




业务量突然提升100倍QPS怎么应对?
我们应当早已从项目各个部分做好了充分预案,即使提升100倍也不会冲破系统弹性计算能力,保证系统平稳安全运行。具体优化措施:
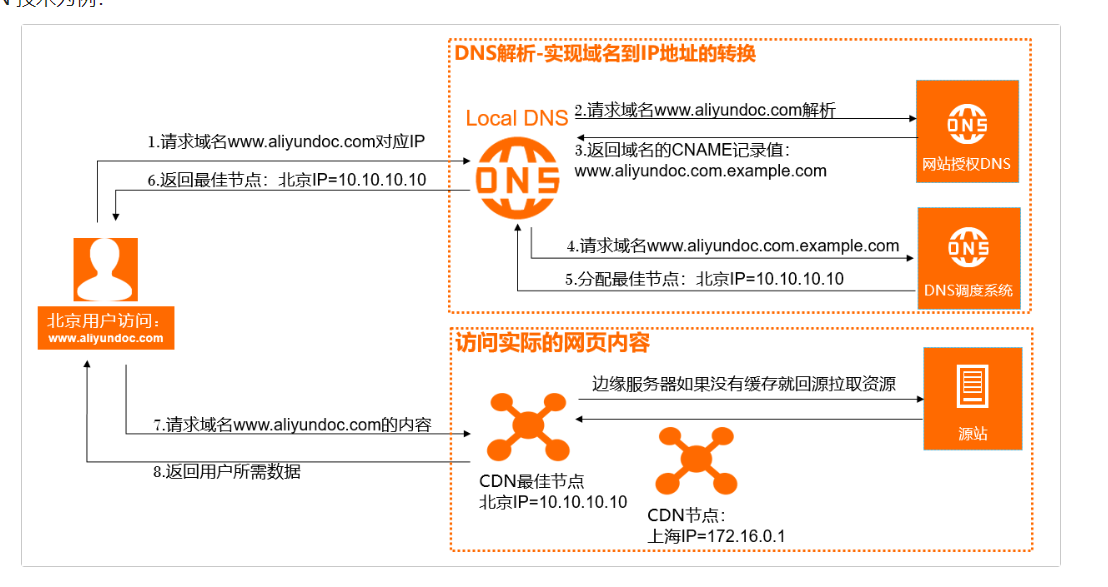
- CDN加速
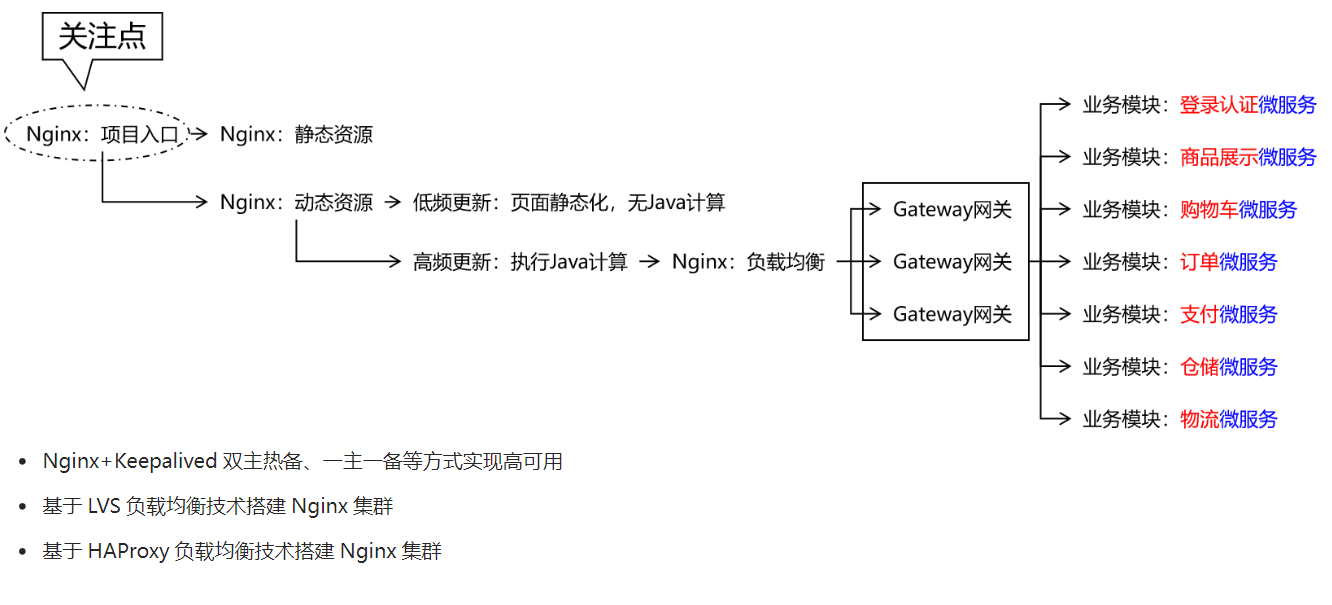
- Nginx服务器保障和优化
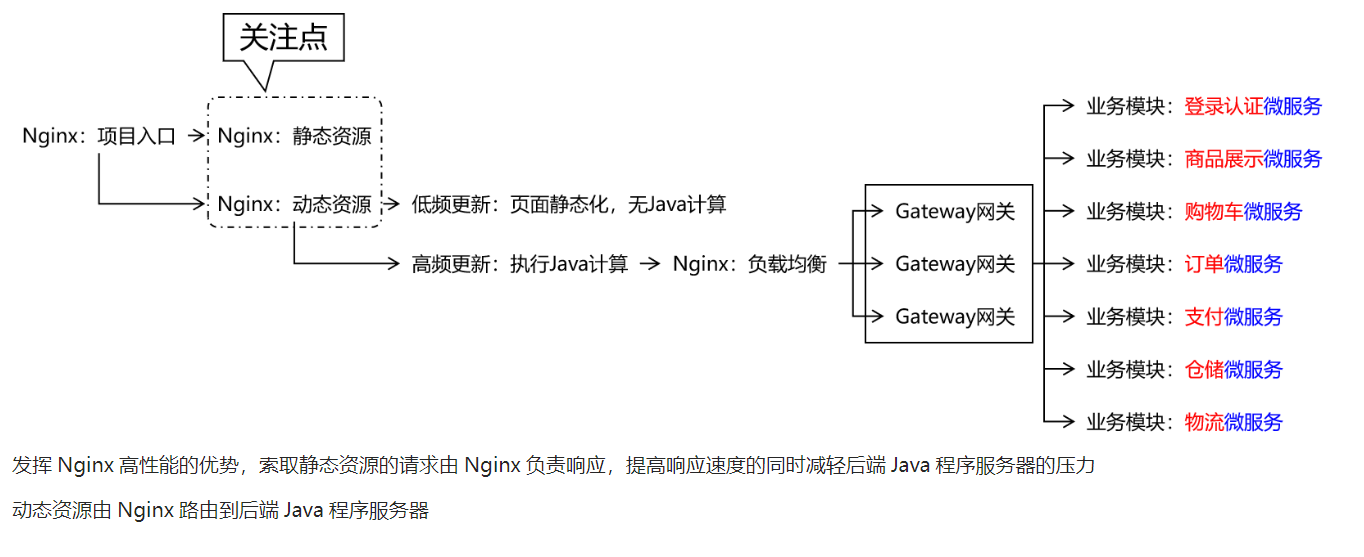
- 业务运算动静分离
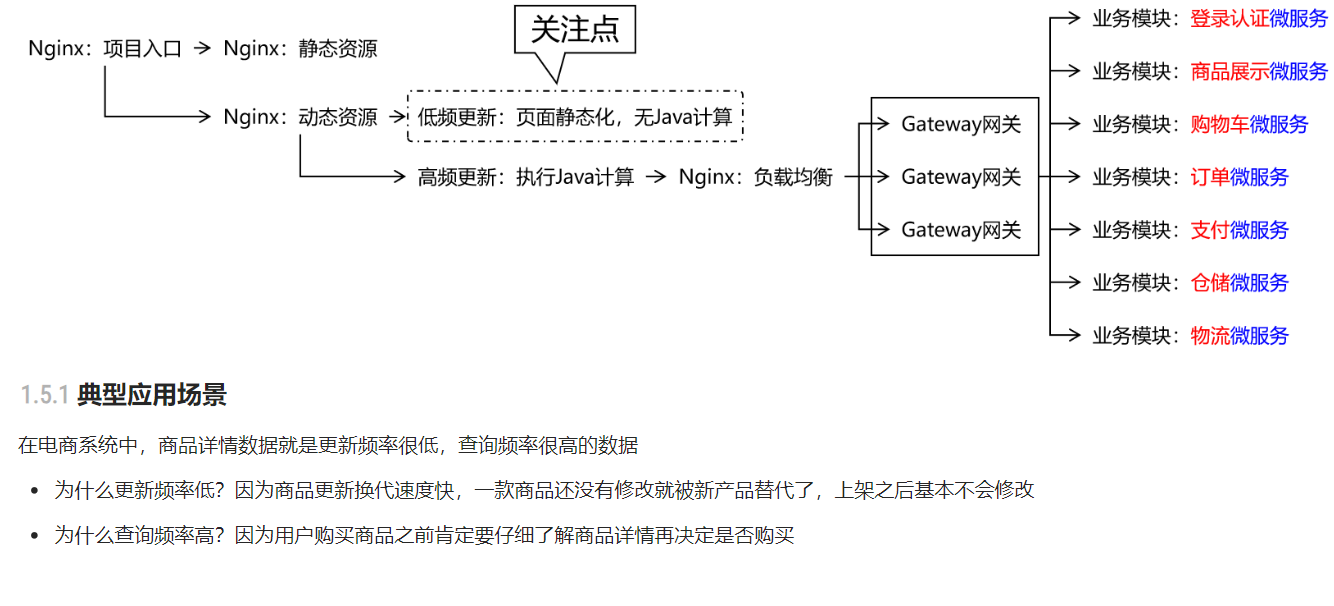
- 动态部分低更新就采用页面静态化(Nginx缓存)
- Gateway网关微服务化配置
- 动态部分高更新就采用动态扩缩容
应对高并发的本质
高并发就是应用服务器线程资源不够用了,导致请求响应变慢,甚至阻塞。那我们需要做的就是提升系统响应时间,增加线程资源。
提升响应时间可以从Redis缓存,页面缓存,本地缓存,线程复用,业务逻辑优化,减少IO,减少上下文切换开销,减少服务调用延迟,CDN加速等几个方面延伸。
总的来说就是从QPS高的请求的调用链路去分析
增加线程资源可以从系统硬件配置,线程池设置,提升实例数量等。
让你设置一个订单号生成服务,怎么做?
订单号的性质:
- 全局唯一
- 速度快
- 不溢出
- 表意性
其实也是分布式ID生成方案的变种,下列是一些参考
参考笔记
8 分布式Id生成方案
8.1 UUID
8.1.1 概念
UUID(Universally Unique Identifier)是一种标准的标识符格式,用于为信息分配唯一的标识符。UUID通常由32个16进制数字构成,分为五个连字符分隔的部分,例如:550e8400-e29b-41d4-a716-446655440000。
8.1.2 UUID的生成算法
- 基于时间的UUID:版本1的UUID主要依赖当前的时间戳及机器的MAC地址来生成。时间值占60位,表示从UTC 1582年10月15日以来的100纳秒间隔计数。时钟序列和节点值分别占14位和48位,用于确保在同一时刻生成的UUID也是唯一的。
- 基于随机数的UUID:版本4的UUID完全基于随机数或伪随机数生成。这种生成方式简单且高效,但需要使用高质量的随机数生成器以确保唯一性。
- 基于名称空间的UUID:版本3和版本5的UUID是基于名称空间和名称的散列值生成的。版本3使用MD5散列算法,而版本5使用SHA-1散列算法。这些UUID在不同的命名空间和名称下是唯一的。
8.1.3 优点
- 唯一性:
- UUID基于时间和机器MAC地址(对于版本1的UUID)或其他因素(如随机数或散列值,对于其他版本的UUID)生成,几乎可以保证全球唯一。
- 简单易用:
- UUID的生成过程相对简单,不需要复杂的配置或额外的组件支持。大多数编程语言都提供了内置的库来生成UUID。
- 本地生成:
- UUID可以在本地生成,无需通过网络请求或依赖外部服务,因此没有网络消耗,且生成速度快。
8.1.4 缺点
- 长度过长:
- UUID通常由36个字符组成(包括4个连字符),长度较长,不适合作为数据库主键或需要短ID的应用场景。
- 无序性:
- UUID是无序的字符串,不具备趋势自增特性,这在某些需要有序ID的场景下可能是一个问题。
- 查询效率低:
- 由于UUID的无序性和长度,其在数据库中的查询效率相对较低,尤其是在大量数据的情况下。
- 信息泄露风险:
- 基于MAC地址生成的UUID可能会暴露生成该UUID的机器的MAC地址,从而引发信息泄露的风险。
- 存储成本高:
- 由于UUID的长度较长,其存储成本相对较高,尤其是在需要存储大量UUID的系统中。
综上所述,UUID作为分布式ID生成方案,在唯一性、简单易用和本地生成方面具有显著优势,但也存在长度过长、无序性、查询效率低、信息泄露风险和存储成本高等缺点。在选择是否使用UUID作为分布式ID生成方案时,需要根据实际需求和场景进行权衡。
8.2 数据库自增序列
8.2.1 单机模式
8.2.1.1 优点
- 实现简单,依靠数据库即可,成本小。
- ID数字化,单调自增,满足数据库存储和查询性能。
- 具有一定的业务可读性。(结合业务代码)
8.2.1.2 缺点
- 强依赖DB,存在单点问题,如果数据库宕机,则业务不可用。
- DB生成ID性能有限,单点数据库压力大,无法扛高并发场景。
- 信息安全问题,比如暴露订单量,url查询改一下id查到别人的订单
- 分布式下生成的id会重复
8.2.2 集群模式(数据库高可用背景下)
8.2.2.1 方案描述
具体操作方案是:多主模式做负载均衡,基于序列的起始值和步长设置,不同的初始值,相同的步长,步长大于等于节点数。例如:
| 初始值 | 步长 | 一步 | 两步 | 三步 | …… |
|---|---|---|---|---|---|
| 1 | 3 | 4 | 7 | 10 | …… |
| 2 | 3 | 5 | 8 | 11 | …… |
| 3 | 3 | 6 | 9 | 12 | …… |
8.2.2.2 优点
- 解决了ID生成的单点问题,同时平衡了负载。
- 解决了分布式环境下id重复问题。
8.2.2.3 缺点
- 系统扩容困难:系统定义好步长之后,增加机器之后调整步长困难。
- 主从同步延迟:向master写入数据后,再select查询有可能因为同步延迟导致查询不到
8.3 基于Redis、MongoDB、ZooKeeper等中间件生成
8.3.1 一、Redis
- 优点
- 高性能:Redis作为内存数据库,读写速度非常快,能够提供高效的ID生成服务。
- 唯一性保证:Redis支持原子操作如INCR,可以确保ID的唯一性和顺序递增。
- 灵活性:可以根据业务需求自定义ID生成规则,如引入时间、随机数等元素。
- 持久化:支持持久化选项,可以保证生成的ID在Redis重启后不丢失。
- 缺点
- 依赖组件:如果系统中没有Redis,需要额外引入并配置该组件,增加了系统复杂度。
- 编码配置量大:实现过程中需要编写较多的代码并进行相应的配置。
- 单节点性能瓶颈:虽然Redis本身是分布式系统,但单节点的性能可能成为瓶颈,需要考虑使用Redis集群来提高吞吐量。
8.3.2 二、MongoDB
- 优点
- ObjectId生成机制:MongoDB自带的ObjectId生成机制简单易用,且能保证全局唯一性。
- 趋势递增:ObjectId中的时间戳部分使得ID具有趋势递增的特性。
- 无需额外组件:对于已经使用MongoDB的系统来说,无需额外引入组件即可实现分布式ID生成。
- 缺点
- 长度较长:ObjectId的长度较长,可能不适合对ID长度有严格要求的场景。
- 无序性问题:在某些特定场景下,可能需要对ObjectId进行转换或处理以满足有序性要求。
8.3.3 三、ZooKeeper(ZK)
- 优点
- 高可用性:ZooKeeper作为一个分布式协调服务,具有高可用性和稳定性。
- 临时节点特性:利用ZooKeeper的临时节点特性,可以实现分布式ID的生成和管理。
- 灵活的ID生成策略:可以根据业务需求自定义ID生成策略,如引入时间、机器标识等信息。
- 缺点
- 依赖组件:与Redis类似,如果系统中没有ZooKeeper,需要额外引入并配置该组件。
- 性能问题:在高并发场景下,ZooKeeper的性能可能成为瓶颈,需要考虑优化策略。
- 实现复杂:相比其他中间件,ZooKeeper的ID生成实现可能更为复杂,需要编写更多的代码和配置。
综上所述,基于Redis、MongoDB、ZooKeeper等中间件生成分布式ID的方案各有优劣。在选择具体方案时,需要根据实际业务需求、系统架构以及团队技术栈等因素进行综合考虑。
8.4 雪花算法
雪花算法(Snowflake)是一种分布式ID生成算法,其生成机制和优缺点具体如下:
8.4.1 生成机制
- 基本结构:雪花算法生成的ID是一个64位的long型数值,主要分为四个部分。
- 1位符号位:始终为0,因为生成的ID是正数。
- 41位时间戳:记录当前时间与某个固定时间的差值(通常是系统开始运行的时间),以毫秒为单位。这41位可以表示约69年的时间范围。
- 10位机器标识:包括5位数据中心ID和5位机器ID,用于区分不同的节点。最多可以部署在1024个节点上。
- 12位序列号:用于确保在同一毫秒内生成的ID是唯一的。每毫秒可生成4096个不重复的ID。
- 生成过程:在生成ID时,首先获取当前的时间戳。如果当前时间戳与上次生成ID的时间戳相同,则序列号加1;否则,序列号置为0,并更新时间戳。最后,将时间戳、机器标识和序列号组合成64位的长整型值,形成一个唯一的ID。
8.4.2 优点
- 高并发性能:在高并发环境下,每秒可生成百万级别的不重复ID。
- 唯一性保证:通过结合时间戳、机器ID和序列号,可以确保生成的ID在分布式系统中的唯一性。
- 趋势递增:基于时间戳生成ID,可以保证ID的基本有序递增,满足某些业务场景的需求。
- 灵活性:可以根据需要自定义ID结构,如调整时间戳、机器标识和序列号的位数。
8.4.3 缺点
- 依赖服务器时间:生成的ID依赖于服务器的时钟,如果服务器时钟回拨或不同机器之间的时钟不同步,可能会导致生成重复的ID。
- 有限的并发性:虽然雪花算法支持高并发,但在极端情况下仍可能出现并发问题。
综上所述,雪花算法是一种高效、可靠的分布式ID生成算法,适用于大规模分布式系统。然而,由于其依赖服务器时间的特性,需要在实际应用中注意时钟同步和回拨问题。
4 负载均衡算法、类型
4.1 算法
4.1.1 轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
4.1.2 随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
4.1.3 源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
4.1.4 加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
4.1.5 加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
4.1.6 最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
4.2 类型
1、DNS 方式实现负载均衡
2、硬件负载均衡:F5 和 A10
3、软件负载均衡:Nginx 、 HAproxy 、 LVS
4.3 产品落地
- Nginx :七层负载均衡,支持 HTTP、E-mail 协议,同时也支持 4 层负载均衡;
- HAproxy :支持七层规则的,性能也很不错。OpenStack 默认使用的负载均衡软件就是HAproxy;
- LVS :运行在内核态,性能是软件负载均衡中最高的,严格来说工作在三层,所以更通用一些,适用各种应用服务。


















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











