既快又原子?
🧠 核心原因:Lua 脚本在 Redis 中是单线程原子执行的
Redis 是一个基于 单线程事件循环(Event Loop) 的内存数据库。这意味着:
- 所有命令(包括 Lua 脚本)都是串行执行的;
- 没有多线程并发访问共享资源的问题;
- 因此天然具备 原子性。
同时,因为 Redis 是纯内存操作 + 单线程,没有上下文切换和锁竞争,所以执行速度也非常快。
🔍 举个例子说明“原子性”的重要性
假设我们要实现一个简单的功能:
如果 key
counter存在且小于 10,则自增 1;否则设为 1。
如果用两个命令来做:
GET counter
# 判断是否小于10
INCR counter
在多客户端并发请求时就会出现 竞态条件(Race Condition),比如:
| 时间 | 客户端 A | 客户端 B |
|---|---|---|
| T1 | GET counter = 9 | |
| T2 | GET counter = 9 | |
| T3 | INCR → 10 | INCR → 11 ❌ |
结果变成 11,超过了预期的 10。
但如果使用 Lua 脚本:
local current = redis.call('GET', KEYS[1])
if current and tonumber(current) < 10 then
return redis.call('INCR', KEYS[1])
else
return redis.call('SET', KEYS[1], 1)
end
这个脚本会作为一个整体被 Redis 执行,中间不会被打断,从而保证了 原子性。
🧩 那么脚本为什么还能“快”?
1. 减少网络往返
- 多条命令 → 一次脚本调用
- 减少了网络延迟带来的性能损耗
2. 避免序列化/反序列化
- Redis 命令需要多次解析参数;
- Lua 脚本可以复用,Redis 支持缓存脚本 SHA1 哈希,直接传哈希执行更快。
3. 纯内存操作
- Redis 数据都在内存中,Lua 脚本直接操作内存数据结构;
- 不像传统数据库那样要走磁盘 IO、事务日志等流程。
4. 编译优化
- Redis 内部对 Lua 脚本做了轻量级优化;
- 脚本加载后会被缓存,下次只需传 SHA1。
⚠️ 注意事项:脚本不是万能的!
虽然 Lua 脚本很快也很原子,但你不能滥用:
❗ 不推荐场景:
- 脚本太长或太复杂(会阻塞整个 Redis)
- 执行时间过长(影响其他请求响应)
✅ 推荐场景:
- 原子性操作(如计数器、分布式锁)
- 多命令组合逻辑(避免竞态条件)
- 性能关键路径的小型业务逻辑
📌 总结一句话:
脚本之所以快,是因为它减少了网络通信、绕过了序列化开销,并且直接操作内存数据;而它的原子性则来源于 Redis 的单线程模型,所有脚本都串行执行,不会有并发干扰。


















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











